 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Token Verification for Reasoning Correctness Estimation
Mar 01, 2026Recent breakthroughs in large language models (LLMs) have led to notable successes in complex reasoning tasks, such as mathematical problem solving. A common strategy for improving performance is parallel thinking, in which multiple reasoning traces are generated and the final prediction is made using aggregation schemes like majority voting or best-of-$N$ decoding. However, two key challenges persist. First, multi-sample decoding incurs substantial inference latency, especially for long-form outputs. Second, effective mechanisms for reliably assessing the correctness of individual reasoning traces are still limited. To address these challenges, we introduce One-Token Verification (OTV), a computational method that estimates reasoning correctness in a single forward pass during generation. OTV is activated by a learnable token and integrated into the LLM via low-rank adaptation to probe internal reasoning signals through the key-value cache, supporting token-level correctness estimation at any stage of generation without disrupting primary reasoning. Experiments on mathematical reasoning benchmarks demonstrate that OTV consistently surpasses existing verifiers. Additionally, OTV reduces token usage by up to $90\%$ through correctness-guided early termination, prioritizing shorter, more reliable solutions.
Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
Jun 06, 2025Low-rank adaptation (LoRA) has emerged as a leading parameter-efficient fine-tuning technique for adapting large foundation models, yet it often locks adapters into suboptimal minima near their initialization. This hampers model generalization and limits downstream operators such as adapter merging and pruning. Here, we propose CoTo, a progressive training strategy that gradually increases adapters' activation probability over the course of fine-tuning. By stochastically deactivating adapters, CoTo encourages more balanced optimization and broader exploration of the loss landscape. We provide a theoretical analysis showing that CoTo promotes layer-wise dropout stability and linear mode connectivity, and we adopt a cooperative-game approach to quantify each adapter's marginal contribution. Extensive experiments demonstrate that CoTo consistently boosts single-task performance, enhances multi-task merging accuracy, improves pruning robustness, and reduces training overhead, all while remaining compatible with diverse LoRA variants. Code is available at https://github.com/zwebzone/coto.
CopRA: A Progressive LoRA Training Strategy
Oct 30, 2024



Low-Rank Adaptation (LoRA) is a parameter-efficient technique for rapidly fine-tuning foundation models. In standard LoRA training dynamics, models tend to quickly converge to a local optimum near the initialization. However, this local optimum may not be ideal for out-of-distribution data or tasks such as merging and pruning. In this work, we propose a novel progressive training strategy for LoRA with random layer dropping. This strategy also optimizes the Shapley value of LoRA parameters in each layer, treating each layer as a player in a cooperative game. We refer to this method as Cooperative LoRA (CopRA). Our experimental results demonstrate that parameters trained with CopRA exhibit linear mode connectivity, which enables efficient model merging. This also paves the way for federated learning and multi-task learning via LoRA merging. Additionally, by optimizing the Shapley value, CopRA shows superior performance in pruning tasks.
Nemesis: Normalizing the Soft-prompt Vectors of Vision-Language Models
Aug 26, 2024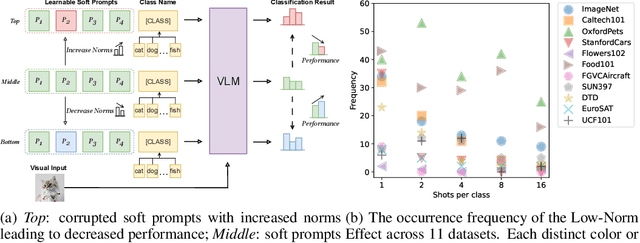
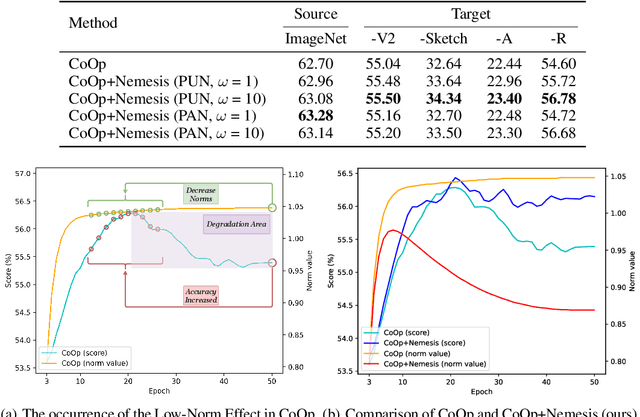
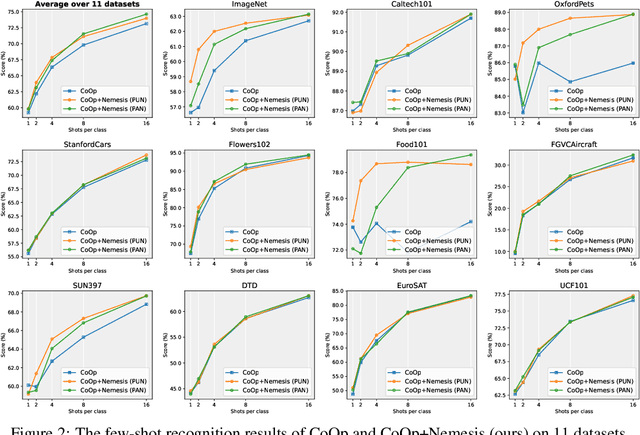
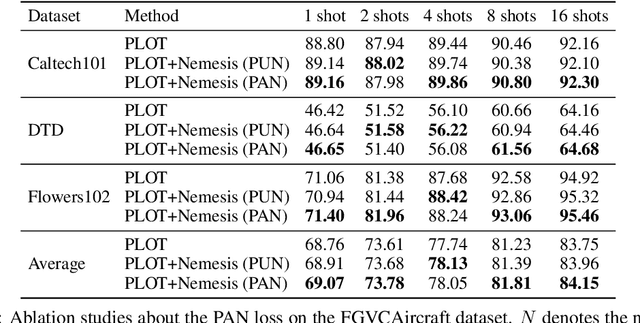
With the prevalence of large-scale pretrained vision-language models (VLMs), such as CLIP, soft-prompt tuning has become a popular method for adapting these models to various downstream tasks. However, few works delve into the inherent properties of learnable soft-prompt vectors, specifically the impact of their norms to the performance of VLMs. This motivates us to pose an unexplored research question: ``Do we need to normalize the soft prompts in VLMs?'' To fill this research gap, we first uncover a phenomenon, called the \textbf{Low-Norm Effect} by performing extensive corruption experiments, suggesting that reducing the norms of certain learned prompts occasionally enhances the performance of VLMs, while increasing them often degrades it. To harness this effect, we propose a novel method named \textbf{N}ormalizing th\textbf{e} soft-pro\textbf{m}pt v\textbf{e}ctors of vi\textbf{si}on-language model\textbf{s} (\textbf{Nemesis}) to normalize soft-prompt vectors in VLMs. To the best of our knowledge, our work is the first to systematically investigate the role of norms of soft-prompt vector in VLMs, offering valuable insights for future research in soft-prompt tuning. The code is available at \texttt{\href{https://github.com/ShyFoo/Nemesis}{https://github.com/ShyFoo/Nemesis}}.