 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Action Head: Confining Task Knowledge to Conditioning Layers
Nov 15, 2025Behavior Cloning (BC) is a data-driven supervised learning approach that has gained increasing attention with the success of scaling laws in language and vision domains. Among its implementations in robotic manipulation, Diffusion Policy (DP), with its two variants DP-CNN (DP-C) and DP-Transformer (DP-T), is one of the most effective and widely adopted models, demonstrating the advantages of predicting continuous action sequences. However, both DP and other BC methods remain constrained by the scarcity of paired training data, and the internal mechanisms underlying DP's effectiveness remain insufficiently understood, leading to limited generalization and a lack of principled design in model development. In this work, we propose a decoupled training recipe that leverages nearly cost-free kinematics-generated trajectories as observation-free data to pretrain a general action head (action generator). The pretrained action head is then frozen and adapted to novel tasks through feature modulation. Our experiments demonstrate the feasibility of this approach in both in-distribution and out-of-distribution scenarios. As an additional benefit, decoupling improves training efficiency; for instance, DP-C achieves up to a 41% speedup. Furthermore, the confinement of task-specific knowledge to the conditioning components under decoupling, combined with the near-identical performance of DP-C in both normal and decoupled training, indicates that the action generation backbone plays a limited role in robotic manipulation. Motivated by this observation, we introduce DP-MLP, which replaces the 244M-parameter U-Net backbone of DP-C with only 4M parameters of simple MLP blocks, achieving a 83.9% faster training speed under normal training and 89.1% under decoupling.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.
MoPD: Mixture-of-Prompts Distillation for Vision-Language Models
Dec 26, 2024Soft prompt learning methods are effective for adapting vision-language models (VLMs) to downstream tasks. Nevertheless, empirical evidence reveals a tendency of existing methods that they overfit seen classes and exhibit degraded performance on unseen classes. This limitation is due to the inherent bias in the training data towards the seen classes. To address this issue, we propose a novel soft prompt learning method, named Mixture-of-Prompts Distillation (MoPD), which can effectively transfer useful knowledge from hard prompts manually hand-crafted (a.k.a. teacher prompts) to the learnable soft prompt (a.k.a. student prompt), thereby enhancing the generalization ability of soft prompts on unseen classes. Moreover, the proposed MoPD method utilizes a gating network that learns to select hard prompts used for prompt distillation. Extensive experiments demonstrate that the proposed MoPD method outperforms state-of-the-art baselines especially on on unseen classes.
Nemesis: Normalizing the Soft-prompt Vectors of Vision-Language Models
Aug 26, 2024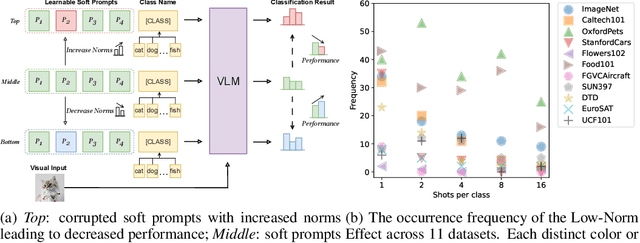
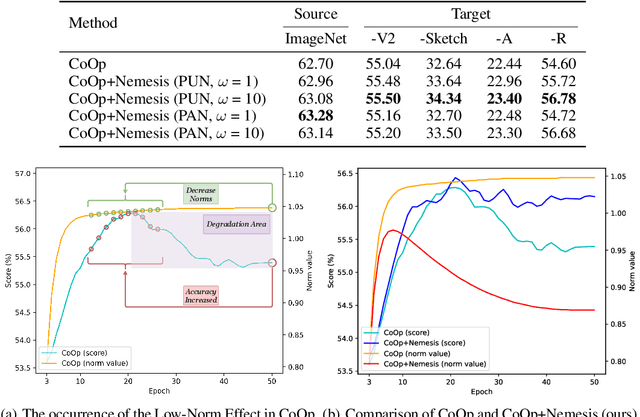
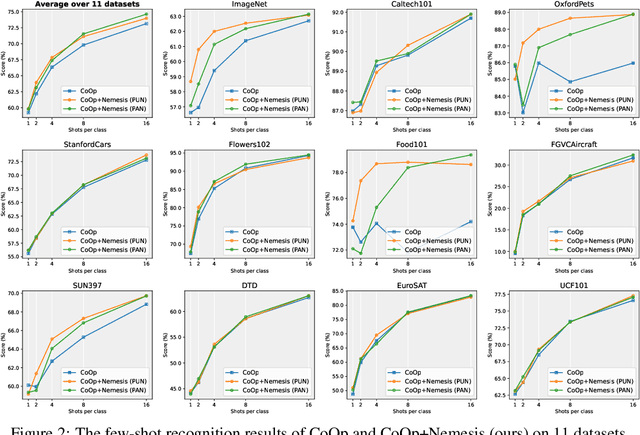
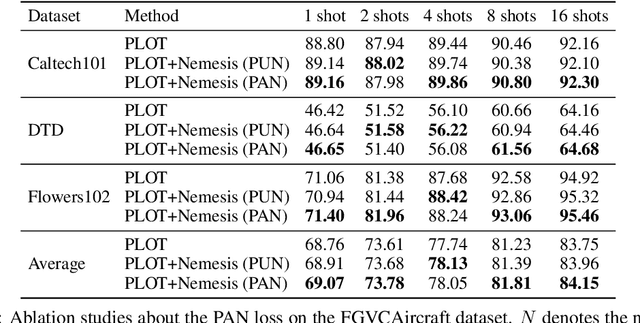
With the prevalence of large-scale pretrained vision-language models (VLMs), such as CLIP, soft-prompt tuning has become a popular method for adapting these models to various downstream tasks. However, few works delve into the inherent properties of learnable soft-prompt vectors, specifically the impact of their norms to the performance of VLMs. This motivates us to pose an unexplored research question: ``Do we need to normalize the soft prompts in VLMs?'' To fill this research gap, we first uncover a phenomenon, called the \textbf{Low-Norm Effect} by performing extensive corruption experiments, suggesting that reducing the norms of certain learned prompts occasionally enhances the performance of VLMs, while increasing them often degrades it. To harness this effect, we propose a novel method named \textbf{N}ormalizing th\textbf{e} soft-pro\textbf{m}pt v\textbf{e}ctors of vi\textbf{si}on-language model\textbf{s} (\textbf{Nemesis}) to normalize soft-prompt vectors in VLMs. To the best of our knowledge, our work is the first to systematically investigate the role of norms of soft-prompt vector in VLMs, offering valuable insights for future research in soft-prompt tuning. The code is available at \texttt{\href{https://github.com/ShyFoo/Nemesis}{https://github.com/ShyFoo/Nemesis}}.
Enhancing Sharpness-Aware Minimization by Learning Perturbation Radius
Aug 15, 2024Sharpness-aware minimization (SAM) is to improve model generalization by searching for flat minima in the loss landscape. The SAM update consists of one step for computing the perturbation and the other for computing the update gradient. Within the two steps, the choice of the perturbation radius is crucial to the performance of SAM, but finding an appropriate perturbation radius is challenging. In this paper, we propose a bilevel optimization framework called LEarning the perTurbation radiuS (LETS) to learn the perturbation radius for sharpness-aware minimization algorithms. Specifically, in the proposed LETS method, the upper-level problem aims at seeking a good perturbation radius by minimizing the squared generalization gap between the training and validation losses, while the lower-level problem is the SAM optimization problem. Moreover, the LETS method can be combined with any variant of SAM. Experimental results on various architectures and benchmark datasets in computer vision and natural language processing demonstrate the effectiveness of the proposed LETS method in improving the performance of SAM.
Learning Retrieval Augmentation for Personalized Dialogue Generation
Jun 27, 2024Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applications. However, persona profiles, a prevalent setting in current personalized dialogue datasets, typically composed of merely four to five sentences, may not offer comprehensive descriptions of the persona about the agent, posing a challenge to generate truly personalized dialogues. To handle this problem, we propose $\textbf{L}$earning Retrieval $\textbf{A}$ugmentation for $\textbf{P}$ersonalized $\textbf{D}$ial$\textbf{O}$gue $\textbf{G}$eneration ($\textbf{LAPDOG}$), which studies the potential of leveraging external knowledge for persona dialogue generation. Specifically, the proposed LAPDOG model consists of a story retriever and a dialogue generator. The story retriever uses a given persona profile as queries to retrieve relevant information from the story document, which serves as a supplementary context to augment the persona profile. The dialogue generator utilizes both the dialogue history and the augmented persona profile to generate personalized responses. For optimization, we adopt a joint training framework that collaboratively learns the story retriever and dialogue generator, where the story retriever is optimized towards desired ultimate metrics (e.g., BLEU) to retrieve content for the dialogue generator to generate personalized responses. Experiments conducted on the CONVAI2 dataset with ROCStory as a supplementary data source show that the proposed LAPDOG method substantially outperforms the baselines, indicating the effectiveness of the proposed method. The LAPDOG model code is publicly available for further exploration. https://github.com/hqsiswiliam/LAPDOG
Rendering Graphs for Graph Reasoning in Multimodal Large Language Models
Feb 03, 2024Large Language Models (LLMs) are increasingly used for various tasks with graph structures, such as robotic planning, knowledge graph completion, and common-sense reasoning. Though LLMs can comprehend graph information in a textual format, they overlook the rich visual modality, which is an intuitive way for humans to comprehend structural information and conduct graph reasoning. The potential benefits and capabilities of representing graph structures as visual images (i.e., visual graph) is still unexplored. In this paper, we take the first step in incorporating visual information into graph reasoning tasks and propose a new benchmark GITQA, where each sample is a tuple (graph, image, textual description). We conduct extensive experiments on the GITQA benchmark using state-of-the-art multimodal LLMs. Results on graph reasoning tasks show that combining textual and visual information together performs better than using one modality alone. Moreover, the LLaVA-7B/13B models finetuned on the training set achieve higher accuracy than the closed-source model GPT-4(V). We also study the effects of augmentations in graph reasoning.
Does Misclassifying Non-confounding Covariates as Confounders Affect the Causal Inference within the Potential Outcomes Framework?
Sep 05, 2023The Potential Outcome Framework (POF) plays a prominent role in the field of causal inference. Most causal inference models based on the POF (CIMs-POF) are designed for eliminating confounding bias and default to an underlying assumption of Confounding Covariates. This assumption posits that the covariates consist solely of confounders. However, the assumption of Confounding Covariates is challenging to maintain in practice, particularly when dealing with high-dimensional covariates. While certain methods have been proposed to differentiate the distinct components of covariates prior to conducting causal inference, the consequences of treating non-confounding covariates as confounders remain unclear. This ambiguity poses a potential risk when conducting causal inference in practical scenarios. In this paper, we present a unified graphical framework for the CIMs-POF, which greatly enhances the comprehension of these models' underlying principles. Using this graphical framework, we quantitatively analyze the extent to which the inference performance of CIMs-POF is influenced when incorporating various types of non-confounding covariates, such as instrumental variables, mediators, colliders, and adjustment variables. The key findings are: in the task of eliminating confounding bias, the optimal scenario is for the covariates to exclusively encompass confounders; in the subsequent task of inferring counterfactual outcomes, the adjustment variables contribute to more accurate inferences. Furthermore, extensive experiments conducted on synthetic datasets consistently validate these theoretical conclusions.