 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy and World Modeling Co-Training for Language Agents
Jun 01, 2026Reinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment. World modeling (WM) can fill this gap, yet existing approaches often require separate simulators, extra training stages, or additional inference-time computation. We observe that on-policy RL rollouts already contain the needed signal: each transition pairs an action with its resulting next observation. Based on this observation, we propose PaW, a Policy and World modeling co-training framework that adds auxiliary WM supervision to the same policy during RL, without changing the inference paradigm. To make auxiliary WM supervision informative and stable, PaW introduces three components: action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing. Experiments on three agentic task benchmarks show consistent improvements over strong RL baselines across models and RL algorithms. These results suggest that standard RL rollouts are a practical source of WM supervision for language-agent training.
RAIN-Merging: A Gradient-Free Method to Enhance Instruction Following in Large Reasoning Models with Preserved Thinking Format
Feb 26, 2026Large reasoning models (LRMs) excel at a long chain of reasoning but often fail to faithfully follow instructions regarding output format, constraints, or specific requirements. We investigate whether this gap can be closed by integrating an instruction-tuned model (ITM) into an LRM. Analyzing their differences in parameter space, namely task vectors, we find that their principal subspaces are nearly orthogonal across key modules, suggesting a lightweight merging with minimal interference. However, we also demonstrate that naive merges are fragile because they overlook the output format mismatch between LRMs (with explicit thinking and response segments) and ITMs (answers-only). We introduce RAIN-Merging (Reasoning-Aware Instruction-attention guided Null-space projection Merging), a gradient-free method that integrates instruction following while preserving thinking format and reasoning performance. First, with a small reasoning calibration set, we project the ITM task vector onto the null space of forward features at thinking special tokens, which preserves the LRM's structured reasoning mechanisms. Second, using a small instruction calibration set, we estimate instruction attention to derive module-specific scaling that amplifies instruction-relevant components and suppresses leakage. Across four instruction-following benchmarks and nine reasoning & general capability benchmarks, RAIN-Merging substantially improves instruction adherence while maintaining reasoning quality. The gains are consistent across model scales and architectures, translating to improved performance in agent settings.
VL-RouterBench: A Benchmark for Vision-Language Model Routing
Dec 29, 2025Multi-model routing has evolved from an engineering technique into essential infrastructure, yet existing work lacks a systematic, reproducible benchmark for evaluating vision-language models (VLMs). We present VL-RouterBench to assess the overall capability of VLM routing systems systematically. The benchmark is grounded in raw inference and scoring logs from VLMs and constructs quality and cost matrices over sample-model pairs. In scale, VL-RouterBench covers 14 datasets across 3 task groups, totaling 30,540 samples, and includes 15 open-source models and 2 API models, yielding 519,180 sample-model pairs and a total input-output token volume of 34,494,977. The evaluation protocol jointly measures average accuracy, average cost, and throughput, and builds a ranking score from the harmonic mean of normalized cost and accuracy to enable comparison across router configurations and cost budgets. On this benchmark, we evaluate 10 routing methods and baselines and observe a significant routability gain, while the best current routers still show a clear gap to the ideal Oracle, indicating considerable room for improvement in router architecture through finer visual cues and modeling of textual structure. We will open-source the complete data construction and evaluation toolchain to promote comparability, reproducibility, and practical deployment in multimodal routing research.
Efficient Reasoning for Large Reasoning Language Models via Certainty-Guided Reflection Suppression
Aug 07, 2025Recent Large Reasoning Language Models (LRLMs) employ long chain-of-thought reasoning with complex reflection behaviors, typically signaled by specific trigger words (e.g., "Wait" and "Alternatively") to enhance performance. However, these reflection behaviors can lead to the overthinking problem where the generation of redundant reasoning steps that unnecessarily increase token usage, raise inference costs, and reduce practical utility. In this paper, we propose Certainty-Guided Reflection Suppression (CGRS), a novel method that mitigates overthinking in LRLMs while maintaining reasoning accuracy. CGRS operates by dynamically suppressing the model's generation of reflection triggers when it exhibits high confidence in its current response, thereby preventing redundant reflection cycles without compromising output quality. Our approach is model-agnostic, requires no retraining or architectural modifications, and can be integrated seamlessly with existing autoregressive generation pipelines. Extensive experiments across four reasoning benchmarks (i.e., AIME24, AMC23, MATH500, and GPQA-D) demonstrate CGRS's effectiveness: it reduces token usage by an average of 18.5% to 41.9% while preserving accuracy. It also achieves the optimal balance between length reduction and performance compared to state-of-the-art baselines. These results hold consistently across model architectures (e.g., DeepSeek-R1-Distill series, QwQ-32B, and Qwen3 family) and scales (4B to 32B parameters), highlighting CGRS's practical value for efficient reasoning.
PARM: Multi-Objective Test-Time Alignment via Preference-Aware Autoregressive Reward Model
May 06, 2025



Multi-objective test-time alignment aims to adapt large language models (LLMs) to diverse multi-dimensional user preferences during inference while keeping LLMs frozen. Recently, GenARM (Xu et al., 2025) first independently trains Autoregressive Reward Models (ARMs) for each preference dimension without awareness of each other, then combines their outputs based on user-specific preference vectors during inference to achieve multi-objective test-time alignment, leading to two key limitations: the need for \textit{multiple} ARMs increases the inference cost, and the separate training of ARMs causes the misalignment between the guided generation and the user preferences. To address these issues, we propose Preference-aware ARM (PARM), a single unified ARM trained across all preference dimensions. PARM uses our proposed Preference-Aware Bilinear Low-Rank Adaptation (PBLoRA), which employs a bilinear form to condition the ARM on preference vectors, enabling it to achieve precise control over preference trade-offs during inference. Experiments demonstrate that PARM reduces inference costs and achieves better alignment with preference vectors compared with existing methods. Additionally, PARM enables weak-to-strong guidance, allowing a smaller PARM to guide a larger frozen LLM without expensive training, making multi-objective alignment accessible with limited computing resources. The code is available at https://github.com/Baijiong-Lin/PARM.
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
Jan 19, 2025



Multi-objective optimization (MOO) in deep learning aims to simultaneously optimize multiple conflicting objectives, a challenge frequently encountered in areas like multi-task learning and multi-criteria learning. Recent advancements in gradient-based MOO methods have enabled the discovery of diverse types of solutions, ranging from a single balanced solution to finite or even infinite Pareto sets, tailored to user needs. These developments have broad applications across domains such as reinforcement learning, computer vision, recommendation systems, and large language models. This survey provides the first comprehensive review of gradient-based MOO in deep learning, covering algorithms, theories, and practical applications. By unifying various approaches and identifying critical challenges, it serves as a foundational resource for driving innovation in this evolving field. A comprehensive list of MOO algorithms in deep learning is available at \url{https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning}.
RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models
Sep 30, 2024



Recent works show that assembling multiple off-the-shelf large language models (LLMs) can harness their complementary abilities. To achieve this, routing is a promising method, which learns a router to select the most suitable LLM for each query. However, existing routing models are ineffective when multiple LLMs perform well for a query. To address this problem, in this paper, we propose a method called query-based Router by Dual Contrastive learning (RouterDC). The RouterDC model consists of an encoder and LLM embeddings, and we propose two contrastive learning losses to train the RouterDC model. Experimental results show that RouterDC is effective in assembling LLMs and largely outperforms individual top-performing LLMs as well as existing routing methods on both in-distribution (+2.76\%) and out-of-distribution (+1.90\%) tasks. Source code is available at https://github.com/shuhao02/RouterDC.
MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders
Jul 02, 2024Multi-task dense scene understanding, which learns a model for multiple dense prediction tasks, has a wide range of application scenarios. Modeling long-range dependency and enhancing cross-task interactions are crucial to multi-task dense prediction. In this paper, we propose MTMamba, a novel Mamba-based architecture for multi-task scene understanding. It contains two types of core blocks: self-task Mamba (STM) block and cross-task Mamba (CTM) block. STM handles long-range dependency by leveraging Mamba, while CTM explicitly models task interactions to facilitate information exchange across tasks. Experiments on NYUDv2 and PASCAL-Context datasets demonstrate the superior performance of MTMamba over Transformer-based and CNN-based methods. Notably, on the PASCAL-Context dataset, MTMamba achieves improvements of +2.08, +5.01, and +4.90 over the previous best method in the tasks of semantic segmentation, human parsing, and object boundary detection, respectively. The code is available at \url{https://github.com/EnVision-Research/MTMamba}.
A First-Order Multi-Gradient Algorithm for Multi-Objective Bi-Level Optimization
Jan 17, 2024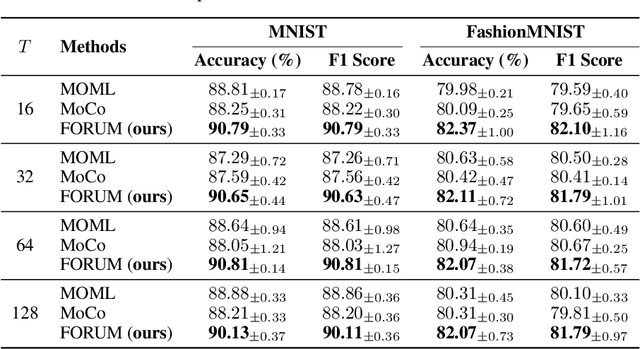



In this paper, we study the Multi-Objective Bi-Level Optimization (MOBLO) problem, where the upper-level subproblem is a multi-objective optimization problem and the lower-level subproblem is for scalar optimization. Existing gradient-based MOBLO algorithms need to compute the Hessian matrix, causing the computational inefficient problem. To address this, we propose an efficient first-order multi-gradient method for MOBLO, called FORUM. Specifically, we reformulate MOBLO problems as a constrained multi-objective optimization (MOO) problem via the value-function approach. Then we propose a novel multi-gradient aggregation method to solve the challenging constrained MOO problem. Theoretically, we provide the complexity analysis to show the efficiency of the proposed method and a non-asymptotic convergence result. Empirically, extensive experiments demonstrate the effectiveness and efficiency of the proposed FORUM method in different learning problems. In particular, it achieves state-of-the-art performance on three multi-task learning benchmark datasets.
Effective and Parameter-Efficient Reusing Fine-Tuned Models
Oct 04, 2023



Many pre-trained large-scale models provided online have become highly effective in transferring to downstream tasks. At the same time, various task-specific models fine-tuned on these pre-trained models are available online for public use. In practice, as collecting task-specific data is labor-intensive and fine-tuning the large pre-trained models is computationally expensive, one can reuse task-specific finetuned models to deal with downstream tasks. However, using a model per task causes a heavy burden on storage and serving. Recently, many training-free and parameter-efficient methods have been proposed for reusing multiple fine-tuned task-specific models into a single multi-task model. However, these methods exhibit a large accuracy gap compared with using a fine-tuned model per task. In this paper, we propose Parameter-Efficient methods for ReUsing (PERU) fine-tuned models. For reusing Fully Fine-Tuned (FFT) models, we propose PERU-FFT by injecting a sparse task vector into a merged model by magnitude pruning. For reusing LoRA fine-tuned models, we propose PERU-LoRA use a lower-rank matrix to approximate the LoRA matrix by singular value decomposition. Both PERUFFT and PERU-LoRA are training-free. Extensive experiments conducted on computer vision and natural language process tasks demonstrate the effectiveness and parameter-efficiency of the proposed methods. The proposed PERU-FFT and PERU-LoRA outperform existing reusing model methods by a large margin and achieve comparable performance to using a fine-tuned model per task.