 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Dec 16, 2025Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data. To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity. Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining "chicken-and-egg" cycle for scalable and reproducible portrait illumination. Our project page: https://rex0191.github.io/POLAR/.
Prismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems
Dec 09, 2025Model-based planning in robotic domains is fundamentally challenged by the hybrid nature of physical dynamics, where continuous motion is punctuated by discrete events such as contacts and impacts. Conventional latent world models typically employ monolithic neural networks that enforce global continuity, inevitably over-smoothing the distinct dynamic modes (e.g., sticking vs. sliding, flight vs. stance). For a planner, this smoothing results in catastrophic compounding errors during long-horizon lookaheads, rendering the search process unreliable at physical boundaries. To address this, we introduce the Prismatic World Model (PRISM-WM), a structured architecture designed to decompose complex hybrid dynamics into composable primitives. PRISM-WM leverages a context-aware Mixture-of-Experts (MoE) framework where a gating mechanism implicitly identifies the current physical mode, and specialized experts predict the associated transition dynamics. We further introduce a latent orthogonalization objective to ensure expert diversity, effectively preventing mode collapse. By accurately modeling the sharp mode transitions in system dynamics, PRISM-WM significantly reduces rollout drift. Extensive experiments on challenging continuous control benchmarks, including high-dimensional humanoids and diverse multi-task settings, demonstrate that PRISM-WM provides a superior high-fidelity substrate for trajectory optimization algorithms (e.g., TD-MPC), proving its potential as a powerful foundational model for next-generation model-based agents.
Social World Model-Augmented Mechanism Design Policy Learning
Oct 22, 2025Designing adaptive mechanisms to align individual and collective interests remains a central challenge in artificial social intelligence. Existing methods often struggle with modeling heterogeneous agents possessing persistent latent traits (e.g., skills, preferences) and dealing with complex multi-agent system dynamics. These challenges are compounded by the critical need for high sample efficiency due to costly real-world interactions. World Models, by learning to predict environmental dynamics, offer a promising pathway to enhance mechanism design in heterogeneous and complex systems. In this paper, we introduce a novel method named SWM-AP (Social World Model-Augmented Mechanism Design Policy Learning), which learns a social world model hierarchically modeling agents' behavior to enhance mechanism design. Specifically, the social world model infers agents' traits from their interaction trajectories and learns a trait-based model to predict agents' responses to the deployed mechanisms. The mechanism design policy collects extensive training trajectories by interacting with the social world model, while concurrently inferring agents' traits online during real-world interactions to further boost policy learning efficiency. Experiments in diverse settings (tax policy design, team coordination, and facility location) demonstrate that SWM-AP outperforms established model-based and model-free RL baselines in cumulative rewards and sample efficiency.
Differentiable Information Enhanced Model-Based Reinforcement Learning
Mar 03, 2025Differentiable environments have heralded new possibilities for learning control policies by offering rich differentiable information that facilitates gradient-based methods. In comparison to prevailing model-free reinforcement learning approaches, model-based reinforcement learning (MBRL) methods exhibit the potential to effectively harness the power of differentiable information for recovering the underlying physical dynamics. However, this presents two primary challenges: effectively utilizing differentiable information to 1) construct models with more accurate dynamic prediction and 2) enhance the stability of policy training. In this paper, we propose a Differentiable Information Enhanced MBRL method, MB-MIX, to address both challenges. Firstly, we adopt a Sobolev model training approach that penalizes incorrect model gradient outputs, enhancing prediction accuracy and yielding more precise models that faithfully capture system dynamics. Secondly, we introduce mixing lengths of truncated learning windows to reduce the variance in policy gradient estimation, resulting in improved stability during policy learning. To validate the effectiveness of our approach in differentiable environments, we provide theoretical analysis and empirical results. Notably, our approach outperforms previous model-based and model-free methods, in multiple challenging tasks involving controllable rigid robots such as humanoid robots' motion control and deformable object manipulation.
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
Jan 19, 2025



Multi-objective optimization (MOO) in deep learning aims to simultaneously optimize multiple conflicting objectives, a challenge frequently encountered in areas like multi-task learning and multi-criteria learning. Recent advancements in gradient-based MOO methods have enabled the discovery of diverse types of solutions, ranging from a single balanced solution to finite or even infinite Pareto sets, tailored to user needs. These developments have broad applications across domains such as reinforcement learning, computer vision, recommendation systems, and large language models. This survey provides the first comprehensive review of gradient-based MOO in deep learning, covering algorithms, theories, and practical applications. By unifying various approaches and identifying critical challenges, it serves as a foundational resource for driving innovation in this evolving field. A comprehensive list of MOO algorithms in deep learning is available at \url{https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning}.
Online Mirror Descent for Tchebycheff Scalarization in Multi-Objective Optimization
Oct 29, 2024The goal of multi-objective optimization (MOO) is to learn under multiple, potentially conflicting, objectives. One widely used technique to tackle MOO is through linear scalarization, where one fixed preference vector is used to combine the objectives into a single scalar value for optimization. However, recent work (Hu et al., 2024) has shown linear scalarization often fails to capture the non-convex regions of the Pareto Front, failing to recover the complete set of Pareto optimal solutions. In light of the above limitations, this paper focuses on Tchebycheff scalarization that optimizes for the worst-case objective. In particular, we propose an online mirror descent algorithm for Tchebycheff scalarization, which we call OMD-TCH. We show that OMD-TCH enjoys a convergence rate of $O(\sqrt{\log m/T})$ where $m$ is the number of objectives and $T$ is the number of iteration rounds. We also propose a novel adaptive online-to-batch conversion scheme that significantly improves the practical performance of OMD-TCH while maintaining the same convergence guarantees. We demonstrate the effectiveness of OMD-TCH and the adaptive conversion scheme on both synthetic problems and federated learning tasks under fairness constraints, showing state-of-the-art performance.
LibMOON: A Gradient-based MultiObjective OptimizatioN Library in PyTorch
Sep 04, 2024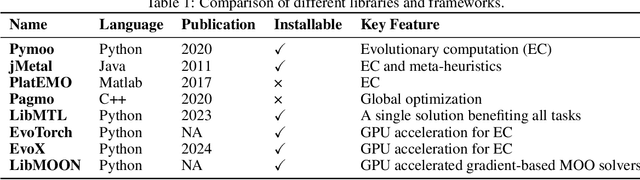
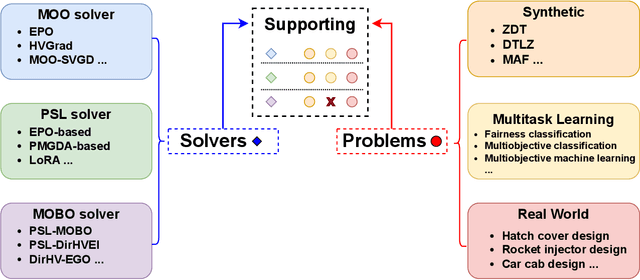

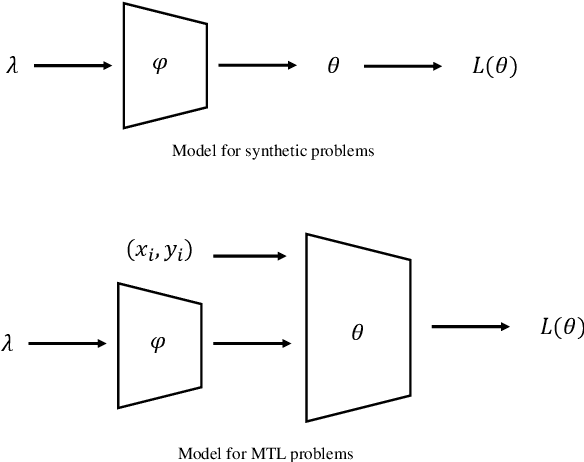
Multiobjective optimization problems (MOPs) are prevalent in machine learning, with applications in multi-task learning, learning under fairness or robustness constraints, etc. Instead of reducing multiple objective functions into a scalar objective, MOPs aim to optimize for the so-called Pareto optimality or Pareto set learning, which involves optimizing more than one objective function simultaneously, over models with millions of parameters. Existing benchmark libraries for MOPs mainly focus on evolutionary algorithms, most of which are zeroth-order methods that do not effectively utilize higher-order information from objectives and cannot scale to large-scale models with millions of parameters. In light of the above gap, this paper introduces LibMOON, the first multiobjective optimization library that supports state-of-the-art gradient-based methods, provides a fair benchmark, and is open-sourced for the community.
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Aug 12, 2024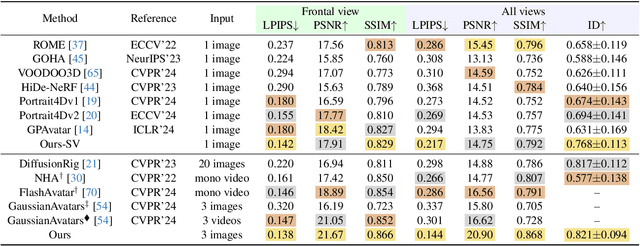

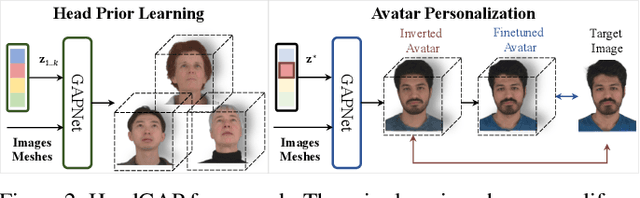
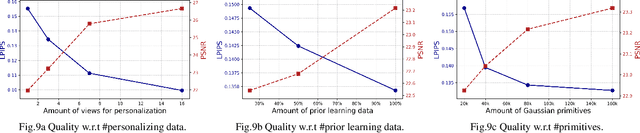
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
Few for Many: Tchebycheff Set Scalarization for Many-Objective Optimization
May 30, 2024


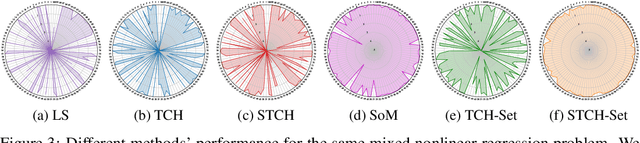
Multi-objective optimization can be found in many real-world applications where some conflicting objectives can not be optimized by a single solution. Existing optimization methods often focus on finding a set of Pareto solutions with different optimal trade-offs among the objectives. However, the required number of solutions to well approximate the whole Pareto optimal set could be exponentially large with respect to the number of objectives, which makes these methods unsuitable for handling many optimization objectives. In this work, instead of finding a dense set of Pareto solutions, we propose a novel Tchebycheff set scalarization method to find a few representative solutions (e.g., 5) to cover a large number of objectives (e.g., $>100$) in a collaborative and complementary manner. In this way, each objective can be well addressed by at least one solution in the small solution set. In addition, we further develop a smooth Tchebycheff set scalarization approach for efficient optimization with good theoretical guarantees. Experimental studies on different problems with many optimization objectives demonstrate the effectiveness of our proposed method.
Smooth Tchebycheff Scalarization for Multi-Objective Optimization
Mar 14, 2024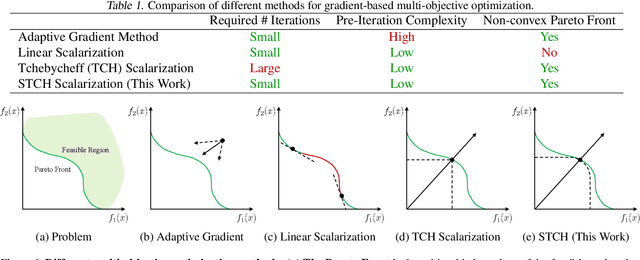

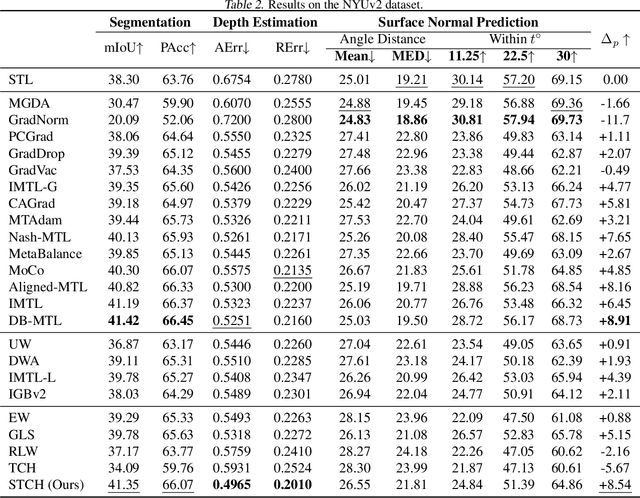
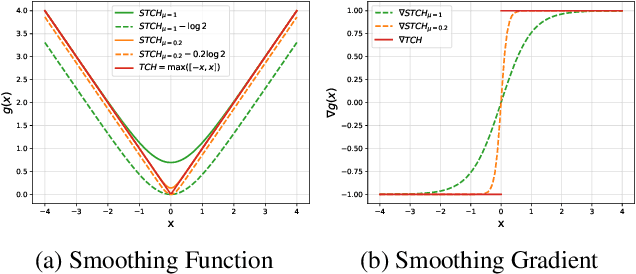
Multi-objective optimization problems can be found in many real-world applications, where the objectives often conflict each other and cannot be optimized by a single solution. In the past few decades, numerous methods have been proposed to find Pareto solutions that represent different optimal trade-offs among the objectives for a given problem. However, these existing methods could have high computational complexity or may not have good theoretical properties for solving a general differentiable multi-objective optimization problem. In this work, by leveraging the smooth optimization technique, we propose a novel and lightweight smooth Tchebycheff scalarization approach for gradient-based multi-objective optimization. It has good theoretical properties for finding all Pareto solutions with valid trade-off preferences, while enjoying significantly lower computational complexity compared to other methods. Experimental results on various real-world application problems fully demonstrate the effectiveness of our proposed method.