 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphereVLAD++: Attention-based and Signal-enhanced Viewpoint Invariant Descriptor
Jul 06, 2022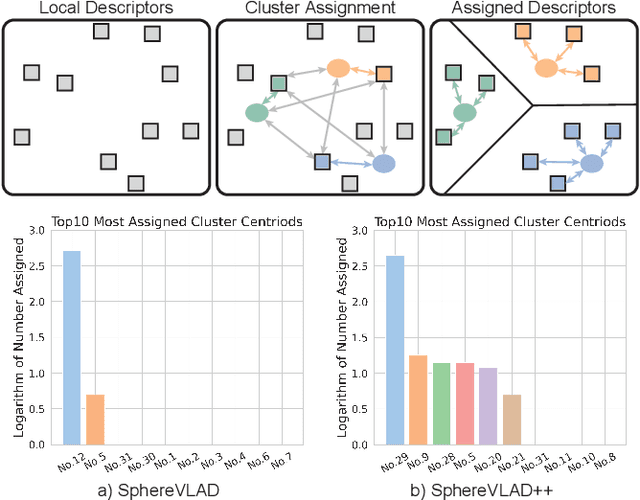
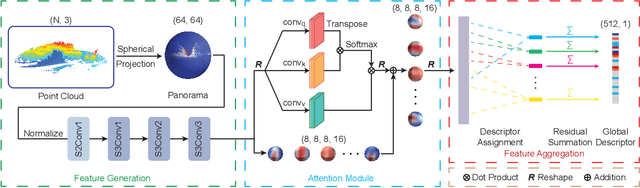
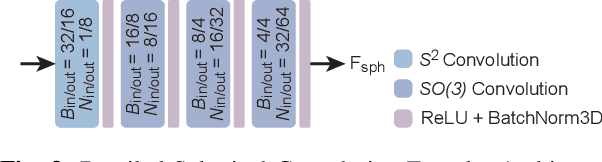
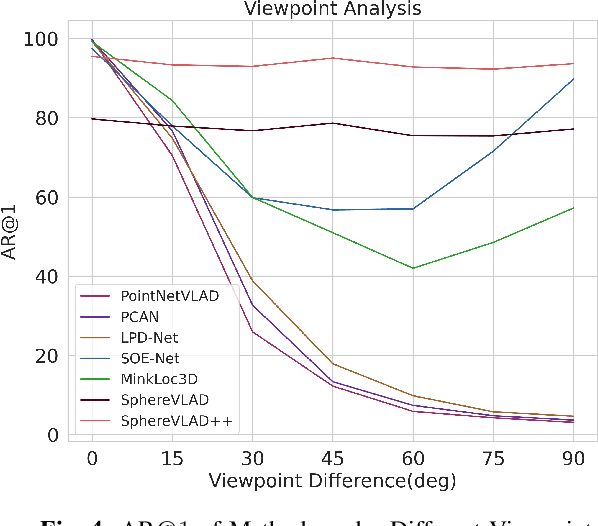
LiDAR-based localization approach is a fundamental module for large-scale navigation tasks, such as last-mile delivery and autonomous driving, and localization robustness highly relies on viewpoints and 3D feature extraction. Our previous work provides a viewpoint-invariant descriptor to deal with viewpoint differences; however, the global descriptor suffers from a low signal-noise ratio in unsupervised clustering, reducing the distinguishable feature extraction ability. We develop SphereVLAD++, an attention-enhanced viewpoint invariant place recognition method in this work. SphereVLAD++ projects the point cloud on the spherical perspective for each unique area and captures the contextual connections between local features and their dependencies with global 3D geometry distribution. In return, clustered elements within the global descriptor are conditioned on local and global geometries and support the original viewpoint-invariant property of SphereVLAD. In the experiments, we evaluated the localization performance of SphereVLAD++ on both public KITTI360 datasets and self-generated datasets from the city of Pittsburgh. The experiment results show that SphereVLAD++ outperforms all relative state-of-the-art 3D place recognition methods under small or even totally reversed viewpoint differences and shows 0.69% and 15.81% successful retrieval rates with better than the second best. Low computation requirements and high time efficiency also help its application for low-cost robots.