 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-CS: Exploiting Cluster Prior for 4D Spatio-Temporal LiDAR Semantic Segmentation
Jan 06, 2025Semantic segmentation of LiDAR points has significant value for autonomous driving and mobile robot systems. Most approaches explore spatio-temporal information of multi-scan to identify the semantic classes and motion states for each point. However, these methods often overlook the segmentation consistency in space and time, which may result in point clouds within the same object being predicted as different categories. To handle this issue, our core idea is to generate cluster labels across multiple frames that can reflect the complete spatial structure and temporal information of objects. These labels serve as explicit guidance for our dual-branch network, 4D-CS, which integrates point-based and cluster-based branches to enable more consistent segmentation. Specifically, in the point-based branch, we leverage historical knowledge to enrich the current feature through temporal fusion on multiple views. In the cluster-based branch, we propose a new strategy to produce cluster labels of foreground objects and apply them to gather point-wise information to derive cluster features. We then merge neighboring clusters across multiple scans to restore missing features due to occlusion. Finally, in the point-cluster fusion stage, we adaptively fuse the information from the two branches to optimize segmentation results. Extensive experiments confirm the effectiveness of the proposed method, and we achieve state-of-the-art results on the multi-scan semantic and moving object segmentation on SemanticKITTI and nuScenes datasets. The code will be available at https://github.com/NEU-REAL/4D-CS.git.
StreamMOS: Streaming Moving Object Segmentation with Multi-View Perception and Dual-Span Memory
Jul 25, 2024


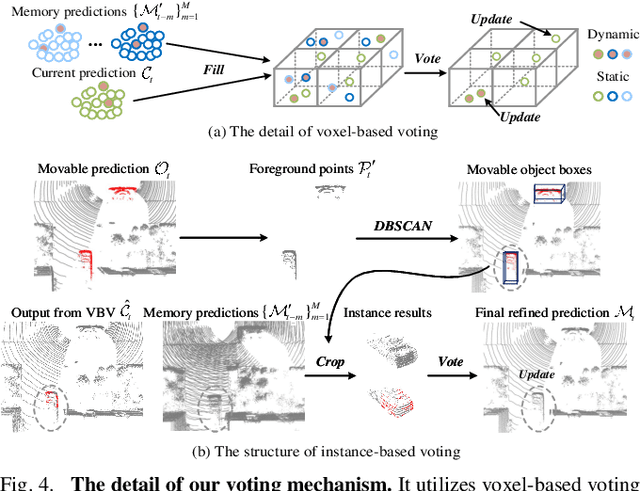
Moving object segmentation based on LiDAR is a crucial and challenging task for autonomous driving and mobile robotics. Most approaches explore spatio-temporal information from LiDAR sequences to predict moving objects in the current frame. However, they often focus on transferring temporal cues in a single inference and regard every prediction as independent of others. This may cause inconsistent segmentation results for the same object in different frames. To overcome this issue, we propose a streaming network with a memory mechanism, called StreamMOS, to build the association of features and predictions among multiple inferences. Specifically, we utilize a short-term memory to convey historical features, which can be regarded as spatial prior of moving objects and adopted to enhance current inference by temporal fusion. Meanwhile, we build a long-term memory to store previous predictions and exploit them to refine the present forecast at voxel and instance levels through voting. Besides, we present multi-view encoder with cascade projection and asymmetric convolution to extract motion feature of objects in different representations. Extensive experiments validate that our algorithm gets competitive performance on SemanticKITTI and Sipailou Campus datasets. Code will be released at https://github.com/NEU-REAL/StreamMOS.git.