 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGFT: Alignment-Guided Fine-Tuning for Zero-Shot Adversarial Robustness of Vision-Language Models
Mar 31, 2026Pre-trained vision-language models (VLMs) exhibit strong zero-shot generalization but remain vulnerable to adversarial perturbations. Existing classification-guided adversarial fine-tuning methods often disrupt pre-trained cross-modal alignment, weakening visual-textual correspondence and degrading zero-shot performance. In this paper, we propose an Alignment-Guided Fine-Tuning (AGFT) framework that enhances zero-shot adversarial robustness while preserving the cross-modal semantic structure. Unlike label-based methods that rely on hard labels and fail to maintain the relative relationships between image and text, AGFT leverages the probabilistic predictions of the original model for text-guided adversarial training, which aligns adversarial visual features with textual embeddings via soft alignment distributions, improving zero-shot adversarial robustness. To address structural discrepancies introduced by fine-tuning, we introduce a distribution consistency calibration mechanism that adjusts the robust model output to match a temperature-scaled version of the pre-trained model predictions. Extensive experiments across multiple zero-shot benchmarks demonstrate that AGFT outperforms state-of-the-art methods while significantly improving zero-shot adversarial robustness.
Towards 3D Object-Centric Feature Learning for Semantic Scene Completion
Nov 18, 2025Vision-based 3D Semantic Scene Completion (SSC) has received growing attention due to its potential in autonomous driving. While most existing approaches follow an ego-centric paradigm by aggregating and diffusing features over the entire scene, they often overlook fine-grained object-level details, leading to semantic and geometric ambiguities, especially in complex environments. To address this limitation, we propose Ocean, an object-centric prediction framework that decomposes the scene into individual object instances to enable more accurate semantic occupancy prediction. Specifically, we first employ a lightweight segmentation model, MobileSAM, to extract instance masks from the input image. Then, we introduce a 3D Semantic Group Attention module that leverages linear attention to aggregate object-centric features in 3D space. To handle segmentation errors and missing instances, we further design a Global Similarity-Guided Attention module that leverages segmentation features for global interaction. Finally, we propose an Instance-aware Local Diffusion module that improves instance features through a generative process and subsequently refines the scene representation in the BEV space. Extensive experiments on the SemanticKITTI and SSCBench-KITTI360 benchmarks demonstrate that Ocean achieves state-of-the-art performance, with mIoU scores of 17.40 and 20.28, respectively.
CAO-RONet: A Robust 4D Radar Odometry with Exploring More Information from Low-Quality Points
Mar 03, 2025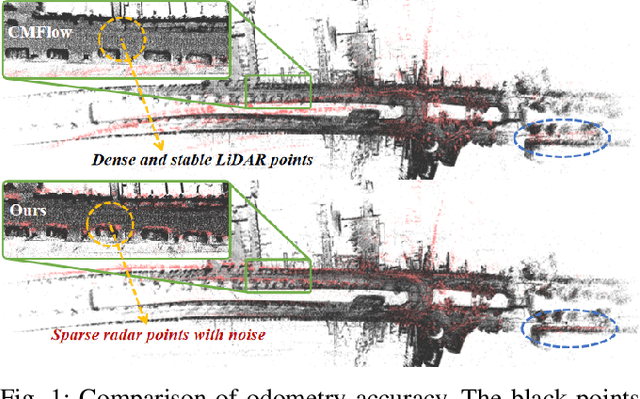
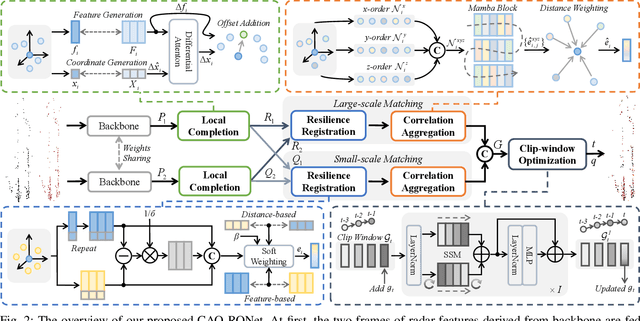
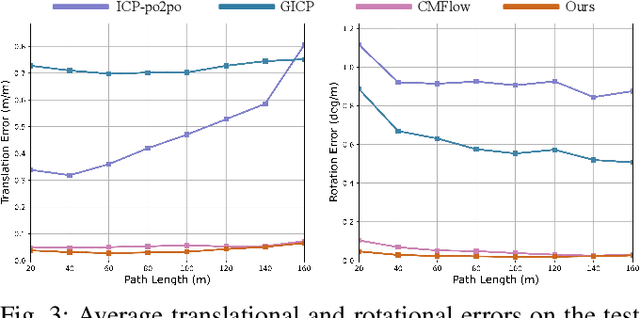
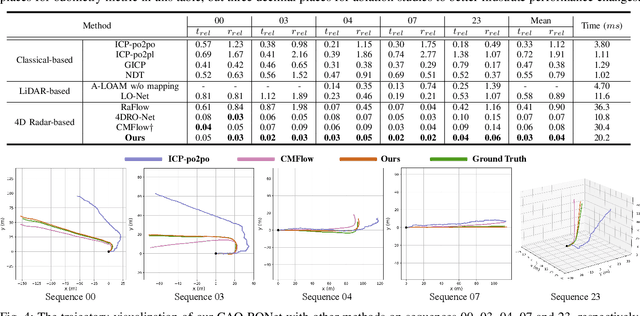
Recently, 4D millimetre-wave radar exhibits more stable perception ability than LiDAR and camera under adverse conditions (e.g. rain and fog). However, low-quality radar points hinder its application, especially the odometry task that requires a dense and accurate matching. To fully explore the potential of 4D radar, we introduce a learning-based odometry framework, enabling robust ego-motion estimation from finite and uncertain geometry information. First, for sparse radar points, we propose a local completion to supplement missing structures and provide denser guideline for aligning two frames. Then, a context-aware association with a hierarchical structure flexibly matches points of different scales aided by feature similarity, and improves local matching consistency through correlation balancing. Finally, we present a window-based optimizer that uses historical priors to establish a coupling state estimation and correct errors of inter-frame matching. The superiority of our algorithm is confirmed on View-of-Delft dataset, achieving around a 50% performance improvement over previous approaches and delivering accuracy on par with LiDAR odometry. Our code will be available.
4D-CS: Exploiting Cluster Prior for 4D Spatio-Temporal LiDAR Semantic Segmentation
Jan 06, 2025Semantic segmentation of LiDAR points has significant value for autonomous driving and mobile robot systems. Most approaches explore spatio-temporal information of multi-scan to identify the semantic classes and motion states for each point. However, these methods often overlook the segmentation consistency in space and time, which may result in point clouds within the same object being predicted as different categories. To handle this issue, our core idea is to generate cluster labels across multiple frames that can reflect the complete spatial structure and temporal information of objects. These labels serve as explicit guidance for our dual-branch network, 4D-CS, which integrates point-based and cluster-based branches to enable more consistent segmentation. Specifically, in the point-based branch, we leverage historical knowledge to enrich the current feature through temporal fusion on multiple views. In the cluster-based branch, we propose a new strategy to produce cluster labels of foreground objects and apply them to gather point-wise information to derive cluster features. We then merge neighboring clusters across multiple scans to restore missing features due to occlusion. Finally, in the point-cluster fusion stage, we adaptively fuse the information from the two branches to optimize segmentation results. Extensive experiments confirm the effectiveness of the proposed method, and we achieve state-of-the-art results on the multi-scan semantic and moving object segmentation on SemanticKITTI and nuScenes datasets. The code will be available at https://github.com/NEU-REAL/4D-CS.git.
LOMA: Language-assisted Semantic Occupancy Network via Triplane Mamba
Dec 11, 2024Vision-based 3D occupancy prediction has become a popular research task due to its versatility and affordability. Nowadays, conventional methods usually project the image-based vision features to 3D space and learn the geometric information through the attention mechanism, enabling the 3D semantic occupancy prediction. However, these works usually face two main challenges: 1) Limited geometric information. Due to the lack of geometric information in the image itself, it is challenging to directly predict 3D space information, especially in large-scale outdoor scenes. 2) Local restricted interaction. Due to the quadratic complexity of the attention mechanism, they often use modified local attention to fuse features, resulting in a restricted fusion. To address these problems, in this paper, we propose a language-assisted 3D semantic occupancy prediction network, named LOMA. In the proposed vision-language framework, we first introduce a VL-aware Scene Generator (VSG) module to generate the 3D language feature of the scene. By leveraging the vision-language model, this module provides implicit geometric knowledge and explicit semantic information from the language. Furthermore, we present a Tri-plane Fusion Mamba (TFM) block to efficiently fuse the 3D language feature and 3D vision feature. The proposed module not only fuses the two features with global modeling but also avoids too much computation costs. Experiments on the SemanticKITTI and SSCBench-KITTI360 datasets show that our algorithm achieves new state-of-the-art performances in both geometric and semantic completion tasks. Our code will be open soon.
StreamMOS: Streaming Moving Object Segmentation with Multi-View Perception and Dual-Span Memory
Jul 25, 2024


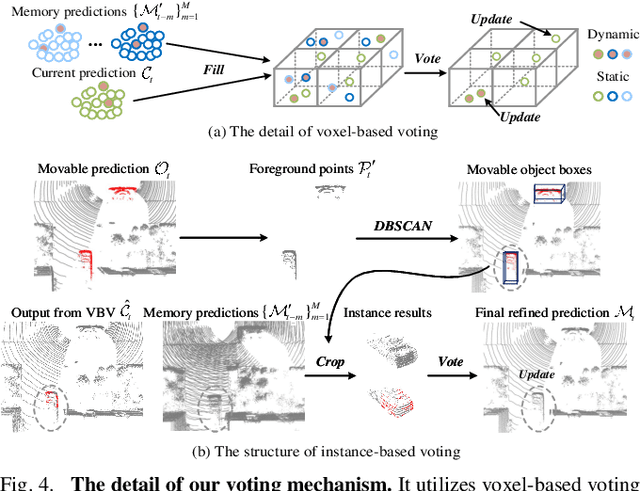
Moving object segmentation based on LiDAR is a crucial and challenging task for autonomous driving and mobile robotics. Most approaches explore spatio-temporal information from LiDAR sequences to predict moving objects in the current frame. However, they often focus on transferring temporal cues in a single inference and regard every prediction as independent of others. This may cause inconsistent segmentation results for the same object in different frames. To overcome this issue, we propose a streaming network with a memory mechanism, called StreamMOS, to build the association of features and predictions among multiple inferences. Specifically, we utilize a short-term memory to convey historical features, which can be regarded as spatial prior of moving objects and adopted to enhance current inference by temporal fusion. Meanwhile, we build a long-term memory to store previous predictions and exploit them to refine the present forecast at voxel and instance levels through voting. Besides, we present multi-view encoder with cascade projection and asymmetric convolution to extract motion feature of objects in different representations. Extensive experiments validate that our algorithm gets competitive performance on SemanticKITTI and Sipailou Campus datasets. Code will be released at https://github.com/NEU-REAL/StreamMOS.git.
FlowTrack: Point-level Flow Network for 3D Single Object Tracking
Jul 02, 2024
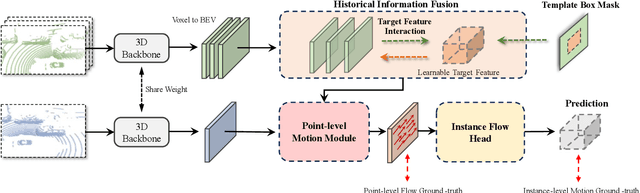

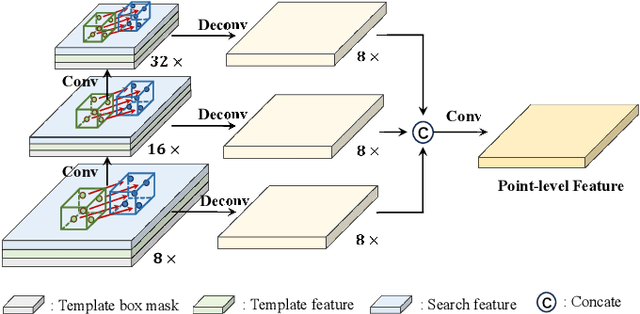
3D single object tracking (SOT) is a crucial task in fields of mobile robotics and autonomous driving. Traditional motion-based approaches achieve target tracking by estimating the relative movement of target between two consecutive frames. However, they usually overlook local motion information of the target and fail to exploit historical frame information effectively. To overcome the above limitations, we propose a point-level flow method with multi-frame information for 3D SOT task, called FlowTrack. Specifically, by estimating the flow for each point in the target, our method could capture the local motion details of target, thereby improving the tracking performance. At the same time, to handle scenes with sparse points, we present a learnable target feature as the bridge to efficiently integrate target information from past frames. Moreover, we design a novel Instance Flow Head to transform dense point-level flow into instance-level motion, effectively aggregating local motion information to obtain global target motion. Finally, our method achieves competitive performance with improvements of 5.9% on the KITTI dataset and 2.9% on NuScenes. The code will be made publicly available soon.
SeqTrack3D: Exploring Sequence Information for Robust 3D Point Cloud Tracking
Feb 26, 2024



3D single object tracking (SOT) is an important and challenging task for the autonomous driving and mobile robotics. Most existing methods perform tracking between two consecutive frames while ignoring the motion patterns of the target over a series of frames, which would cause performance degradation in the scenes with sparse points. To break through this limitation, we introduce Sequence-to-Sequence tracking paradigm and a tracker named SeqTrack3D to capture target motion across continuous frames. Unlike previous methods that primarily adopted three strategies: matching two consecutive point clouds, predicting relative motion, or utilizing sequential point clouds to address feature degradation, our SeqTrack3D combines both historical point clouds and bounding box sequences. This novel method ensures robust tracking by leveraging location priors from historical boxes, even in scenes with sparse points. Extensive experiments conducted on large-scale datasets show that SeqTrack3D achieves new state-of-the-art performances, improving by 6.00% on NuScenes and 14.13% on Waymo dataset. The code will be made public at https://github.com/aron-lin/seqtrack3d.
Motion-to-Matching: A Mixed Paradigm for 3D Single Object Tracking
Aug 23, 20233D single object tracking with LiDAR points is an important task in the computer vision field. Previous methods usually adopt the matching-based or motion-centric paradigms to estimate the current target status. However, the former is sensitive to the similar distractors and the sparseness of point cloud due to relying on appearance matching, while the latter usually focuses on short-term motion clues (eg. two frames) and ignores the long-term motion pattern of target. To address these issues, we propose a mixed paradigm with two stages, named MTM-Tracker, which combines motion modeling with feature matching into a single network. Specifically, in the first stage, we exploit the continuous historical boxes as motion prior and propose an encoder-decoder structure to locate target coarsely. Then, in the second stage, we introduce a feature interaction module to extract motion-aware features from consecutive point clouds and match them to refine target movement as well as regress other target states. Extensive experiments validate that our paradigm achieves competitive performance on large-scale datasets (70.9% in KITTI and 51.70% in NuScenes). The code will be open soon at https://github.com/LeoZhiheng/MTM-Tracker.git.
STTracker: Spatio-Temporal Tracker for 3D Single Object Tracking
Jun 30, 2023

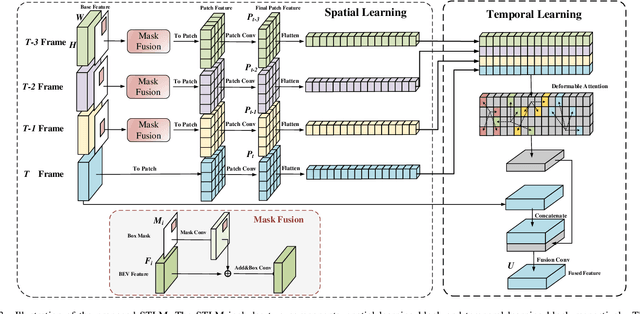

3D single object tracking with point clouds is a critical task in 3D computer vision. Previous methods usually input the last two frames and use the predicted box to get the template point cloud in previous frame and the search area point cloud in the current frame respectively, then use similarity-based or motion-based methods to predict the current box. Although these methods achieved good tracking performance, they ignore the historical information of the target, which is important for tracking. In this paper, compared to inputting two frames of point clouds, we input multi-frame of point clouds to encode the spatio-temporal information of the target and learn the motion information of the target implicitly, which could build the correlations among different frames to track the target in the current frame efficiently. Meanwhile, rather than directly using the point feature for feature fusion, we first crop the point cloud features into many patches and then use sparse attention mechanism to encode the patch-level similarity and finally fuse the multi-frame features. Extensive experiments show that our method achieves competitive results on challenging large-scale benchmarks (62.6% in KITTI and 49.66% in NuScenes).