 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
Mar 26, 2026Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware-algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability. The proposed system serves as an empirical platform for studying system-level design principles in long-horizon, turn-based interaction.
Finding Kissing Numbers with Game-theoretic Reinforcement Learning
Nov 17, 2025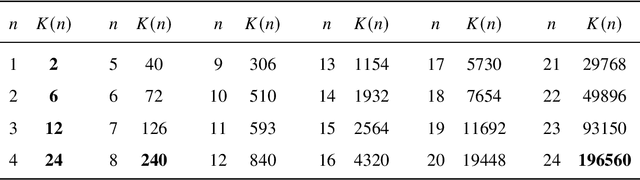
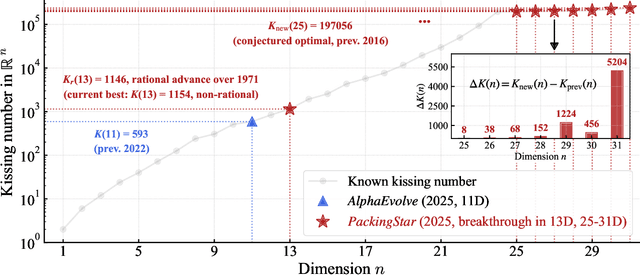

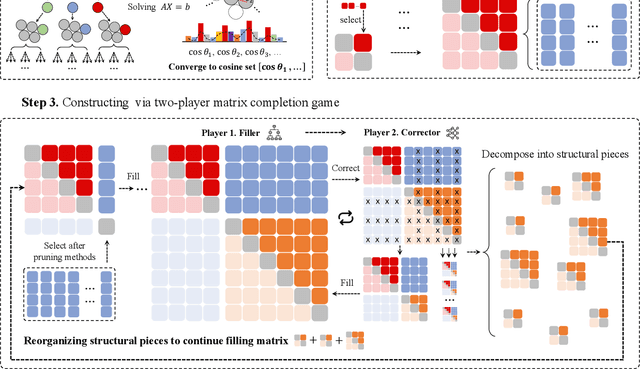
Since Isaac Newton first studied the Kissing Number Problem in 1694, determining the maximal number of non-overlapping spheres around a central sphere has remained a fundamental challenge. This problem represents the local analogue of Hilbert's 18th problem on sphere packing, bridging geometry, number theory, and information theory. Although significant progress has been made through lattices and codes, the irregularities of high-dimensional geometry and exponentially growing combinatorial complexity beyond 8 dimensions, which exceeds the complexity of Go game, limit the scalability of existing methods. Here we model this problem as a two-player matrix completion game and train the game-theoretic reinforcement learning system, PackingStar, to efficiently explore high-dimensional spaces. The matrix entries represent pairwise cosines of sphere center vectors; one player fills entries while another corrects suboptimal ones, jointly maximizing the matrix size, corresponding to the kissing number. This cooperative dynamics substantially improves sample quality, making the extremely large spaces tractable. PackingStar reproduces previous configurations and surpasses all human-known records from dimensions 25 to 31, with the configuration in 25 dimensions geometrically corresponding to the Leech lattice and suggesting possible optimality. It achieves the first breakthrough beyond rational structures from 1971 in 13 dimensions and discovers over 6000 new structures in 14 and other dimensions. These results demonstrate AI's power to explore high-dimensional spaces beyond human intuition and open new pathways for the Kissing Number Problem and broader geometry problems.
Social World Model-Augmented Mechanism Design Policy Learning
Oct 22, 2025Designing adaptive mechanisms to align individual and collective interests remains a central challenge in artificial social intelligence. Existing methods often struggle with modeling heterogeneous agents possessing persistent latent traits (e.g., skills, preferences) and dealing with complex multi-agent system dynamics. These challenges are compounded by the critical need for high sample efficiency due to costly real-world interactions. World Models, by learning to predict environmental dynamics, offer a promising pathway to enhance mechanism design in heterogeneous and complex systems. In this paper, we introduce a novel method named SWM-AP (Social World Model-Augmented Mechanism Design Policy Learning), which learns a social world model hierarchically modeling agents' behavior to enhance mechanism design. Specifically, the social world model infers agents' traits from their interaction trajectories and learns a trait-based model to predict agents' responses to the deployed mechanisms. The mechanism design policy collects extensive training trajectories by interacting with the social world model, while concurrently inferring agents' traits online during real-world interactions to further boost policy learning efficiency. Experiments in diverse settings (tax policy design, team coordination, and facility location) demonstrate that SWM-AP outperforms established model-based and model-free RL baselines in cumulative rewards and sample efficiency.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
EconGym: A Scalable AI Testbed with Diverse Economic Tasks
Jun 13, 2025



Artificial intelligence (AI) has become a powerful tool for economic research, enabling large-scale simulation and policy optimization. However, applying AI effectively requires simulation platforms for scalable training and evaluation-yet existing environments remain limited to simplified, narrowly scoped tasks, falling short of capturing complex economic challenges such as demographic shifts, multi-government coordination, and large-scale agent interactions. To address this gap, we introduce EconGym, a scalable and modular testbed that connects diverse economic tasks with AI algorithms. Grounded in rigorous economic modeling, EconGym implements 11 heterogeneous role types (e.g., households, firms, banks, governments), their interaction mechanisms, and agent models with well-defined observations, actions, and rewards. Users can flexibly compose economic roles with diverse agent algorithms to simulate rich multi-agent trajectories across 25+ economic tasks for AI-driven policy learning and analysis. Experiments show that EconGym supports diverse and cross-domain tasks-such as coordinating fiscal, pension, and monetary policies-and enables benchmarking across AI, economic methods, and hybrids. Results indicate that richer task composition and algorithm diversity expand the policy space, while AI agents guided by classical economic methods perform best in complex settings. EconGym also scales to 10k agents with high realism and efficiency.
Amulet: ReAlignment During Test Time for Personalized Preference Adaptation of LLMs
Feb 26, 2025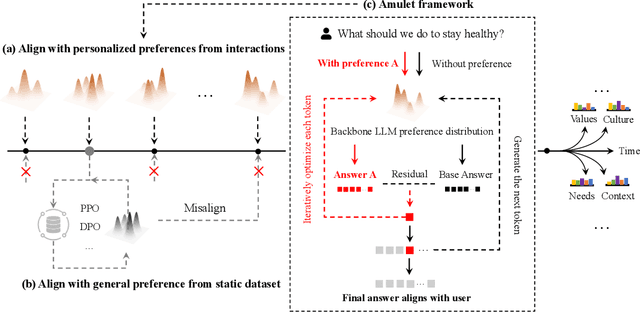
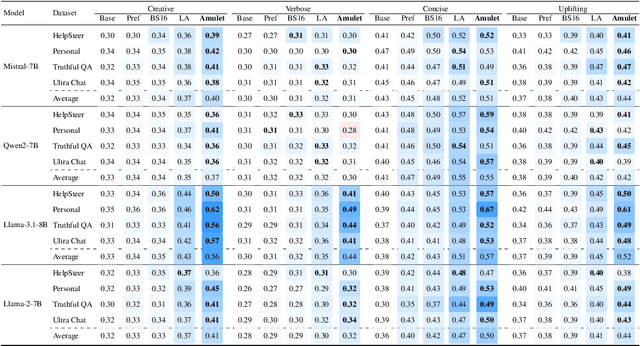
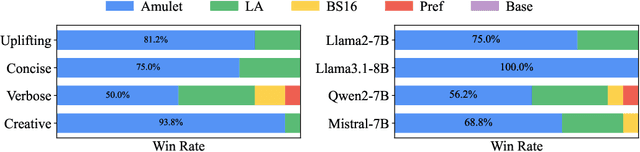

How to align large language models (LLMs) with user preferences from a static general dataset has been frequently studied. However, user preferences are usually personalized, changing, and diverse regarding culture, values, or time. This leads to the problem that the actual user preferences often do not coincide with those trained by the model developers in the practical use of LLMs. Since we cannot collect enough data and retrain for every demand, researching efficient real-time preference adaptation methods based on the backbone LLMs during test time is important. To this end, we introduce Amulet, a novel, training-free framework that formulates the decoding process of every token as a separate online learning problem with the guidance of simple user-provided prompts, thus enabling real-time optimization to satisfy users' personalized preferences. To reduce the computational cost brought by this optimization process for each token, we additionally provide a closed-form solution for each iteration step of the optimization process, thereby reducing the computational time cost to a negligible level. The detailed experimental results demonstrate that Amulet can achieve significant performance improvements in rich settings with combinations of different LLMs, datasets, and user preferences, while maintaining acceptable computational efficiency.
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Models Alignment
Oct 22, 2024



Self-play methods have demonstrated remarkable success in enhancing model capabilities across various domains. In the context of Reinforcement Learning from Human Feedback (RLHF), self-play not only boosts Large Language Model (LLM) performance but also overcomes the limitations of traditional Bradley-Terry (BT) model assumptions by finding the Nash equilibrium (NE) of a preference-based, two-player constant-sum game. However, existing methods either guarantee only average-iterate convergence, incurring high storage and inference costs, or converge to the NE of a regularized game, failing to accurately reflect true human preferences. In this paper, we introduce Magnetic Preference Optimization (MPO), a novel approach capable of achieving last-iterate convergence to the NE of the original game, effectively overcoming the limitations of existing methods. Building upon Magnetic Mirror Descent (MMD), MPO attains a linear convergence rate, making it particularly suitable for fine-tuning LLMs. To ensure our algorithm is both theoretically sound and practically viable, we present a simple yet effective implementation that adapts the theoretical insights to the RLHF setting. Empirical results demonstrate that MPO can significantly enhance the performance of LLMs, highlighting the potential of self-play methods in alignment.
A Survey on Self-play Methods in Reinforcement Learning
Aug 02, 2024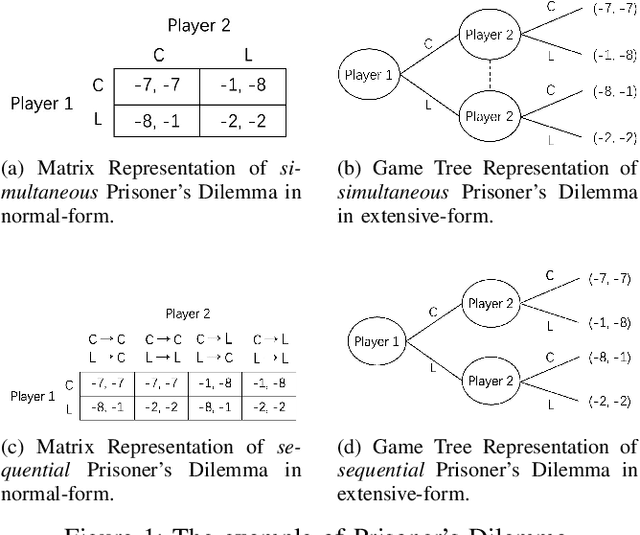
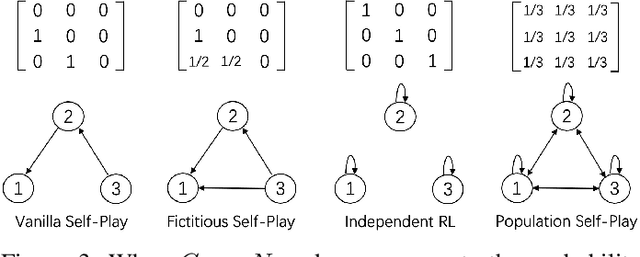
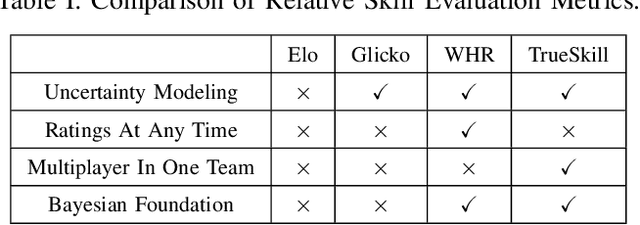
Self-play, characterized by agents' interactions with copies or past versions of itself, has recently gained prominence in reinforcement learning. This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
Fusion-PSRO: Nash Policy Fusion for Policy Space Response Oracles
Jun 03, 2024A popular approach for solving zero-sum games is to maintain populations of policies to approximate the Nash Equilibrium (NE). Previous studies have shown that Policy Space Response Oracle (PSRO) algorithm is an effective multi-agent reinforcement learning framework for solving such games. However, repeatedly training new policies from scratch to approximate Best Response (BR) to opponents' mixed policies at each iteration is both inefficient and costly. While some PSRO variants initialize a new policy by inheriting from past BR policies, this approach limits the exploration of new policies, especially against challenging opponents. To address this issue, we propose Fusion-PSRO, which employs policy fusion to initialize policies for better approximation to BR. By selecting high-quality base policies from meta-NE, policy fusion fuses the base policies into a new policy through model averaging. This approach allows the initialized policies to incorporate multiple expert policies, making it easier to handle difficult opponents compared to inheriting from past BR policies or initializing from scratch. Moreover, our method only modifies the policy initialization phase, allowing its application to nearly all PSRO variants without additional training overhead. Our experiments on non-transitive matrix games, Leduc Poker, and the more complex Liars Dice demonstrate that Fusion-PSRO enhances the performance of nearly all PSRO variants, achieving lower exploitability.
Incentive Compatibility for AI Alignment in Sociotechnical Systems: Positions and Prospects
Mar 01, 2024

The burgeoning integration of artificial intelligence (AI) into human society brings forth significant implications for societal governance and safety. While considerable strides have been made in addressing AI alignment challenges, existing methodologies primarily focus on technical facets, often neglecting the intricate sociotechnical nature of AI systems, which can lead to a misalignment between the development and deployment contexts. To this end, we posit a new problem worth exploring: Incentive Compatibility Sociotechnical Alignment Problem (ICSAP). We hope this can call for more researchers to explore how to leverage the principles of Incentive Compatibility (IC) from game theory to bridge the gap between technical and societal components to maintain AI consensus with human societies in different contexts. We further discuss three classical game problems for achieving IC: mechanism design, contract theory, and Bayesian persuasion, in addressing the perspectives, potentials, and challenges of solving ICSAP, and provide preliminary implementation conceptions.