 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with Relevance-Diversity Data Selection
May 27, 2026Fine-tuning large language models often undermines their safety alignment, a problem further amplified by harmful fine-tuning attacks in which adversarial data removes safeguards and induces unsafe behaviors. We propose SPARD, a defense framework that integrates Safety-Projected Alternating optimization with Relevance-Diversity aware data selection. SPARD employs SPAG, which optimizes alternatively between utility updates and explicit safety projections with a set of safe data to enforce safety constraints. To curate safe data, we introduce a Relevance-Diversity Determinantal Point Process to select compact safe data, balancing task relevance and safety coverage. Experiments on GSM8K and OpenBookQA under four harmful fine-tuning attacks demonstrate that SPARD consistently achieves the lowest average attack success rates, substantially outperforming state-of-the-art defense methods, while maintaining high task accuracy. Code is available at https://github.com/shuhao02/SPARD.
RxEval: A Prescription-Level Benchmark for Evaluating LLM Medication Recommendation
May 14, 2026Inpatient medication recommendation requires clinicians to repeatedly select specific medications, doses, and routes as a patient's condition evolves. Existing benchmarks formulate this task as admission-level prediction over coarse drug codes with multi-hot diagnostic and procedure code inputs, failing to capture the per-timepoint, information-rich nature of real prescribing. We propose RxEval, a prescription-level benchmark that evaluates LLM prescribing capability by multiple-choice questions: each question presents a detailed patient profile and time-ordered clinical trajectory, requiring selection of specific medication-dose-route triples from real prescriptions and patient-specific distractors generated via reasoning-chain perturbation. RxEval comprises 1,547 questions spanning 584 patients, 18 diagnostic categories, and 969 unique medications. Evaluation of 16 LLMs shows that RxEval is both challenging and discriminative: F1 ranges from 45.18 to 77.10 across models, and the best Exact Match is only 46.10%. Error analysis reveals that even frontier models may overlook stated patient information and fail to derive clinical conclusions.
MetaMoE: Diversity-Aware Proxy Selection for Privacy-Preserving Mixture-of-Experts Unification
May 14, 2026Mixture-of-Experts (MoE) models scale capacity by combining specialized experts, but most existing approaches assume centralized access to training data. In practice, data are distributed across clients and cannot be shared due to privacy constraints, making unified MoE training challenging. We propose MetaMoE, a privacy-preserving framework that unifies independently trained, domain-specialized experts into a single MoE using public proxy data as surrogates for inaccessible private data. Central to MetaMoE is diversity-aware proxy selection, which selects client-domain-relevant and diverse samples from public data to effectively approximate private data distributions and supervise router learning. These proxies are further used to align expert training, improving expert coordination at unification time, while a context-aware router enhances expert selection across heterogeneous inputs. Experiments on computer vision and natural language processing benchmarks demonstrate that MetaMoE consistently outperforms recent privacy-preserving MoE unification methods. Code is available at https://github.com/ws-jiang/MetaMoE.
MetaDefense: Defending Finetuning-based Jailbreak Attack Before and During Generation
Oct 09, 2025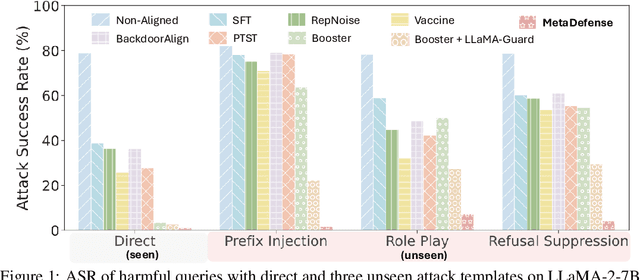


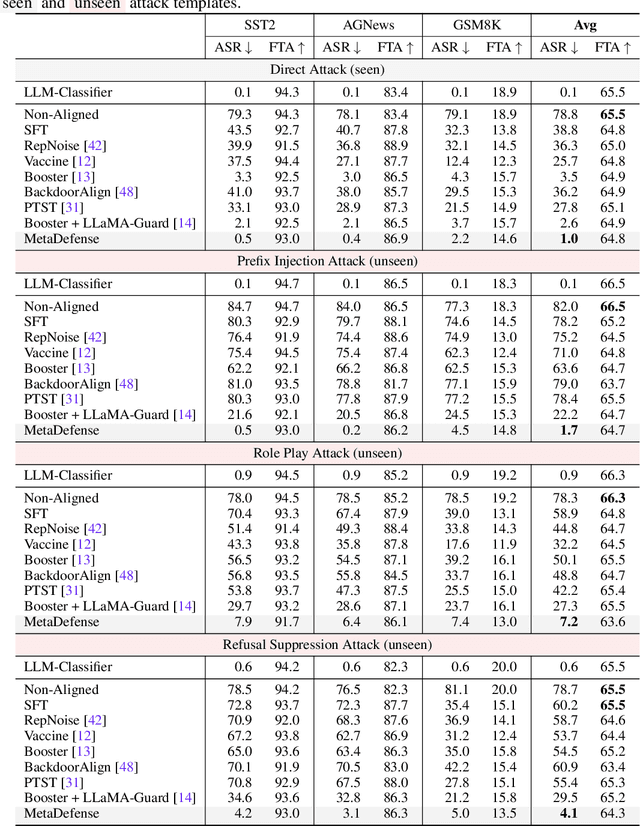
This paper introduces MetaDefense, a novel framework for defending against finetuning-based jailbreak attacks in large language models (LLMs). We observe that existing defense mechanisms fail to generalize to harmful queries disguised by unseen attack templates, despite LLMs being capable of distinguishing disguised harmful queries in the embedding space. Based on these insights, we propose a two-stage defense approach: (i) pre-generation defense that detects harmful queries before response generation begins, and (ii) mid-generation defense that monitors partial responses during generation to prevent outputting more harmful content. Our MetaDefense trains the LLM to predict the harmfulness of both queries and partial responses using specialized prompts, enabling early termination of potentially harmful interactions. Extensive experiments across multiple LLM architectures (LLaMA-2-7B, Qwen-2.5-3B-Instruct, and LLaMA-3.2-3B-Instruct) demonstrate that MetaDefense significantly outperforms existing defense mechanisms, achieving robust defense against harmful queries with seen and unseen attack templates while maintaining competitive performance on benign tasks. Code is available at https://github.com/ws-jiang/MetaDefense.
PARM: Multi-Objective Test-Time Alignment via Preference-Aware Autoregressive Reward Model
May 06, 2025



Multi-objective test-time alignment aims to adapt large language models (LLMs) to diverse multi-dimensional user preferences during inference while keeping LLMs frozen. Recently, GenARM (Xu et al., 2025) first independently trains Autoregressive Reward Models (ARMs) for each preference dimension without awareness of each other, then combines their outputs based on user-specific preference vectors during inference to achieve multi-objective test-time alignment, leading to two key limitations: the need for \textit{multiple} ARMs increases the inference cost, and the separate training of ARMs causes the misalignment between the guided generation and the user preferences. To address these issues, we propose Preference-aware ARM (PARM), a single unified ARM trained across all preference dimensions. PARM uses our proposed Preference-Aware Bilinear Low-Rank Adaptation (PBLoRA), which employs a bilinear form to condition the ARM on preference vectors, enabling it to achieve precise control over preference trade-offs during inference. Experiments demonstrate that PARM reduces inference costs and achieves better alignment with preference vectors compared with existing methods. Additionally, PARM enables weak-to-strong guidance, allowing a smaller PARM to guide a larger frozen LLM without expensive training, making multi-objective alignment accessible with limited computing resources. The code is available at https://github.com/Baijiong-Lin/PARM.
RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models
Sep 30, 2024



Recent works show that assembling multiple off-the-shelf large language models (LLMs) can harness their complementary abilities. To achieve this, routing is a promising method, which learns a router to select the most suitable LLM for each query. However, existing routing models are ineffective when multiple LLMs perform well for a query. To address this problem, in this paper, we propose a method called query-based Router by Dual Contrastive learning (RouterDC). The RouterDC model consists of an encoder and LLM embeddings, and we propose two contrastive learning losses to train the RouterDC model. Experimental results show that RouterDC is effective in assembling LLMs and largely outperforms individual top-performing LLMs as well as existing routing methods on both in-distribution (+2.76\%) and out-of-distribution (+1.90\%) tasks. Source code is available at https://github.com/shuhao02/RouterDC.
Enhancing Sharpness-Aware Minimization by Learning Perturbation Radius
Aug 15, 2024Sharpness-aware minimization (SAM) is to improve model generalization by searching for flat minima in the loss landscape. The SAM update consists of one step for computing the perturbation and the other for computing the update gradient. Within the two steps, the choice of the perturbation radius is crucial to the performance of SAM, but finding an appropriate perturbation radius is challenging. In this paper, we propose a bilevel optimization framework called LEarning the perTurbation radiuS (LETS) to learn the perturbation radius for sharpness-aware minimization algorithms. Specifically, in the proposed LETS method, the upper-level problem aims at seeking a good perturbation radius by minimizing the squared generalization gap between the training and validation losses, while the lower-level problem is the SAM optimization problem. Moreover, the LETS method can be combined with any variant of SAM. Experimental results on various architectures and benchmark datasets in computer vision and natural language processing demonstrate the effectiveness of the proposed LETS method in improving the performance of SAM.
Scalable Learned Model Soup on a Single GPU: An Efficient Subspace Training Strategy
Jul 04, 2024



Pre-training followed by fine-tuning is widely adopted among practitioners. The performance can be improved by "model soups"~\cite{wortsman2022model} via exploring various hyperparameter configurations.The Learned-Soup, a variant of model soups, significantly improves the performance but suffers from substantial memory and time costs due to the requirements of (i) having to load all fine-tuned models simultaneously, and (ii) a large computational graph encompassing all fine-tuned models. In this paper, we propose Memory Efficient Hyperplane Learned Soup (MEHL-Soup) to tackle this issue by formulating the learned soup as a hyperplane optimization problem and introducing block coordinate gradient descent to learn the mixing coefficients. At each iteration, MEHL-Soup only needs to load a few fine-tuned models and build a computational graph with one combined model. We further extend MEHL-Soup to MEHL-Soup+ in a layer-wise manner. Experimental results on various ViT models and data sets show that MEHL-Soup(+) outperforms Learned-Soup(+) in terms of test accuracy, and also reduces memory usage by more than $13\times$. Moreover, MEHL-Soup(+) can be run on a single GPU and achieves $9\times$ speed up in soup construction compared with the Learned-Soup. The code is released at https://github.com/nblt/MEHL-Soup.
MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders
Jul 02, 2024Multi-task dense scene understanding, which learns a model for multiple dense prediction tasks, has a wide range of application scenarios. Modeling long-range dependency and enhancing cross-task interactions are crucial to multi-task dense prediction. In this paper, we propose MTMamba, a novel Mamba-based architecture for multi-task scene understanding. It contains two types of core blocks: self-task Mamba (STM) block and cross-task Mamba (CTM) block. STM handles long-range dependency by leveraging Mamba, while CTM explicitly models task interactions to facilitate information exchange across tasks. Experiments on NYUDv2 and PASCAL-Context datasets demonstrate the superior performance of MTMamba over Transformer-based and CNN-based methods. Notably, on the PASCAL-Context dataset, MTMamba achieves improvements of +2.08, +5.01, and +4.90 over the previous best method in the tasks of semantic segmentation, human parsing, and object boundary detection, respectively. The code is available at \url{https://github.com/EnVision-Research/MTMamba}.
Rendering Graphs for Graph Reasoning in Multimodal Large Language Models
Feb 03, 2024Large Language Models (LLMs) are increasingly used for various tasks with graph structures, such as robotic planning, knowledge graph completion, and common-sense reasoning. Though LLMs can comprehend graph information in a textual format, they overlook the rich visual modality, which is an intuitive way for humans to comprehend structural information and conduct graph reasoning. The potential benefits and capabilities of representing graph structures as visual images (i.e., visual graph) is still unexplored. In this paper, we take the first step in incorporating visual information into graph reasoning tasks and propose a new benchmark GITQA, where each sample is a tuple (graph, image, textual description). We conduct extensive experiments on the GITQA benchmark using state-of-the-art multimodal LLMs. Results on graph reasoning tasks show that combining textual and visual information together performs better than using one modality alone. Moreover, the LLaVA-7B/13B models finetuned on the training set achieve higher accuracy than the closed-source model GPT-4(V). We also study the effects of augmentations in graph reasoning.