 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Loss Weighting in Multi-Task Learning
Paper and Code
Nov 20, 2021
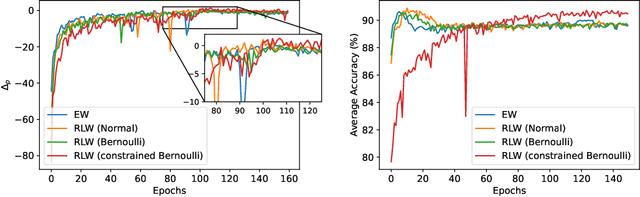

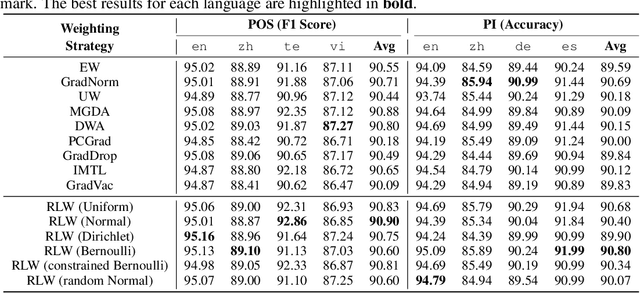
Multi-Task Learning (MTL) has achieved great success in various fields, however, how to balance different tasks to avoid negative effects is still a key problem. To achieve the task balancing, there exist many works to balance task losses or gradients. In this paper, we unify eight representative task balancing methods from the perspective of loss weighting and provide a consistent experimental comparison. Moreover, we surprisingly find that training a MTL model with random weights sampled from a distribution can achieve comparable performance over state-of-the-art baselines. Based on this finding, we propose a simple yet effective weighting strategy called Random Loss Weighting (RLW), which can be implemented in only one additional line of code over existing works. Theoretically, we analyze the convergence of RLW and reveal that RLW has a higher probability to escape local minima than existing models with fixed task weights, resulting in a better generalization ability. Empirically, we extensively evaluate the proposed RLW method on six image datasets and four multilingual tasks from the XTREME benchmark to show the effectiveness of the proposed RLW strategy when compared with state-of-the-art strategies.