 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEPT: Standard-Definition Map Enhanced Scene Perception and Topology Reasoning for Autonomous Driving
May 18, 2025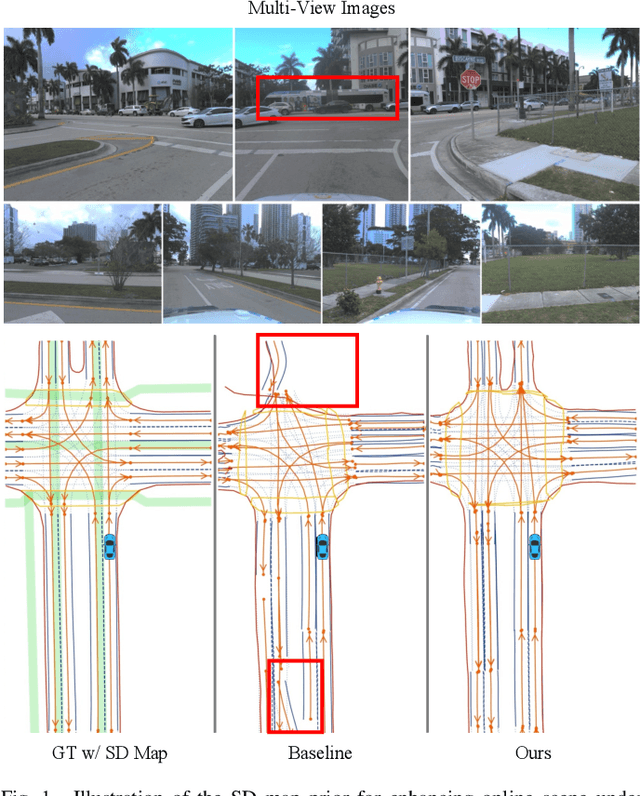
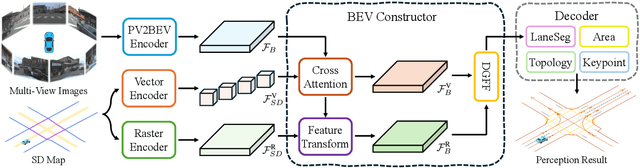
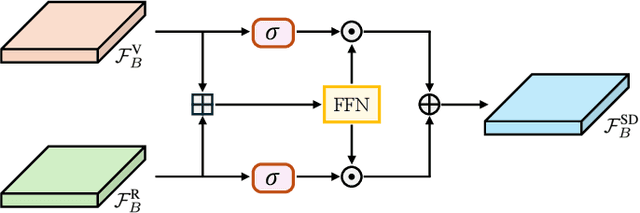
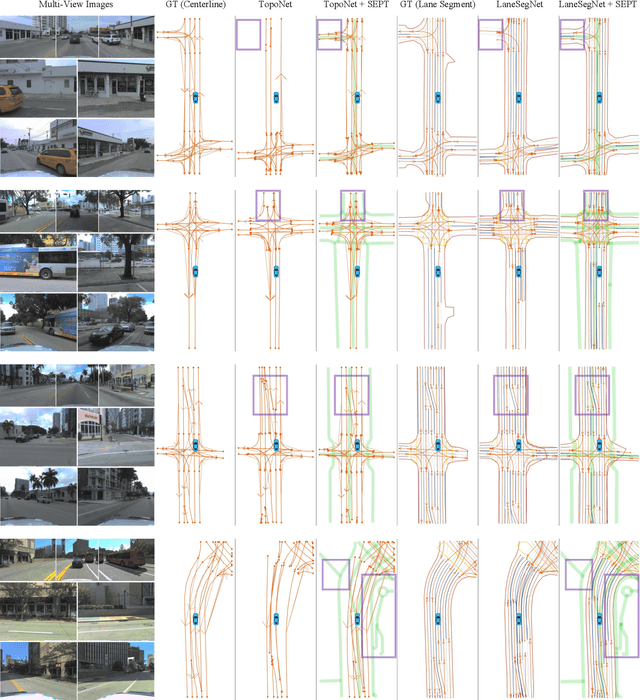
Online scene perception and topology reasoning are critical for autonomous vehicles to understand their driving environments, particularly for mapless driving systems that endeavor to reduce reliance on costly High-Definition (HD) maps. However, recent advances in online scene understanding still face limitations, especially in long-range or occluded scenarios, due to the inherent constraints of onboard sensors. To address this challenge, we propose a Standard-Definition (SD) Map Enhanced scene Perception and Topology reasoning (SEPT) framework, which explores how to effectively incorporate the SD map as prior knowledge into existing perception and reasoning pipelines. Specifically, we introduce a novel hybrid feature fusion strategy that combines SD maps with Bird's-Eye-View (BEV) features, considering both rasterized and vectorized representations, while mitigating potential misalignment between SD maps and BEV feature spaces. Additionally, we leverage the SD map characteristics to design an auxiliary intersection-aware keypoint detection task, which further enhances the overall scene understanding performance. Experimental results on the large-scale OpenLane-V2 dataset demonstrate that by effectively integrating SD map priors, our framework significantly improves both scene perception and topology reasoning, outperforming existing methods by a substantial margin.
Exploiting More Information in Sparse Point Cloud for 3D Single Object Tracking
Oct 02, 2022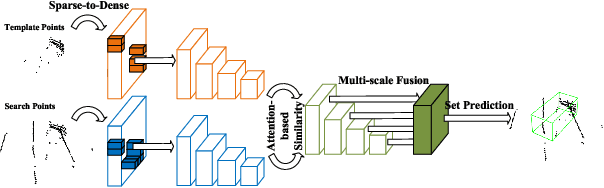
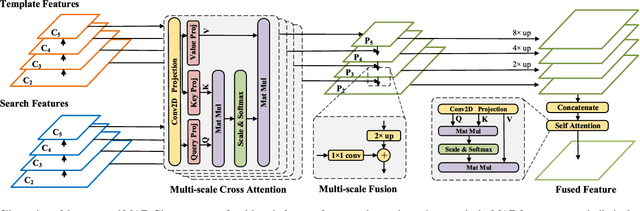
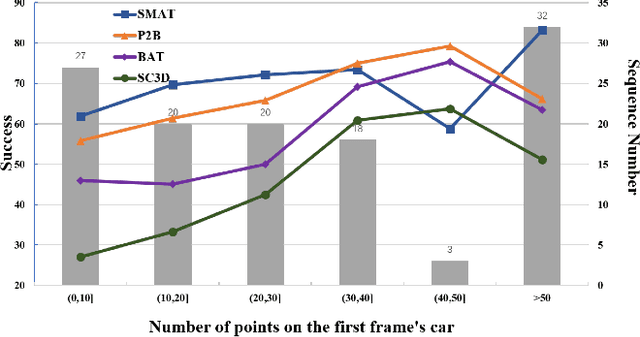
3D single object tracking is a key task in 3D computer vision. However, the sparsity of point clouds makes it difficult to compute the similarity and locate the object, posing big challenges to the 3D tracker. Previous works tried to solve the problem and improved the tracking performance in some common scenarios, but they usually failed in some extreme sparse scenarios, such as for tracking objects at long distances or partially occluded. To address the above problems, in this letter, we propose a sparse-to-dense and transformer-based framework for 3D single object tracking. First, we transform the 3D sparse points into 3D pillars and then compress them into 2D BEV features to have a dense representation. Then, we propose an attention-based encoder to achieve global similarity computation between template and search branches, which could alleviate the influence of sparsity. Meanwhile, the encoder applies the attention on multi-scale features to compensate for the lack of information caused by the sparsity of point cloud and the single scale of features. Finally, we use set-prediction to track the object through a two-stage decoder which also utilizes attention. Extensive experiments show that our method achieves very promising results on the KITTI and NuScenes datasets.
Real-time 3D Single Object Tracking with Transformer
Sep 02, 2022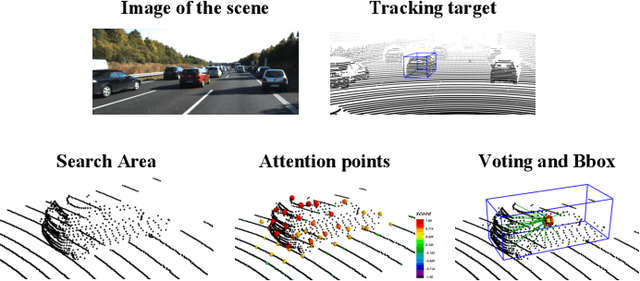
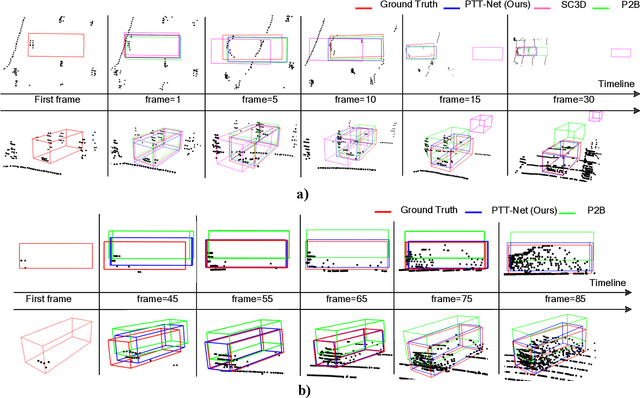
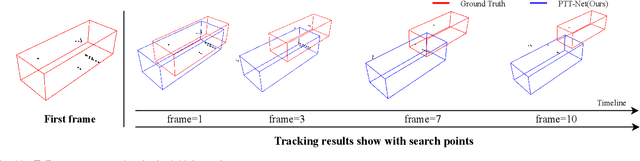
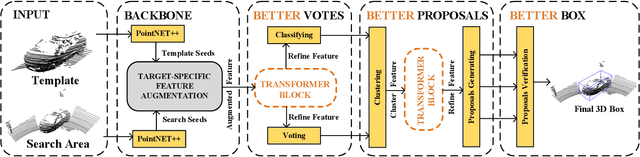
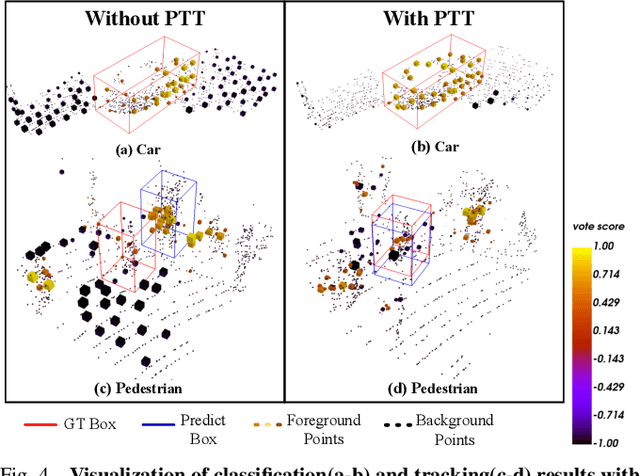
LiDAR-based 3D single object tracking is a challenging issue in robotics and autonomous driving. Currently, existing approaches usually suffer from the problem that objects at long distance often have very sparse or partially-occluded point clouds, which makes the features extracted by the model ambiguous. Ambiguous features will make it hard to locate the target object and finally lead to bad tracking results. To solve this problem, we utilize the powerful Transformer architecture and propose a Point-Track-Transformer (PTT) module for point cloud-based 3D single object tracking task. Specifically, PTT module generates fine-tuned attention features by computing attention weights, which guides the tracker focusing on the important features of the target and improves the tracking ability in complex scenarios. To evaluate our PTT module, we embed PTT into the dominant method and construct a novel 3D SOT tracker named PTT-Net. In PTT-Net, we embed PTT into the voting stage and proposal generation stage, respectively. PTT module in the voting stage could model the interactions among point patches, which learns context-dependent features. Meanwhile, PTT module in the proposal generation stage could capture the contextual information between object and background. We evaluate our PTT-Net on KITTI and NuScenes datasets. Experimental results demonstrate the effectiveness of PTT module and the superiority of PTT-Net, which surpasses the baseline by a noticeable margin, ~10% in the Car category. Meanwhile, our method also has a significant performance improvement in sparse scenarios. In general, the combination of transformer and tracking pipeline enables our PTT-Net to achieve state-of-the-art performance on both two datasets. Additionally, PTT-Net could run in real-time at 40FPS on NVIDIA 1080Ti GPU. Our code is open-sourced for the research community at https://github.com/shanjiayao/PTT.
3D Object Tracking with Transformer
Oct 28, 2021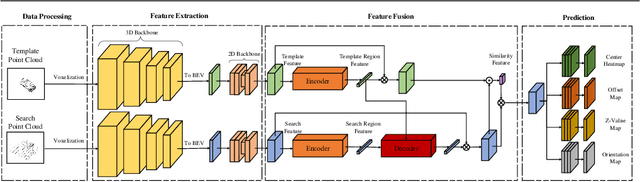
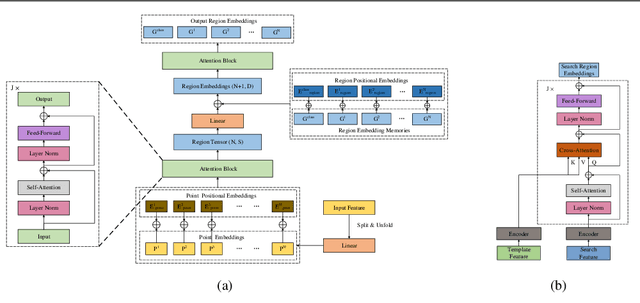
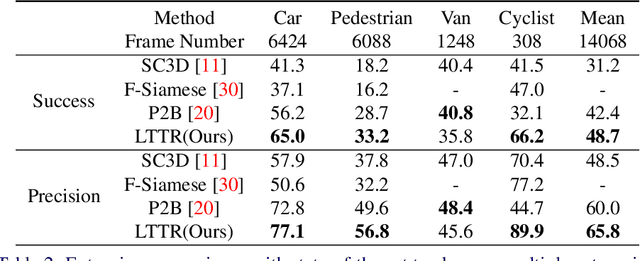
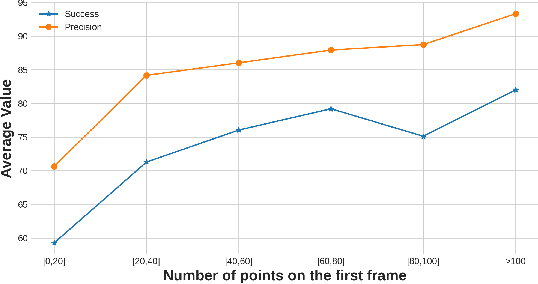
Feature fusion and similarity computation are two core problems in 3D object tracking, especially for object tracking using sparse and disordered point clouds. Feature fusion could make similarity computing more efficient by including target object information. However, most existing LiDAR-based approaches directly use the extracted point cloud feature to compute similarity while ignoring the attention changes of object regions during tracking. In this paper, we propose a feature fusion network based on transformer architecture. Benefiting from the self-attention mechanism, the transformer encoder captures the inter- and intra- relations among different regions of the point cloud. By using cross-attention, the transformer decoder fuses features and includes more target cues into the current point cloud feature to compute the region attentions, which makes the similarity computing more efficient. Based on this feature fusion network, we propose an end-to-end point cloud object tracking framework, a simple yet effective method for 3D object tracking using point clouds. Comprehensive experimental results on the KITTI dataset show that our method achieves new state-of-the-art performance. Code is available at: https://github.com/3bobo/lttr.
PTT: Point-Track-Transformer Module for 3D Single Object Tracking in Point Clouds
Aug 31, 2021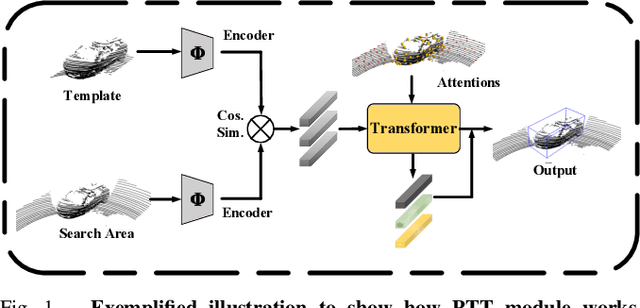
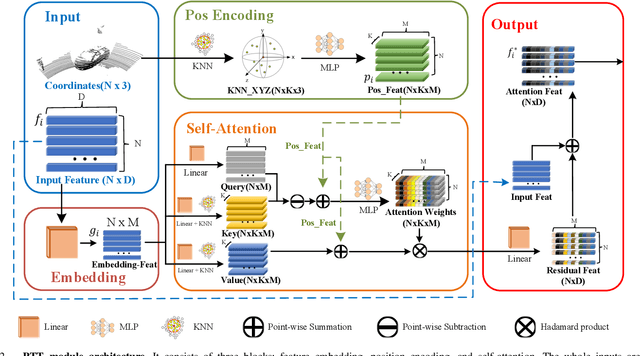
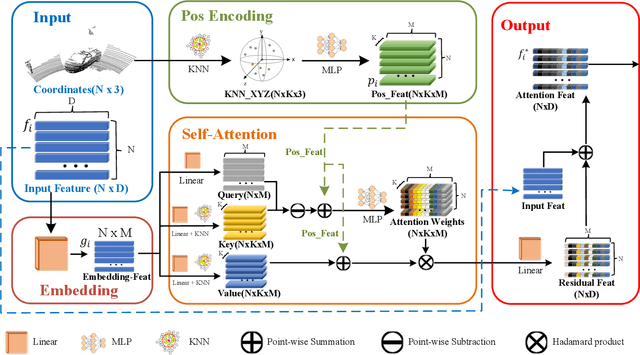
3D single object tracking is a key issue for robotics. In this paper, we propose a transformer module called Point-Track-Transformer (PTT) for point cloud-based 3D single object tracking. PTT module contains three blocks for feature embedding, position encoding, and self-attention feature computation. Feature embedding aims to place features closer in the embedding space if they have similar semantic information. Position encoding is used to encode coordinates of point clouds into high dimension distinguishable features. Self-attention generates refined attention features by computing attention weights. Besides, we embed the PTT module into the open-source state-of-the-art method P2B to construct PTT-Net. Experiments on the KITTI dataset reveal that our PTT-Net surpasses the state-of-the-art by a noticeable margin (~10\%). Additionally, PTT-Net could achieve real-time performance (~40FPS) on NVIDIA 1080Ti GPU. Our code is open-sourced for the robotics community at https://github.com/shanjiayao/PTT.