 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDG: Vision-Only Dynamic Gaussian for Driving Simulation
Paper and Code
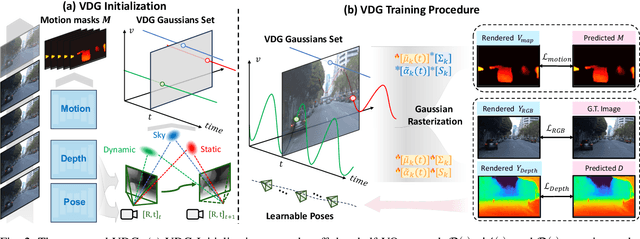
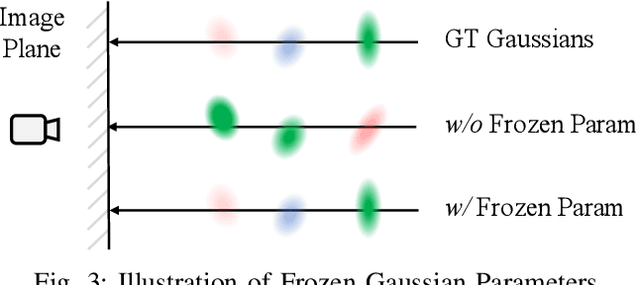


Dynamic Gaussian splatting has led to impressive scene reconstruction and image synthesis advances in novel views. Existing methods, however, heavily rely on pre-computed poses and Gaussian initialization by Structure from Motion (SfM) algorithms or expensive sensors. For the first time, this paper addresses this issue by integrating self-supervised VO into our pose-free dynamic Gaussian method (VDG) to boost pose and depth initialization and static-dynamic decomposition. Moreover, VDG can work with only RGB image input and construct dynamic scenes at a faster speed and larger scenes compared with the pose-free dynamic view-synthesis method. We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods. Additional video and source code will be posted on our project page at https://3d-aigc.github.io/VDG.