 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Decentralized Model-based Policy Optimization for Networked Systems
Paper and Code


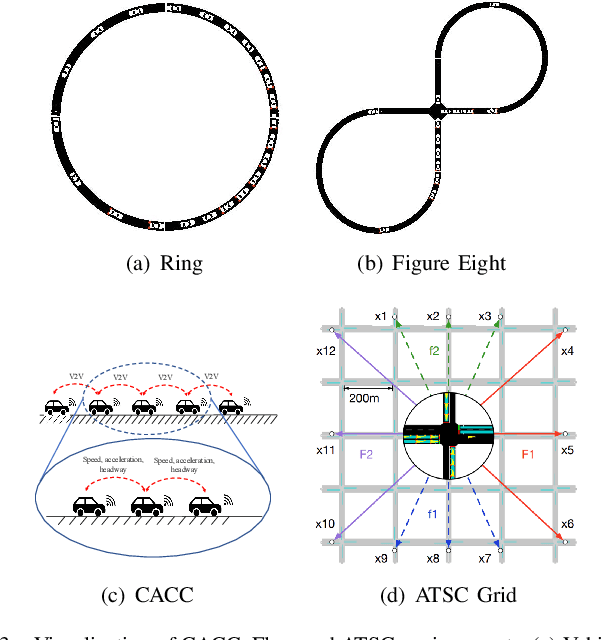

Reinforcement learning algorithms require a large amount of samples; this often limits their real-world applications on even simple tasks. Such a challenge is more outstanding in multi-agent tasks, as each step of operation is more costly requiring communications or shifting or resources. This work aims to improve data efficiency of multi-agent control by model-based learning. We consider networked systems where agents are cooperative and communicate only locally with their neighbors, and propose the decentralized model-based policy optimization framework (DMPO). In our method, each agent learns a dynamic model to predict future states and broadcast their predictions by communication, and then the policies are trained under the model rollouts. To alleviate the bias of model-generated data, we restrain the model usage for generating myopic rollouts, thus reducing the compounding error of model generation. To pertain the independence of policy update, we introduce extended value function and theoretically prove that the resulting policy gradient is a close approximation to true policy gradients. We evaluate our algorithm on several benchmarks for intelligent transportation systems, which are connected autonomous vehicle control tasks (Flow and CACC) and adaptive traffic signal control (ATSC). Empirically results show that our method achieves superior data efficiency and matches the performance of model-free methods using true models.