 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiLong-Shot: Interaction-Aware One-Shot Imitation Learning for Long-Horizon Manipulation
Dec 18, 2025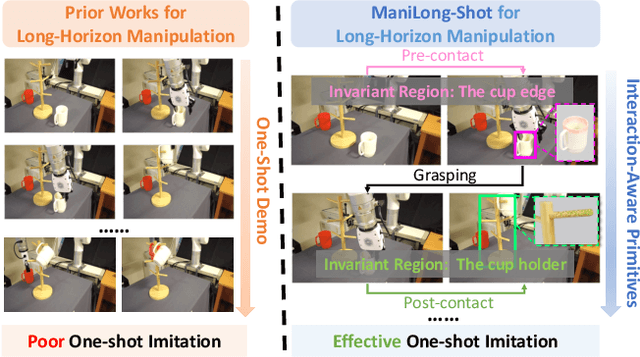

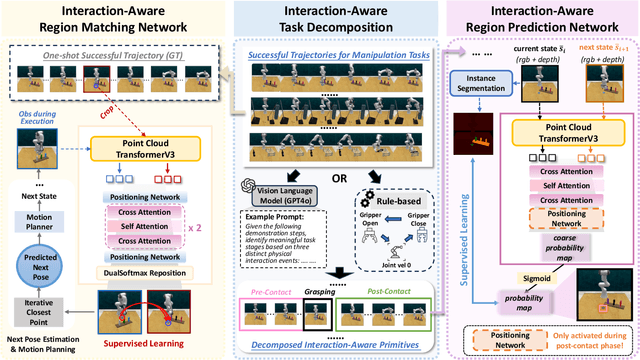
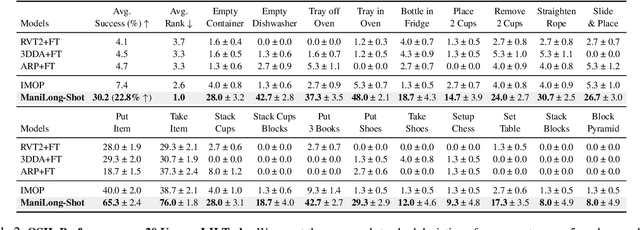
One-shot imitation learning (OSIL) offers a promising way to teach robots new skills without large-scale data collection. However, current OSIL methods are primarily limited to short-horizon tasks, thus limiting their applicability to complex, long-horizon manipulations. To address this limitation, we propose ManiLong-Shot, a novel framework that enables effective OSIL for long-horizon prehensile manipulation tasks. ManiLong-Shot structures long-horizon tasks around physical interaction events, reframing the problem as sequencing interaction-aware primitives instead of directly imitating continuous trajectories. This primitive decomposition can be driven by high-level reasoning from a vision-language model (VLM) or by rule-based heuristics derived from robot state changes. For each primitive, ManiLong-Shot predicts invariant regions critical to the interaction, establishes correspondences between the demonstration and the current observation, and computes the target end-effector pose, enabling effective task execution. Extensive simulation experiments show that ManiLong-Shot, trained on only 10 short-horizon tasks, generalizes to 20 unseen long-horizon tasks across three difficulty levels via one-shot imitation, achieving a 22.8% relative improvement over the SOTA. Additionally, real-robot experiments validate ManiLong-Shot's ability to robustly execute three long-horizon manipulation tasks via OSIL, confirming its practical applicability.
SEPT: Standard-Definition Map Enhanced Scene Perception and Topology Reasoning for Autonomous Driving
May 18, 2025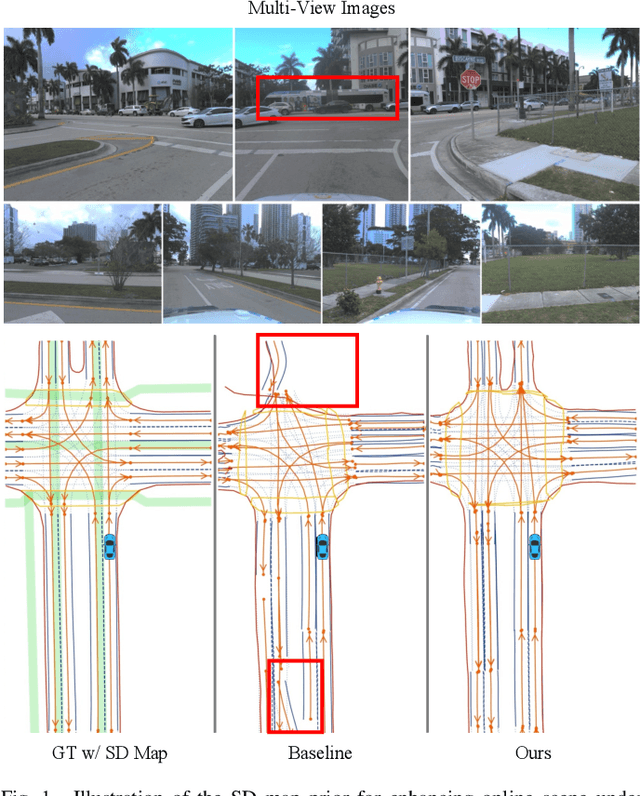
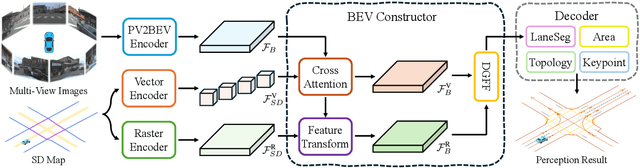
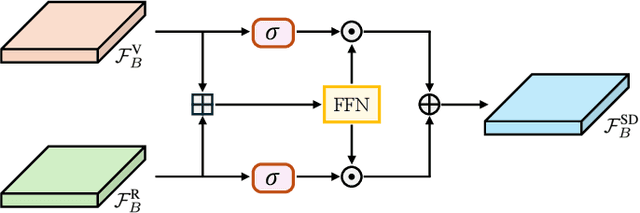
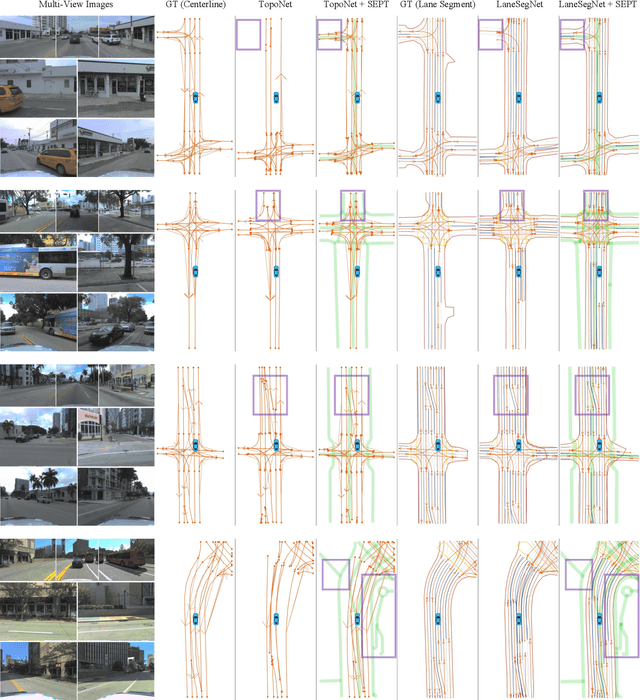
Online scene perception and topology reasoning are critical for autonomous vehicles to understand their driving environments, particularly for mapless driving systems that endeavor to reduce reliance on costly High-Definition (HD) maps. However, recent advances in online scene understanding still face limitations, especially in long-range or occluded scenarios, due to the inherent constraints of onboard sensors. To address this challenge, we propose a Standard-Definition (SD) Map Enhanced scene Perception and Topology reasoning (SEPT) framework, which explores how to effectively incorporate the SD map as prior knowledge into existing perception and reasoning pipelines. Specifically, we introduce a novel hybrid feature fusion strategy that combines SD maps with Bird's-Eye-View (BEV) features, considering both rasterized and vectorized representations, while mitigating potential misalignment between SD maps and BEV feature spaces. Additionally, we leverage the SD map characteristics to design an auxiliary intersection-aware keypoint detection task, which further enhances the overall scene understanding performance. Experimental results on the large-scale OpenLane-V2 dataset demonstrate that by effectively integrating SD map priors, our framework significantly improves both scene perception and topology reasoning, outperforming existing methods by a substantial margin.
DeCo: Task Decomposition and Skill Composition for Zero-Shot Generalization in Long-Horizon 3D Manipulation
May 01, 2025Generalizing language-conditioned multi-task imitation learning (IL) models to novel long-horizon 3D manipulation tasks remains a significant challenge. To address this, we propose DeCo (Task Decomposition and Skill Composition), a model-agnostic framework compatible with various multi-task IL models, designed to enhance their zero-shot generalization to novel, compositional, long-horizon 3D manipulation tasks. DeCo first decomposes IL demonstrations into a set of modular atomic tasks based on the physical interaction between the gripper and objects, and constructs an atomic training dataset that enables models to learn a diverse set of reusable atomic skills during imitation learning. At inference time, DeCo leverages a vision-language model (VLM) to parse high-level instructions for novel long-horizon tasks, retrieve the relevant atomic skills, and dynamically schedule their execution; a spatially-aware skill-chaining module then ensures smooth, collision-free transitions between sequential skills. We evaluate DeCo in simulation using DeCoBench, a benchmark specifically designed to assess zero-shot generalization of multi-task IL models in compositional long-horizon 3D manipulation. Across three representative multi-task IL models (RVT-2, 3DDA, and ARP), DeCo achieves success rate improvements of 66.67%, 21.53%, and 57.92%, respectively, on 12 novel compositional tasks. Moreover, in real-world experiments, a DeCo-enhanced model trained on only 6 atomic tasks successfully completes 9 novel long-horizon tasks, yielding an average success rate improvement of 53.33% over the base multi-task IL model. Video demonstrations are available at: https://deco226.github.io.
SG-Reg: Generalizable and Efficient Scene Graph Registration
Apr 20, 2025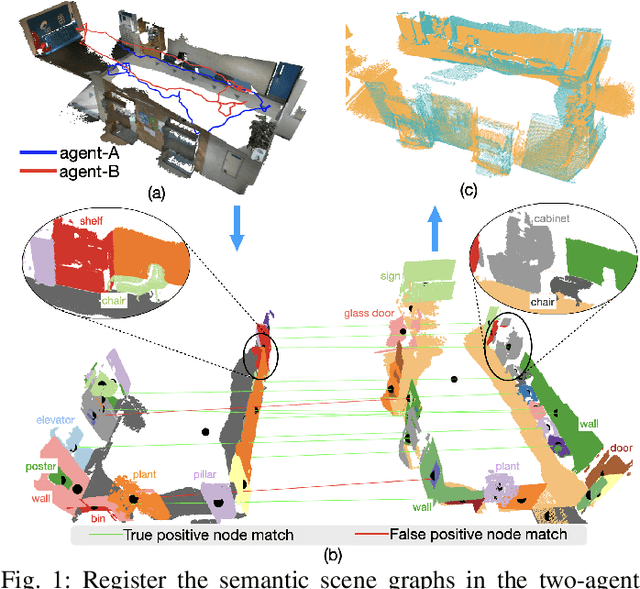
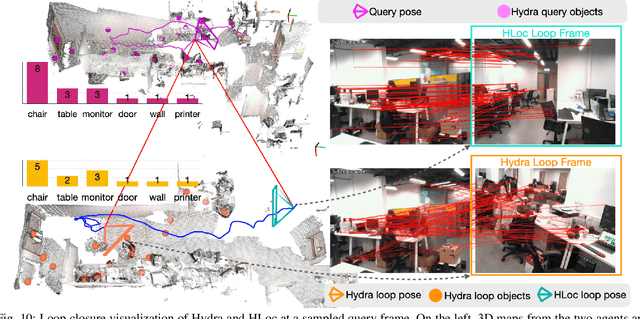
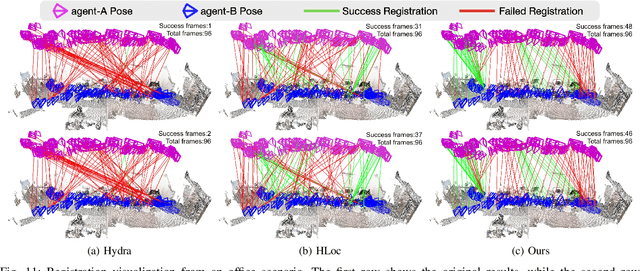
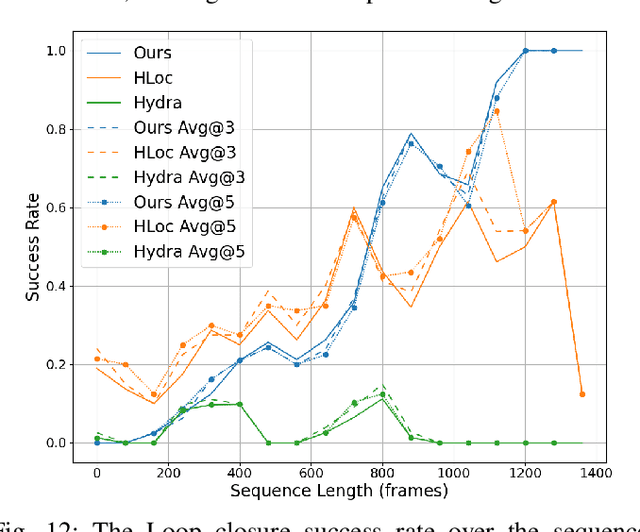
This paper addresses the challenges of registering two rigid semantic scene graphs, an essential capability when an autonomous agent needs to register its map against a remote agent, or against a prior map. The hand-crafted descriptors in classical semantic-aided registration, or the ground-truth annotation reliance in learning-based scene graph registration, impede their application in practical real-world environments. To address the challenges, we design a scene graph network to encode multiple modalities of semantic nodes: open-set semantic feature, local topology with spatial awareness, and shape feature. These modalities are fused to create compact semantic node features. The matching layers then search for correspondences in a coarse-to-fine manner. In the back-end, we employ a robust pose estimator to decide transformation according to the correspondences. We manage to maintain a sparse and hierarchical scene representation. Our approach demands fewer GPU resources and fewer communication bandwidth in multi-agent tasks. Moreover, we design a new data generation approach using vision foundation models and a semantic mapping module to reconstruct semantic scene graphs. It differs significantly from previous works, which rely on ground-truth semantic annotations to generate data. We validate our method in a two-agent SLAM benchmark. It significantly outperforms the hand-crafted baseline in terms of registration success rate. Compared to visual loop closure networks, our method achieves a slightly higher registration recall while requiring only 52 KB of communication bandwidth for each query frame. Code available at: \href{http://github.com/HKUST-Aerial-Robotics/SG-Reg}{http://github.com/HKUST-Aerial-Robotics/SG-Reg}.
GravMAD: Grounded Spatial Value Maps Guided Action Diffusion for Generalized 3D Manipulation
Sep 30, 2024Robots' ability to follow language instructions and execute diverse 3D tasks is vital in robot learning. Traditional imitation learning-based methods perform well on seen tasks but struggle with novel, unseen ones due to variability. Recent approaches leverage large foundation models to assist in understanding novel tasks, thereby mitigating this issue. However, these methods lack a task-specific learning process, which is essential for an accurate understanding of 3D environments, often leading to execution failures. In this paper, we introduce GravMAD, a sub-goal-driven, language-conditioned action diffusion framework that combines the strengths of imitation learning and foundation models. Our approach breaks tasks into sub-goals based on language instructions, allowing auxiliary guidance during both training and inference. During training, we introduce Sub-goal Keypose Discovery to identify key sub-goals from demonstrations. Inference differs from training, as there are no demonstrations available, so we use pre-trained foundation models to bridge the gap and identify sub-goals for the current task. In both phases, GravMaps are generated from sub-goals, providing flexible 3D spatial guidance compared to fixed 3D positions. Empirical evaluations on RLBench show that GravMAD significantly outperforms state-of-the-art methods, with a 28.63% improvement on novel tasks and a 13.36% gain on tasks encountered during training. These results demonstrate GravMAD's strong multi-task learning and generalization in 3D manipulation. Video demonstrations are available at: https://gravmad.github.io.
VDG: Vision-Only Dynamic Gaussian for Driving Simulation
Jun 26, 2024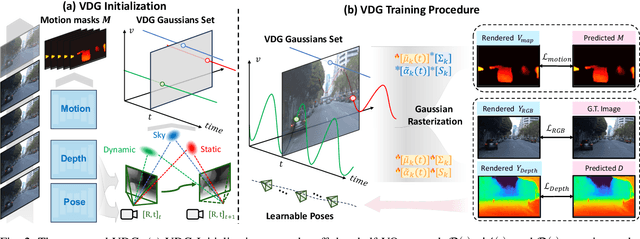
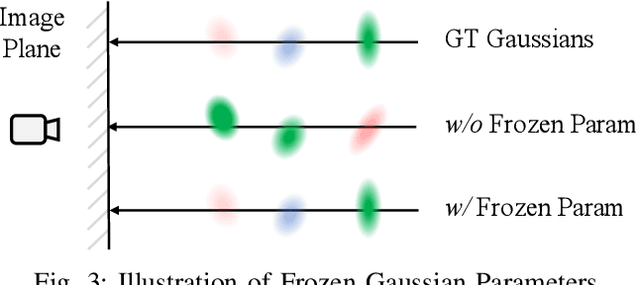


Dynamic Gaussian splatting has led to impressive scene reconstruction and image synthesis advances in novel views. Existing methods, however, heavily rely on pre-computed poses and Gaussian initialization by Structure from Motion (SfM) algorithms or expensive sensors. For the first time, this paper addresses this issue by integrating self-supervised VO into our pose-free dynamic Gaussian method (VDG) to boost pose and depth initialization and static-dynamic decomposition. Moreover, VDG can work with only RGB image input and construct dynamic scenes at a faster speed and larger scenes compared with the pose-free dynamic view-synthesis method. We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods. Additional video and source code will be posted on our project page at https://3d-aigc.github.io/VDG.
FM-Fusion: Instance-aware Semantic Mapping Boosted by Vision-Language Foundation Models
Feb 07, 2024Semantic mapping based on the supervised object detectors is sensitive to image distribution. In real-world environments, the object detection and segmentation performance can lead to a major drop, preventing the use of semantic mapping in a wider domain. On the other hand, the development of vision-language foundation models demonstrates a strong zero-shot transferability across data distribution. It provides an opportunity to construct generalizable instance-aware semantic maps. Hence, this work explores how to boost instance-aware semantic mapping from object detection generated from foundation models. We propose a probabilistic label fusion method to predict close-set semantic classes from open-set label measurements. An instance refinement module merges the over-segmented instances caused by inconsistent segmentation. We integrate all the modules into a unified semantic mapping system. Reading a sequence of RGB-D input, our work incrementally reconstructs an instance-aware semantic map. We evaluate the zero-shot performance of our method in ScanNet and SceneNN datasets. Our method achieves 40.3 mean average precision (mAP) on the ScanNet semantic instance segmentation task. It outperforms the traditional semantic mapping method significantly.
Are All Point Clouds Suitable for Completion? Weakly Supervised Quality Evaluation Network for Point Cloud Completion
Mar 03, 2023In the practical application of point cloud completion tasks, real data quality is usually much worse than the CAD datasets used for training. A small amount of noisy data will usually significantly impact the overall system's accuracy. In this paper, we propose a quality evaluation network to score the point clouds and help judge the quality of the point cloud before applying the completion model. We believe our scoring method can help researchers select more appropriate point clouds for subsequent completion and reconstruction and avoid manual parameter adjustment. Moreover, our evaluation model is fast and straightforward and can be directly inserted into any model's training or use process to facilitate the automatic selection and post-processing of point clouds. We propose a complete dataset construction and model evaluation method based on ShapeNet. We verify our network using detection and flow estimation tasks on KITTI, a real-world dataset for autonomous driving. The experimental results show that our model can effectively distinguish the quality of point clouds and help in practical tasks.
Efficient Implicit Neural Reconstruction Using LiDAR
Feb 28, 2023



Modeling scene geometry using implicit neural representation has revealed its advantages in accuracy, flexibility, and low memory usage. Previous approaches have demonstrated impressive results using color or depth images but still have difficulty handling poor light conditions and large-scale scenes. Methods taking global point cloud as input require accurate registration and ground truth coordinate labels, which limits their application scenarios. In this paper, we propose a new method that uses sparse LiDAR point clouds and rough odometry to reconstruct fine-grained implicit occupancy field efficiently within a few minutes. We introduce a new loss function that supervises directly in 3D space without 2D rendering, avoiding information loss. We also manage to refine poses of input frames in an end-to-end manner, creating consistent geometry without global point cloud registration. As far as we know, our method is the first to reconstruct implicit scene representation from LiDAR-only input. Experiments on synthetic and real-world datasets, including indoor and outdoor scenes, prove that our method is effective, efficient, and accurate, obtaining comparable results with existing methods using dense input.
You Only Label Once: 3D Box Adaptation from Point Cloud to Image via Semi-Supervised Learning
Nov 17, 2022The image-based 3D object detection task expects that the predicted 3D bounding box has a ``tightness'' projection (also referred to as cuboid), which fits the object contour well on the image while still keeping the geometric attribute on the 3D space, e.g., physical dimension, pairwise orthogonal, etc. These requirements bring significant challenges to the annotation. Simply projecting the Lidar-labeled 3D boxes to the image leads to non-trivial misalignment, while directly drawing a cuboid on the image cannot access the original 3D information. In this work, we propose a learning-based 3D box adaptation approach that automatically adjusts minimum parameters of the 360$^{\circ}$ Lidar 3D bounding box to perfectly fit the image appearance of panoramic cameras. With only a few 2D boxes annotation as guidance during the training phase, our network can produce accurate image-level cuboid annotations with 3D properties from Lidar boxes. We call our method ``you only label once'', which means labeling on the point cloud once and automatically adapting to all surrounding cameras. As far as we know, we are the first to focus on image-level cuboid refinement, which balances the accuracy and efficiency well and dramatically reduces the labeling effort for accurate cuboid annotation. Extensive experiments on the public Waymo and NuScenes datasets show that our method can produce human-level cuboid annotation on the image without needing manual adjustment.