 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Control: Action-Token Planning for Vision-Language-Action Models
Jun 05, 2026Most vision-language-action (VLA) models map observations directly to actions without explicit intermediate planning, which limits performance on long-horizon tasks where early mistakes compound. We propose Coarse-to-Control, a plan-execute VLA that introduces planning natively in the action-token space. The key idea is to let the policy first predict a compact sequence of coarse action tokens that summarize the intended future trajectory, and then generate executable action tokens conditioned on this plan. Because both planning and execution share a unified discrete action vocabulary, the plan stays close to the control manifold and provides directly actionable guidance rather than an abstract hint that must be translated back to motor commands. Experiments on LIBERO, SimplerEnv-WidowX, and real-world manipulation tasks show that action-token planning consistently improves over direct action generation, with the largest gains on long-horizon multi-stage tasks.
Tool-Aware Optimization with Entropy Guidance for Efficient Agentic Reinforcement Learning
Jun 02, 2026Agentic reinforcement learning (RL) equips large language models (LLMs) with tool-use capabilities that substantially improve reasoning on complex tasks. However, integrating external tools often destabilizes training: over-reliance on tools can induce input distribution shift, while overly conservative tool use limits effective exploration. To address this issue, we propose a unified framework TAO-RL that couples tool-aware trajectory filtering with entropy-guided exploration for efficient policy optimization. Specifically, at the data level, TAO-RL filters rollout trajectories along two criteria: discarding those where all tool invocations fail to execute, and removing those where all rollouts are either correct or incorrect, as both cases yield degenerate advantage estimates that contribute no discriminative learning signal. This joint filtering retains data that are both tool-capable and informative, establishing a high-quality training distribution. At the algorithmic level, we introduce a tool-aware entropy-guided bonus that reshapes the advantage function at post-tool-call tokens, encouraging the policy to explore more diverse reasoning paths at critical decision points. These two components are mutually reinforcing: trajectory filtering establishes a clean and informative training foundation, while entropy-guided exploration drives stronger reasoning behaviors at critical tool-interaction junctures. Extensive experiments on 7 challenging reasoning benchmarks across 3 model scales demonstrate the superiority of TAO-RL over existing methods.
Uni-LaViRA: Language-Vision-Robot Actions Translation for Unified Embodied Navigation
May 26, 2026Embodied navigation requires an agent to map language and visual observations to a stream of spatial actions that drive a real robot through environments it has never seen. The dominant approach has been to scale vision-language-action (VLA) foundation models on ever-larger collections of robot trajectories. This paper argues that, for navigation specifically, generality can be obtained structurally, not only through data scale. The underlying decision structure of navigation reduces to a single Language-Vision-Robot Actions Translation. The language action emits semantic-level directional command and the vision action emits a pixel-level visual target. Both outputs lie inside the natural output manifold of pretrained multimodal large language models (MLLMs), so the task can be reasoned about by an agent rather than learned from robot data. Therefore, we present Uni-LaViRA, a unified agentic architecture that extends the same insight to four task families (VLN-CE, ObjectNav, EQA, and Aerial-VLN) and to four heterogeneous real robots (Wheeled, Quadruped, Humanoid robot, and a self-built UAV) in a zero-shot manner. Two agent-loop mechanisms make this unification practical. TODO List Memory (TDM) rewrites a structured checklist of pending sub-goals at every step, reciting the unfinished items back into the agent's most recent attention window. Second Chance Backtrack (SCB) rolls the robot back to the pre-error state and conditions the agent's next plan on the failed sub-trajectory, turning single-pass navigation into a self-correcting process. With zero training effort, Uni-LaViRA reaches 60.7% SR on VLN-CE R2R, 51.3% on VLN-CE RxR, 77.7% on HM3D-v2, 60.0% on HM3D-OVON, 54.7% on MP3D-EQA, and 40.0% on OpenUAV, matching or even surpassing recent training navigation foundation models that consume millions of samples and thousands of GPU-hours.
V-Dreamer: Automating Robotic Simulation and Trajectory Synthesis via Video Generation Priors
Mar 19, 2026Training generalist robots demands large-scale, diverse manipulation data, yet real-world collection is prohibitively expensive, and existing simulators are often constrained by fixed asset libraries and manual heuristics. To bridge this gap, we present V-Dreamer, a fully automated framework that generates open-vocabulary, simulation-ready manipulation environments and executable expert trajectories directly from natural language instructions. V-Dreamer employs a novel generative pipeline that constructs physically grounded 3D scenes using large language models and 3D generative models, validated by geometric constraints to ensure stable, collision-free layouts. Crucially, for behavior synthesis, we leverage video generation models as rich motion priors. These visual predictions are then mapped into executable robot trajectories via a robust Sim-to-Gen visual-kinematic alignment module utilizing CoTracker3 and VGGT. This pipeline supports high visual diversity and physical fidelity without manual intervention. To evaluate the generated data, we train imitation learning policies on synthesized trajectories encompassing diverse object and environment variations. Extensive evaluations on tabletop manipulation tasks using the Piper robotic arm demonstrate that our policies robustly generalize to unseen objects in simulation and achieve effective sim-to-real transfer, successfully manipulating novel real-world objects.
ST-VLA: Enabling 4D-Aware Spatiotemporal Understanding for General Robot Manipulation
Mar 14, 2026Robotic manipulation in open-world environments requires reasoning across semantics, geometry, and long-horizon action dynamics. Existing hierarchical Vision-Language-Action (VLA) frameworks typically use 2D representations to connect high-level reasoning with low-level control, but lack depth awareness and temporal consistency, limiting robustness in complex 3D scenes. We propose ST-VLA, a hierarchical VLA framework using a unified 3D-4D representation to bridge perception and action. ST-VLA converts 2D guidance into 3D trajectories and generates smooth spatial masks that capture 4D spatio-temporal context, providing a stable interface between semantic reasoning and continuous control. To enable effective learning of such representations, we introduce ST-Human, a large-scale human manipulation dataset with 14 tasks and 300k episodes, annotated with 2D, 3D, and 4D supervision via a semi-automated pipeline. Using ST-Human, we train ST-VLM, a spatio-temporal vision-language model that generates spatially grounded and temporally coherent 3D representations to guide policy execution. The smooth spatial masks focus on task-relevant geometry and stabilize latent representations, enabling online replanning and long-horizon reasoning. Experiments on RLBench and real-world manipulation tasks show that \method significantly outperforms state-of-the-art baselines, improving zero-shot success rates by 44.6% and 30.3%. These results demonstrate that offloading spatio-temporal reasoning to VLMs with unified 3D-4D representations substantially improves robustness and generalization for open-world robotic manipulation. Project website: https://oucx117.github.io/ST-VLA/.
AdaClearGrasp: Learning Adaptive Clearing for Zero-Shot Robust Dexterous Grasping in Densely Cluttered Environments
Mar 11, 2026In densely cluttered environments, physical interference, visual occlusions, and unstable contacts often cause direct dexterous grasping to fail, while aggressive singulation strategies may compromise safety. Enabling robots to adaptively decide whether to clear surrounding objects or directly grasp the target is therefore crucial for robust manipulation. We propose AdaClearGrasp, a closed-loop decision-execution framework for adaptive clearing and zero-shot dexterous grasping in densely cluttered environments. The framework formulates manipulation as a controllable high-level decision process that determines whether to directly grasp the target or first clear surrounding objects. A pretrained vision-language model (VLM) interprets visual observations and language task descriptions to reason about grasp interference and generate a high-level planning skeleton, which invokes structured atomic skills through a unified action interface. For dexterous grasping, we train a reinforcement learning policy with a relative hand-object distance representation, enabling zero-shot generalization across diverse object geometries and physical properties. During execution, visual feedback monitors outcomes and triggers replanning upon failures, forming a closed-loop correction mechanism. To evaluate language-conditioned dexterous grasping in clutter, we introduce Clutter-Bench, the first simulation benchmark with graded clutter complexity. It includes seven target objects across three clutter levels, yielding 210 task scenarios. We further perform sim-to-real experiments on three objects under three clutter levels (18 scenarios). Results demonstrate that AdaClearGrasp significantly improves grasp success rates in densely cluttered environments. For more videos and code, please visit our project website: https://chenzixuan99.github.io/adaclear-grasp.github.io/.
MoMaStage: Skill-State Graph Guided Planning and Closed-Loop Execution for Long-Horizon Indoor Mobile Manipulation
Mar 09, 2026Indoor mobile manipulation (MoMA) enables robots to translate natural language instructions into physical actions, yet long-horizon execution remains challenging due to cascading errors and limited generalization across diverse environments. Learning-based approaches often fail to maintain logical consistency over extended horizons, while methods relying on explicit scene representations impose rigid structural assumptions that reduce adaptability in dynamic settings. To address these limitations, we propose MoMaStage, a structured vision-language framework for long-horizon MoMA that eliminates the need for explicit scene mapping. MoMaStage grounds a Vision-Language Model (VLM) within a Hierarchical Skill Library and a topology-aware Skill-State Graph, constraining task decomposition and skill composition within a feasible transition space. This structured grounding ensures that generated plans remain logically consistent and topologically valid with respect to the agent's evolving physical state. To enhance robustness, MoMaStage incorporates a closed-loop execution mechanism that monitors proprioceptive feedback and triggers graph-constrained semantic replanning when deviations are detected, maintaining alignment between planned skills and physical outcomes. Extensive experiments in physics-rich simulations and real-world environments demonstrate that MoMaStage outperforms state-of-the-art baselines, achieving substantially higher planning success, reducing token overhead, and significantly improving overall task success rates in long-horizon mobile manipulation. Video demonstrations are available on the project website: https://chenxuli-cxli.github.io/MoMaStage/.
INHerit-SG: Incremental Hierarchical Semantic Scene Graphs with RAG-Style Retrieval
Feb 13, 2026Driven by advancements in foundation models, semantic scene graphs have emerged as a prominent paradigm for high-level 3D environmental abstraction in robot navigation. However, existing approaches are fundamentally misaligned with the needs of embodied tasks. As they rely on either offline batch processing or implicit feature embeddings, the maps can hardly support interpretable human-intent reasoning in complex environments. To address these limitations, we present INHerit-SG. We redefine the map as a structured, RAG-ready knowledge base where natural-language descriptions are introduced as explicit semantic anchors to better align with human intent. An asynchronous dual-process architecture, together with a Floor-Room-Area-Object hierarchy, decouples geometric segmentation from time-consuming semantic reasoning. An event-triggered map update mechanism reorganizes the graph only when meaningful semantic events occur. This strategy enables our graph to maintain long-term consistency with relatively low computational overhead. For retrieval, we deploy multi-role Large Language Models (LLMs) to decompose queries into atomic constraints and handle logical negations, and employ a hard-to-soft filtering strategy to ensure robust reasoning. This explicit interpretability improves the success rate and reliability of complex retrievals, enabling the system to adapt to a broader spectrum of human interaction tasks. We evaluate INHerit-SG on a newly constructed dataset, HM3DSem-SQR, and in real-world environments. Experiments demonstrate that our system achieves state-of-the-art performance on complex queries, and reveal its scalability for downstream navigation tasks. Project Page: https://fangyuktung.github.io/INHeritSG.github.io/
Thinking-Based Non-Thinking: Solving the Reward Hacking Problem in Training Hybrid Reasoning Models via Reinforcement Learning
Jan 08, 2026Large reasoning models (LRMs) have attracted much attention due to their exceptional performance. However, their performance mainly stems from thinking, a long Chain of Thought (CoT), which significantly increase computational overhead. To address this overthinking problem, existing work focuses on using reinforcement learning (RL) to train hybrid reasoning models that automatically decide whether to engage in thinking or not based on the complexity of the query. Unfortunately, using RL will suffer the the reward hacking problem, e.g., the model engages in thinking but is judged as not doing so, resulting in incorrect rewards. To mitigate this problem, existing works either employ supervised fine-tuning (SFT), which incurs high computational costs, or enforce uniform token limits on non-thinking responses, which yields limited mitigation of the problem. In this paper, we propose Thinking-Based Non-Thinking (TNT). It does not employ SFT, and sets different maximum token usage for responses not using thinking across various queries by leveraging information from the solution component of the responses using thinking. Experiments on five mathematical benchmarks demonstrate that TNT reduces token usage by around 50% compared to DeepSeek-R1-Distill-Qwen-1.5B/7B and DeepScaleR-1.5B, while significantly improving accuracy. In fact, TNT achieves the optimal trade-off between accuracy and efficiency among all tested methods. Additionally, the probability of reward hacking problem in TNT's responses, which are classified as not using thinking, remains below 10% across all tested datasets.
ManiLong-Shot: Interaction-Aware One-Shot Imitation Learning for Long-Horizon Manipulation
Dec 18, 2025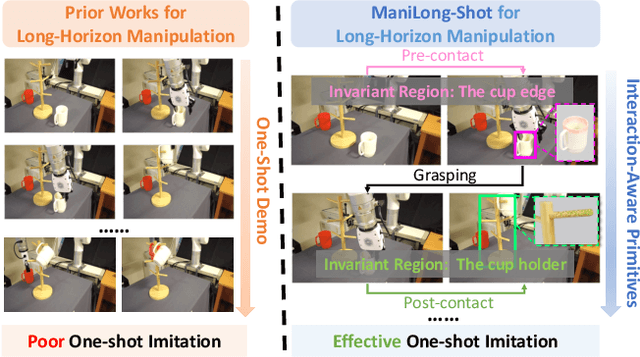

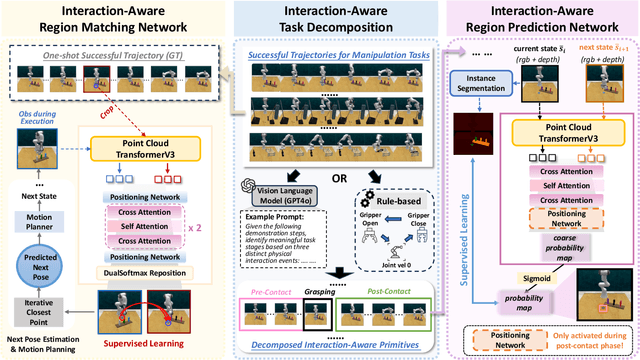
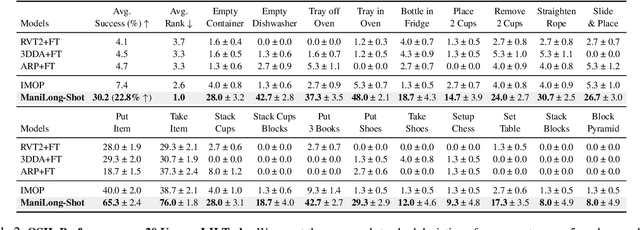
One-shot imitation learning (OSIL) offers a promising way to teach robots new skills without large-scale data collection. However, current OSIL methods are primarily limited to short-horizon tasks, thus limiting their applicability to complex, long-horizon manipulations. To address this limitation, we propose ManiLong-Shot, a novel framework that enables effective OSIL for long-horizon prehensile manipulation tasks. ManiLong-Shot structures long-horizon tasks around physical interaction events, reframing the problem as sequencing interaction-aware primitives instead of directly imitating continuous trajectories. This primitive decomposition can be driven by high-level reasoning from a vision-language model (VLM) or by rule-based heuristics derived from robot state changes. For each primitive, ManiLong-Shot predicts invariant regions critical to the interaction, establishes correspondences between the demonstration and the current observation, and computes the target end-effector pose, enabling effective task execution. Extensive simulation experiments show that ManiLong-Shot, trained on only 10 short-horizon tasks, generalizes to 20 unseen long-horizon tasks across three difficulty levels via one-shot imitation, achieving a 22.8% relative improvement over the SOTA. Additionally, real-robot experiments validate ManiLong-Shot's ability to robustly execute three long-horizon manipulation tasks via OSIL, confirming its practical applicability.