 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Point Cloud Completion with Pose Disturbance
Paper and Code
Feb 07, 2022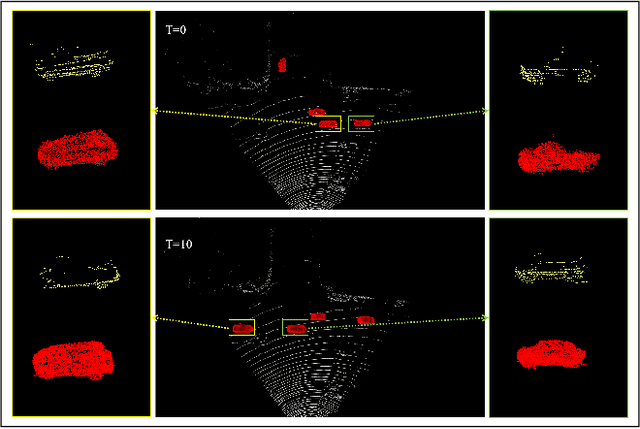
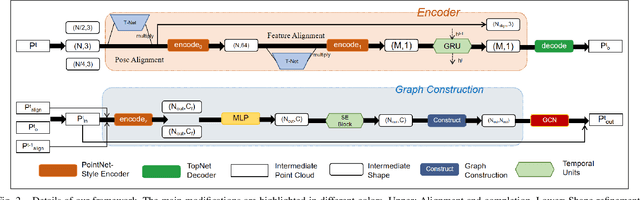
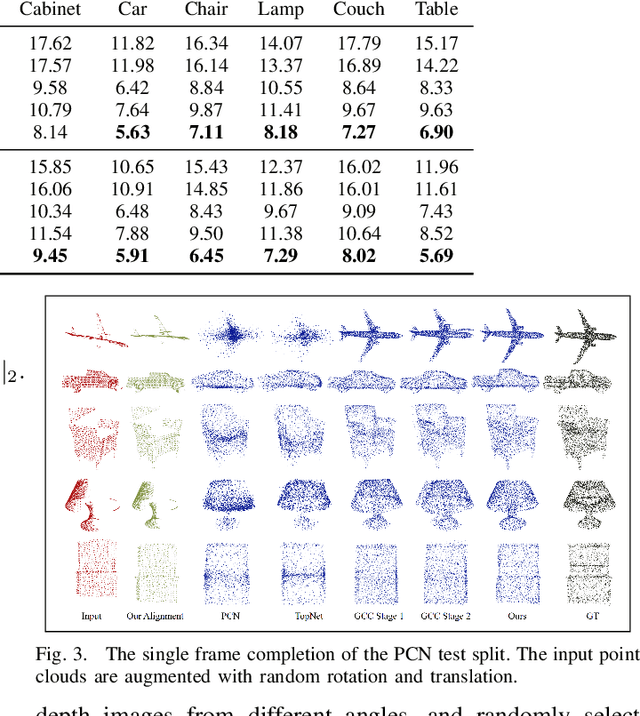
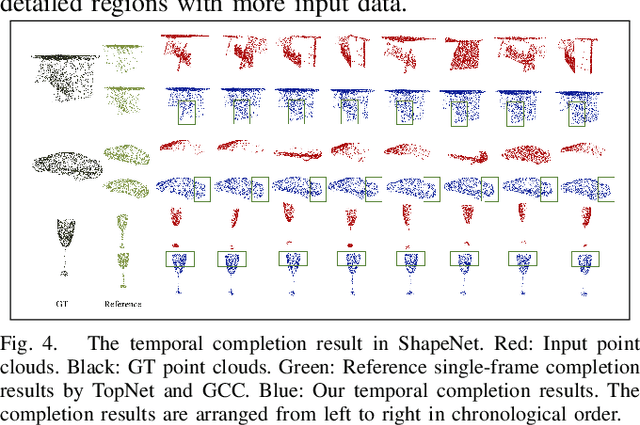
Point clouds collected by real-world sensors are always unaligned and sparse, which makes it hard to reconstruct the complete shape of object from a single frame of data. In this work, we manage to provide complete point clouds from sparse input with pose disturbance by limited translation and rotation. We also use temporal information to enhance the completion model, refining the output with a sequence of inputs. With the help of gated recovery units(GRU) and attention mechanisms as temporal units, we propose a point cloud completion framework that accepts a sequence of unaligned and sparse inputs, and outputs consistent and aligned point clouds. Our network performs in an online manner and presents a refined point cloud for each frame, which enables it to be integrated into any SLAM or reconstruction pipeline. As far as we know, our framework is the first to utilize temporal information and ensure temporal consistency with limited transformation. Through experiments in ShapeNet and KITTI, we prove that our framework is effective in both synthetic and real-world datasets.