 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Tracking Easy: Neural Motion Retargeting for Humanoid Whole-body Control
Mar 23, 2026Humanoid robots require diverse motor skills to integrate into complex environments, but bridging the kinematic and dynamic embodiment gap from human data remains a major bottleneck. We demonstrate through Hessian analysis that traditional optimization-based retargeting is inherently non-convex and prone to local optima, leading to physical artifacts like joint jumps and self-penetration. To address this, we reformulate the targeting problem as learning data distribution rather than optimizing optimal solutions, where we propose NMR, a Neural Motion Retargeting framework that transforms static geometric mapping into a dynamics-aware learned process. We first propose Clustered-Expert Physics Refinement (CEPR), a hierarchical data pipeline that leverages VAE-based motion clustering to group heterogeneous movements into latent motifs. This strategy significantly reduces the computational overhead of massively parallel reinforcement learning experts, which project and repair noisy human demonstrations onto the robot's feasible motion manifold. The resulting high-fidelity data supervises a non-autoregressive CNN-Transformer architecture that reasons over global temporal context to suppress reconstruction noise and bypass geometric traps. Experiments on the Unitree G1 humanoid across diverse dynamic tasks (e.g., martial arts, dancing) show that NMR eliminates joint jumps and significantly reduces self-collisions compared to state-of-the-art baselines. Furthermore, NMR-generated references accelerate the convergence of downstream whole-body control policies, establishing a scalable path for bridging the human-robot embodiment gap.
Personality-guided Public-Private Domain Disentangled Hypergraph-Former Network for Multimodal Depression Detection
Nov 16, 2025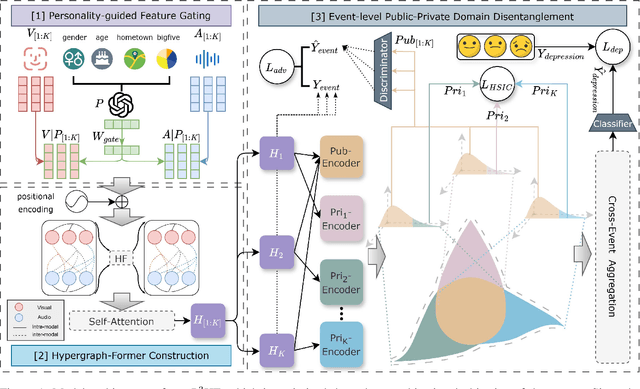
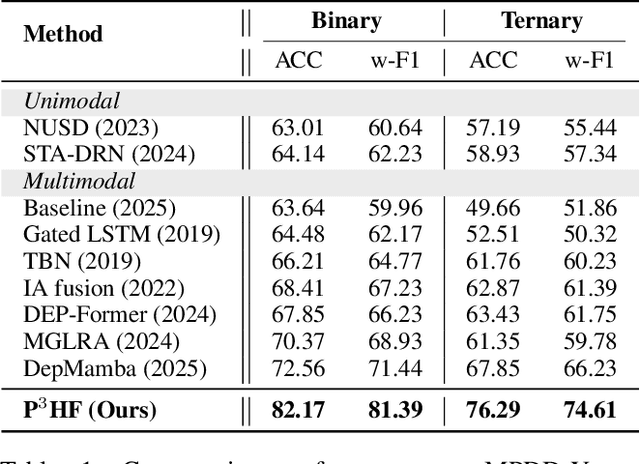
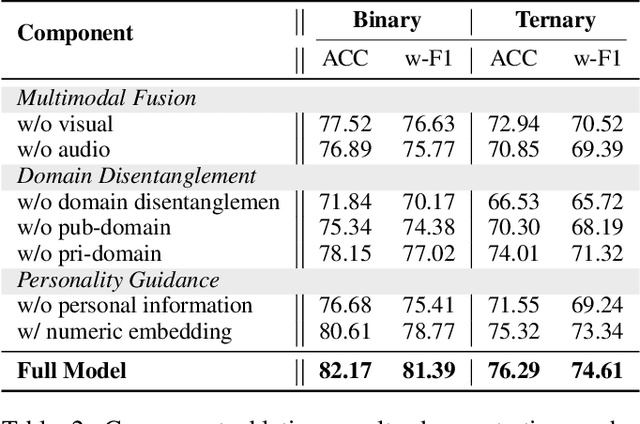
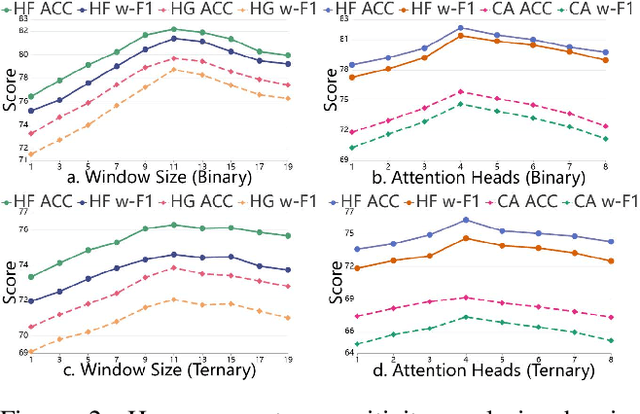
Depression represents a global mental health challenge requiring efficient and reliable automated detection methods. Current Transformer- or Graph Neural Networks (GNNs)-based multimodal depression detection methods face significant challenges in modeling individual differences and cross-modal temporal dependencies across diverse behavioral contexts. Therefore, we propose P$^3$HF (Personality-guided Public-Private Domain Disentangled Hypergraph-Former Network) with three key innovations: (1) personality-guided representation learning using LLMs to transform discrete individual features into contextual descriptions for personalized encoding; (2) Hypergraph-Former architecture modeling high-order cross-modal temporal relationships; (3) event-level domain disentanglement with contrastive learning for improved generalization across behavioral contexts. Experiments on MPDD-Young dataset show P$^3$HF achieves around 10\% improvement on accuracy and weighted F1 for binary and ternary depression classification task over existing methods. Extensive ablation studies validate the independent contribution of each architectural component, confirming that personality-guided representation learning and high-order hypergraph reasoning are both essential for generating robust, individual-aware depression-related representations. The code is released at https://github.com/hacilab/P3HF.
Neuro-MoBRE: Exploring Multi-subject Multi-task Intracranial Decoding via Explicit Heterogeneity Resolving
Aug 06, 2025Neurophysiological decoding, fundamental to advancing brain-computer interface (BCI) technologies, has significantly benefited from recent advances in deep learning. However, existing decoding approaches largely remain constrained to single-task scenarios and individual subjects, limiting their broader applicability and generalizability. Efforts towards creating large-scale neurophysiological foundation models have shown promise, but continue to struggle with significant challenges due to pervasive data heterogeneity across subjects and decoding tasks. Simply increasing model parameters and dataset size without explicitly addressing this heterogeneity fails to replicate the scaling successes seen in natural language processing. Here, we introduce the Neural Mixture of Brain Regional Experts (Neuro-MoBRE), a general-purpose decoding framework explicitly designed to manage the ubiquitous data heterogeneity in neurophysiological modeling. Neuro-MoBRE incorporates a brain-regional-temporal embedding mechanism combined with a mixture-of-experts approach, assigning neural signals from distinct brain regions to specialized regional experts on a unified embedding basis, thus explicitly resolving both structural and functional heterogeneity. Additionally, our region-masked autoencoding pre-training strategy further enhances representational consistency among subjects, complemented by a task-disentangled information aggregation method tailored to effectively handle task-specific neural variations. Evaluations conducted on intracranial recordings from 11 subjects across five diverse tasks, including complex language decoding and epileptic seizure diagnosis, demonstrate that Neuro-MoBRE surpasses prior art and exhibits robust generalization for zero-shot decoding on unseen subjects.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
GelFusion: Enhancing Robotic Manipulation under Visual Constraints via Visuotactile Fusion
May 12, 2025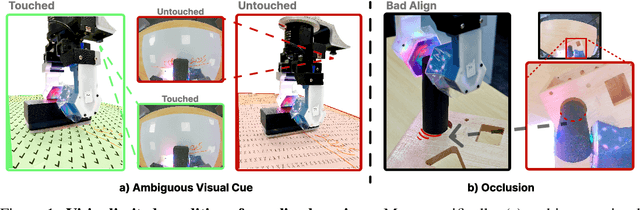
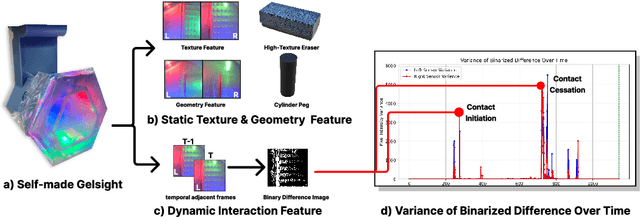
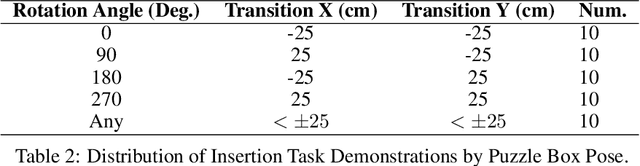
Visuotactile sensing offers rich contact information that can help mitigate performance bottlenecks in imitation learning, particularly under vision-limited conditions, such as ambiguous visual cues or occlusions. Effectively fusing visual and visuotactile modalities, however, presents ongoing challenges. We introduce GelFusion, a framework designed to enhance policies by integrating visuotactile feedback, specifically from high-resolution GelSight sensors. GelFusion using a vision-dominated cross-attention fusion mechanism incorporates visuotactile information into policy learning. To better provide rich contact information, the framework's core component is our dual-channel visuotactile feature representation, simultaneously leveraging both texture-geometric and dynamic interaction features. We evaluated GelFusion on three contact-rich tasks: surface wiping, peg insertion, and fragile object pick-and-place. Outperforming baselines, GelFusion shows the value of its structure in improving the success rate of policy learning.
General Place Recognition Survey: Towards Real-World Autonomy
May 08, 2024



In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community's remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics. This paper begins with an exploration of PR's formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR's potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR's future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
MUI-TARE: Multi-Agent Cooperative Exploration with Unknown Initial Position
Sep 22, 2022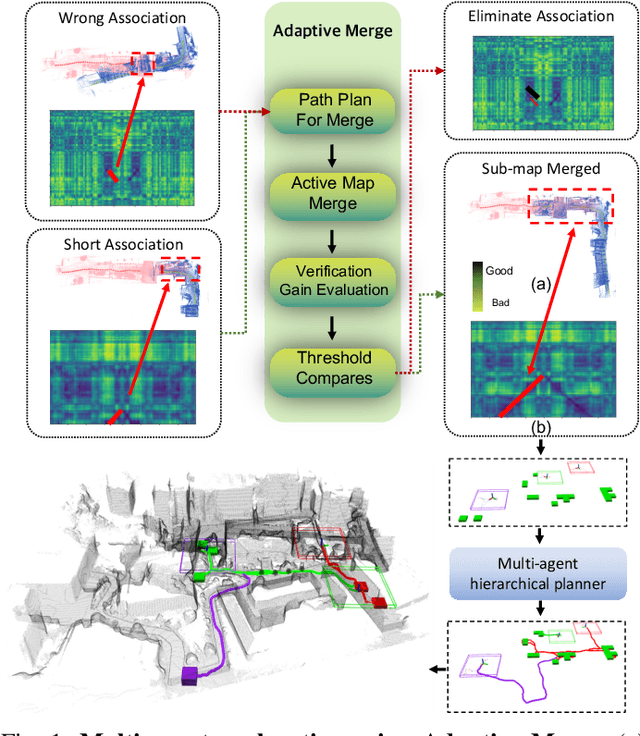
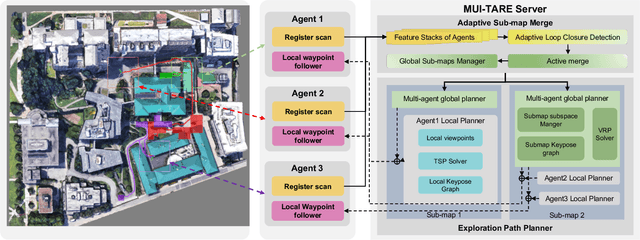
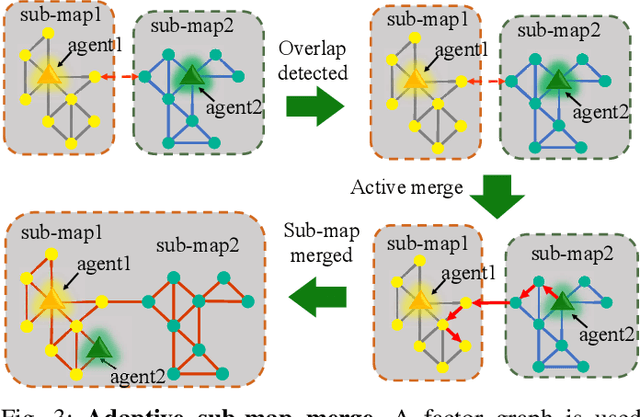
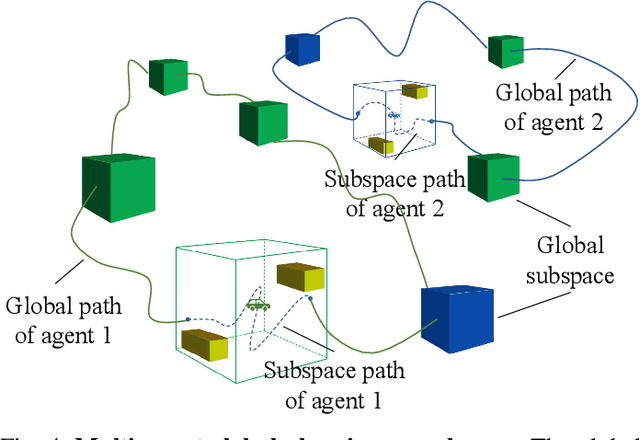
Multi-agent exploration of a bounded 3D environment with unknown initial positions of agents is a challenging problem. It requires quickly exploring the environments as well as robustly merging the sub-maps built by the agents. We take the view that the existing approaches are either aggressive or conservative: Aggressive strategies merge two sub-maps built by different agents together when overlap is detected, which can lead to incorrect merging due to the false-positive detection of the overlap and is thus not robust. Conservative strategies direct one agent to revisit an excessive amount of the historical trajectory of another agent for verification before merging, which can lower the exploration efficiency due to the repeated exploration of the same space. To intelligently balance the robustness of sub-map merging and exploration efficiency, we develop a new approach for lidar-based multi-agent exploration, which can direct one agent to repeat another agent's trajectory in an \emph{adaptive} manner based on the quality indicator of the sub-map merging process. Additionally, our approach extends the recent single-agent hierarchical exploration strategy to multiple agents in a \emph{cooperative} manner by planning for agents with merged sub-maps together to further improve exploration efficiency. Our experiments show that our approach is up to 50\% more efficient than the baselines on average while merging sub-maps robustly.
General Place Recognition Survey: Towards the Real-world Autonomy Age
Sep 09, 2022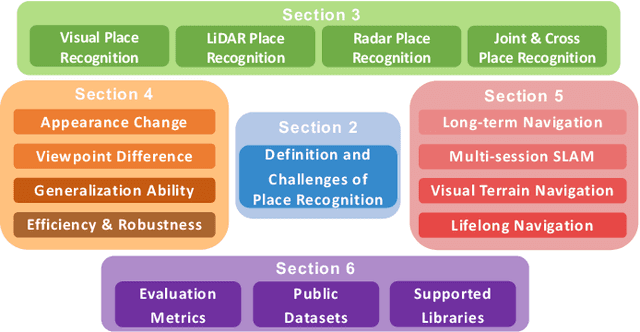
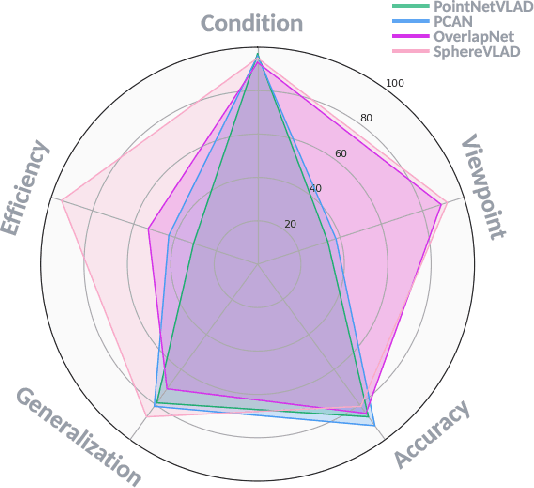

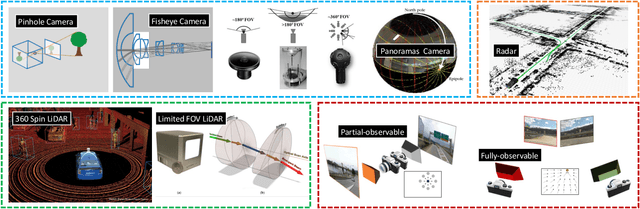
Place recognition is the fundamental module that can assist Simultaneous Localization and Mapping (SLAM) in loop-closure detection and re-localization for long-term navigation. The place recognition community has made astonishing progress over the last $20$ years, and this has attracted widespread research interest and application in multiple fields such as computer vision and robotics. However, few methods have shown promising place recognition performance in complex real-world scenarios, where long-term and large-scale appearance changes usually result in failures. Additionally, there is a lack of an integrated framework amongst the state-of-the-art methods that can handle all of the challenges in place recognition, which include appearance changes, viewpoint differences, robustness to unknown areas, and efficiency in real-world applications. In this work, we survey the state-of-the-art methods that target long-term localization and discuss future directions and opportunities. We start by investigating the formulation of place recognition in long-term autonomy and the major challenges in real-world environments. We then review the recent works in place recognition for different sensor modalities and current strategies for dealing with various place recognition challenges. Finally, we review the existing datasets for long-term localization and introduce our datasets and evaluation API for different approaches. This paper can be a tutorial for researchers new to the place recognition community and those who care about long-term robotics autonomy. We also provide our opinion on the frequently asked question in robotics: Do robots need accurate localization for long-term autonomy? A summary of this work and our datasets and evaluation API is publicly available to the robotics community at: https://github.com/MetaSLAM/GPRS.
BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition
Aug 30, 2022
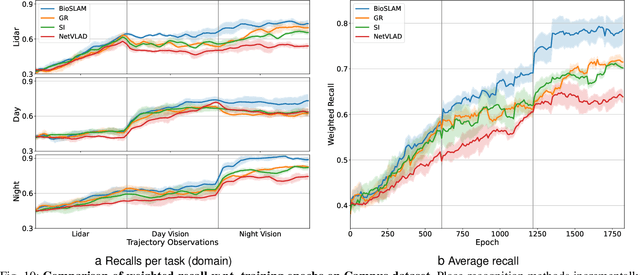
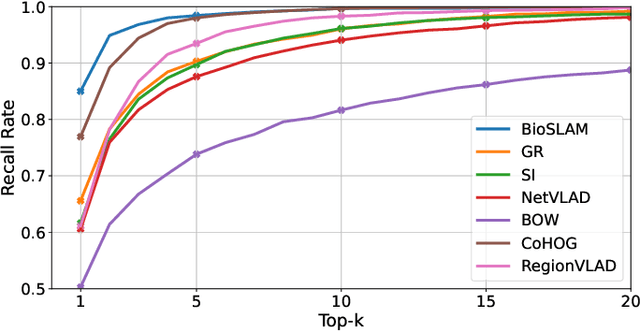
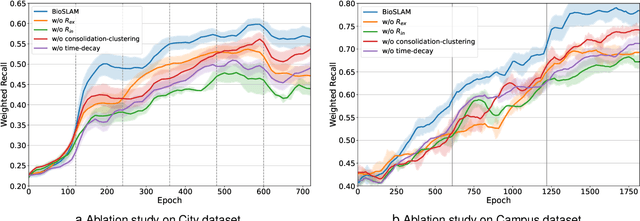
We present BioSLAM, a lifelong SLAM framework for learning various new appearances incrementally and maintaining accurate place recognition for previously visited areas. Unlike humans, artificial neural networks suffer from catastrophic forgetting and may forget the previously visited areas when trained with new arrivals. For humans, researchers discover that there exists a memory replay mechanism in the brain to keep the neuron active for previous events. Inspired by this discovery, BioSLAM designs a gated generative replay to control the robot's learning behavior based on the feedback rewards. Specifically, BioSLAM provides a novel dual-memory mechanism for maintenance: 1) a dynamic memory to efficiently learn new observations and 2) a static memory to balance new-old knowledge. When combined with a visual-/LiDAR- based SLAM system, the complete processing pipeline can help the agent incrementally update the place recognition ability, robust to the increasing complexity of long-term place recognition. We demonstrate BioSLAM in two incremental SLAM scenarios. In the first scenario, a LiDAR-based agent continuously travels through a city-scale environment with a 120km trajectory and encounters different types of 3D geometries (open streets, residential areas, commercial buildings). We show that BioSLAM can incrementally update the agent's place recognition ability and outperform the state-of-the-art incremental approach, Generative Replay, by 24%. In the second scenario, a LiDAR-vision-based agent repeatedly travels through a campus-scale area on a 4.5km trajectory. BioSLAM can guarantee the place recognition accuracy to outperform 15\% over the state-of-the-art approaches under different appearances. To our knowledge, BioSLAM is the first memory-enhanced lifelong SLAM system to help incremental place recognition in long-term navigation tasks.
AutoMerge: A Framework for Map Assembling and Smoothing in City-scale Environments
Jul 14, 2022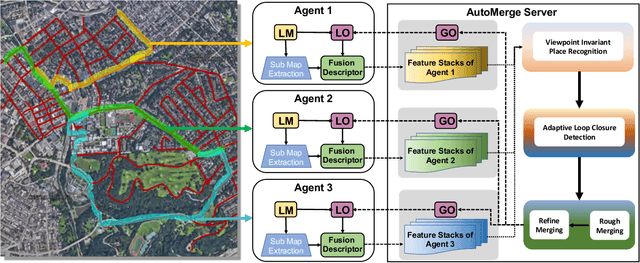
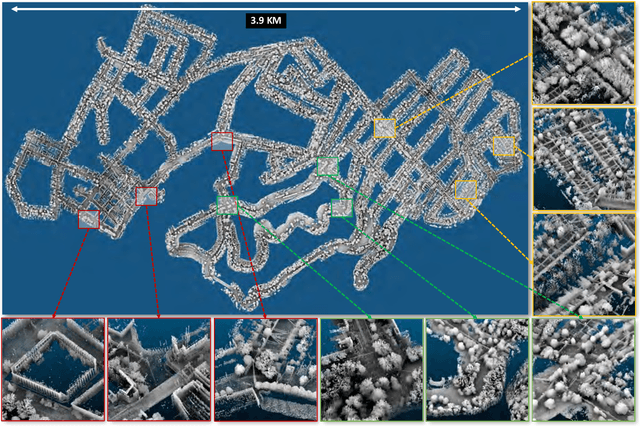
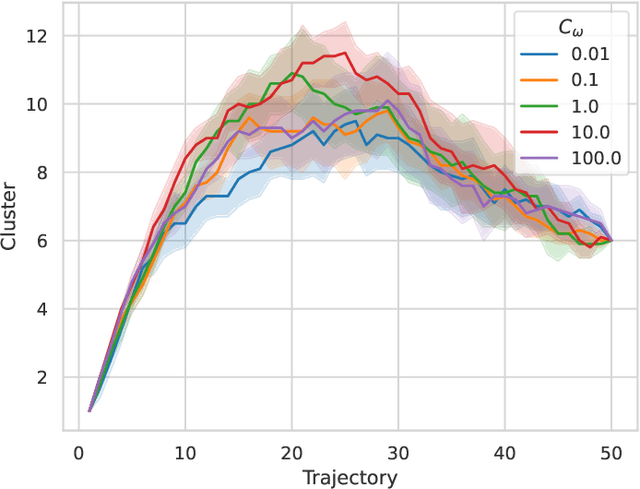
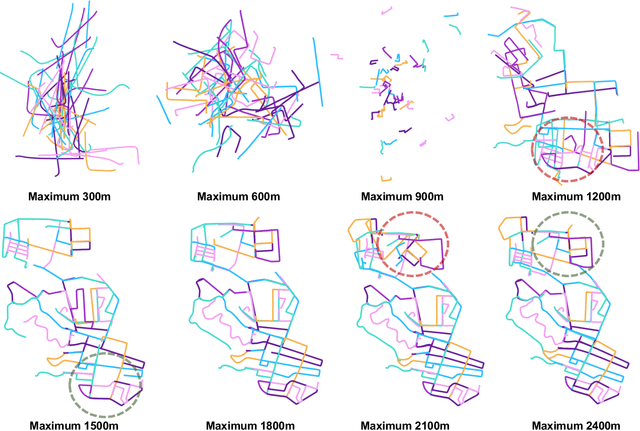
We present AutoMerge, a LiDAR data processing framework for assembling a large number of map segments into a complete map. Traditional large-scale map merging methods are fragile to incorrect data associations, and are primarily limited to working only offline. AutoMerge utilizes multi-perspective fusion and adaptive loop closure detection for accurate data associations, and it uses incremental merging to assemble large maps from individual trajectory segments given in random order and with no initial estimations. Furthermore, after assembling the segments, AutoMerge performs fine matching and pose-graph optimization to globally smooth the merged map. We demonstrate AutoMerge on both city-scale merging (120km) and campus-scale repeated merging (4.5km x 8). The experiments show that AutoMerge (i) surpasses the second- and third- best methods by 14% and 24% recall in segment retrieval, (ii) achieves comparable 3D mapping accuracy for 120 km large-scale map assembly, (iii) and it is robust to temporally-spaced revisits. To the best of our knowledge, AutoMerge is the first mapping approach that can merge hundreds of kilometers of individual segments without the aid of GPS.