 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Multi-level Fusion for 3D Single Object Tracking
May 11, 20233D single object tracking plays a crucial role in computer vision. Mainstream methods mainly rely on point clouds to achieve geometry matching between target template and search area. However, textureless and incomplete point clouds make it difficult for single-modal trackers to distinguish objects with similar structures. To overcome the limitations of geometry matching, we propose a Multi-modal Multi-level Fusion Tracker (MMF-Track), which exploits the image texture and geometry characteristic of point clouds to track 3D target. Specifically, we first propose a Space Alignment Module (SAM) to align RGB images with point clouds in 3D space, which is the prerequisite for constructing inter-modal associations. Then, in feature interaction level, we design a Feature Interaction Module (FIM) based on dual-stream structure, which enhances intra-modal features in parallel and constructs inter-modal semantic associations. Meanwhile, in order to refine each modal feature, we introduce a Coarse-to-Fine Interaction Module (CFIM) to realize the hierarchical feature interaction at different scales. Finally, in similarity fusion level, we propose a Similarity Fusion Module (SFM) to aggregate geometry and texture clues from the target. Experiments show that our method achieves state-of-the-art performance on KITTI (39% Success and 42% Precision gains against previous multi-modal method) and is also competitive on NuScenes.
Exploiting More Information in Sparse Point Cloud for 3D Single Object Tracking
Oct 02, 2022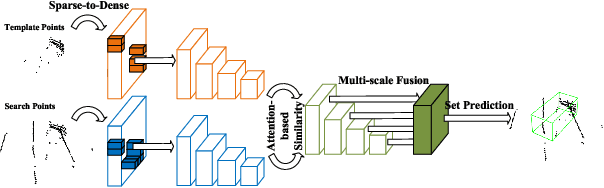
3D single object tracking is a key task in 3D computer vision. However, the sparsity of point clouds makes it difficult to compute the similarity and locate the object, posing big challenges to the 3D tracker. Previous works tried to solve the problem and improved the tracking performance in some common scenarios, but they usually failed in some extreme sparse scenarios, such as for tracking objects at long distances or partially occluded. To address the above problems, in this letter, we propose a sparse-to-dense and transformer-based framework for 3D single object tracking. First, we transform the 3D sparse points into 3D pillars and then compress them into 2D BEV features to have a dense representation. Then, we propose an attention-based encoder to achieve global similarity computation between template and search branches, which could alleviate the influence of sparsity. Meanwhile, the encoder applies the attention on multi-scale features to compensate for the lack of information caused by the sparsity of point cloud and the single scale of features. Finally, we use set-prediction to track the object through a two-stage decoder which also utilizes attention. Extensive experiments show that our method achieves very promising results on the KITTI and NuScenes datasets.
3D Object Tracking with Transformer
Oct 28, 2021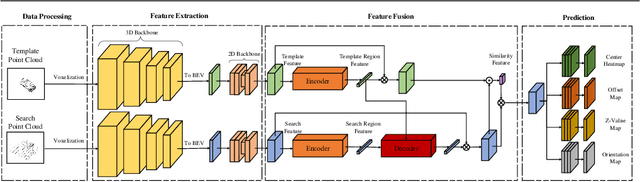
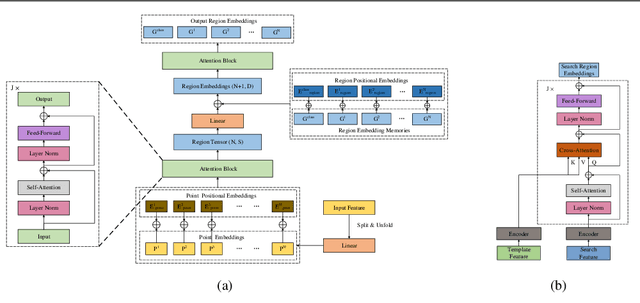
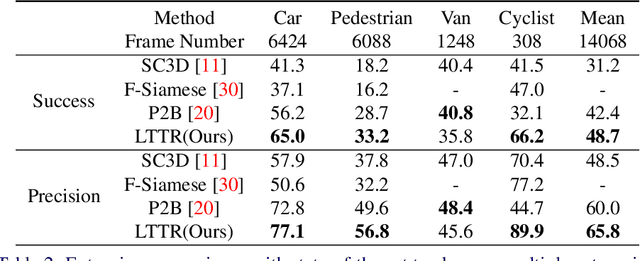
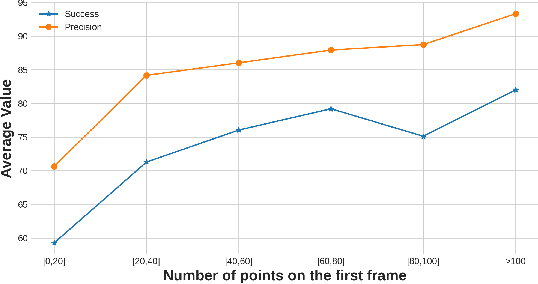
Feature fusion and similarity computation are two core problems in 3D object tracking, especially for object tracking using sparse and disordered point clouds. Feature fusion could make similarity computing more efficient by including target object information. However, most existing LiDAR-based approaches directly use the extracted point cloud feature to compute similarity while ignoring the attention changes of object regions during tracking. In this paper, we propose a feature fusion network based on transformer architecture. Benefiting from the self-attention mechanism, the transformer encoder captures the inter- and intra- relations among different regions of the point cloud. By using cross-attention, the transformer decoder fuses features and includes more target cues into the current point cloud feature to compute the region attentions, which makes the similarity computing more efficient. Based on this feature fusion network, we propose an end-to-end point cloud object tracking framework, a simple yet effective method for 3D object tracking using point clouds. Comprehensive experimental results on the KITTI dataset show that our method achieves new state-of-the-art performance. Code is available at: https://github.com/3bobo/lttr.