 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAD: Heterogeneity-Aware Distillation for Lifelong Heterogeneous Learning
Mar 27, 2026Lifelong learning aims to preserve knowledge acquired from previous tasks while incorporating knowledge from a sequence of new tasks. However, most prior work explores only streams of homogeneous tasks (\textit{e.g.}, only classification tasks) and neglects the scenario of learning across heterogeneous tasks that possess different structures of outputs. In this work, we formalize this broader setting as lifelong heterogeneous learning (LHL). Departing from conventional lifelong learning, the task sequence of LHL spans different task types, and the learner needs to retain heterogeneous knowledge for different output space structures. To instantiate the LHL, we focus on LHL in the context of dense prediction (LHL4DP), a realistic and challenging scenario. To this end, we propose the Heterogeneity-Aware Distillation (HAD) method, an exemplar-free approach that preserves previously gained heterogeneous knowledge by self-distillation in each training phase. The proposed HAD comprises two complementary components, including a distribution-balanced heterogeneity-aware distillation loss to alleviate the global imbalance of prediction distribution and a salience-guided heterogeneity-aware distillation loss that concentrates learning on informative edge pixels extracted with the Sobel operator. Extensive experiments demonstrate that the proposed HAD method significantly outperforms existing methods in this new scenario.
Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
Jun 06, 2025Low-rank adaptation (LoRA) has emerged as a leading parameter-efficient fine-tuning technique for adapting large foundation models, yet it often locks adapters into suboptimal minima near their initialization. This hampers model generalization and limits downstream operators such as adapter merging and pruning. Here, we propose CoTo, a progressive training strategy that gradually increases adapters' activation probability over the course of fine-tuning. By stochastically deactivating adapters, CoTo encourages more balanced optimization and broader exploration of the loss landscape. We provide a theoretical analysis showing that CoTo promotes layer-wise dropout stability and linear mode connectivity, and we adopt a cooperative-game approach to quantify each adapter's marginal contribution. Extensive experiments demonstrate that CoTo consistently boosts single-task performance, enhances multi-task merging accuracy, improves pruning robustness, and reduces training overhead, all while remaining compatible with diverse LoRA variants. Code is available at https://github.com/zwebzone/coto.
MoPFormer: Motion-Primitive Transformer for Wearable-Sensor Activity Recognition
May 27, 2025Human Activity Recognition (HAR) with wearable sensors is challenged by limited interpretability, which significantly impacts cross-dataset generalization. To address this challenge, we propose Motion-Primitive Transformer (MoPFormer), a novel self-supervised framework that enhances interpretability by tokenizing inertial measurement unit signals into semantically meaningful motion primitives and leverages a Transformer architecture to learn rich temporal representations. MoPFormer comprises two-stages. first stage is to partition multi-channel sensor streams into short segments and quantizing them into discrete "motion primitive" codewords, while the second stage enriches those tokenized sequences through a context-aware embedding module and then processes them with a Transformer encoder. The proposed MoPFormer can be pre-trained using a masked motion-modeling objective that reconstructs missing primitives, enabling it to develop robust representations across diverse sensor configurations. Experiments on six HAR benchmarks demonstrate that MoPFormer not only outperforms state-of-the-art methods but also successfully generalizes across multiple datasets. Most importantly, the learned motion primitives significantly enhance both interpretability and cross-dataset performance by capturing fundamental movement patterns that remain consistent across similar activities regardless of dataset origin.
Open the Eyes of MPNN: Vision Enhances MPNN in Link Prediction
May 13, 2025Message-passing graph neural networks (MPNNs) and structural features (SFs) are cornerstones for the link prediction task. However, as a common and intuitive mode of understanding, the potential of visual perception has been overlooked in the MPNN community. For the first time, we equip MPNNs with vision structural awareness by proposing an effective framework called Graph Vision Network (GVN), along with a more efficient variant (E-GVN). Extensive empirical results demonstrate that with the proposed frameworks, GVN consistently benefits from the vision enhancement across seven link prediction datasets, including challenging large-scale graphs. Such improvements are compatible with existing state-of-the-art (SOTA) methods and GVNs achieve new SOTA results, thereby underscoring a promising novel direction for link prediction.
Sharpness-Aware Black-Box Optimization
Oct 16, 2024
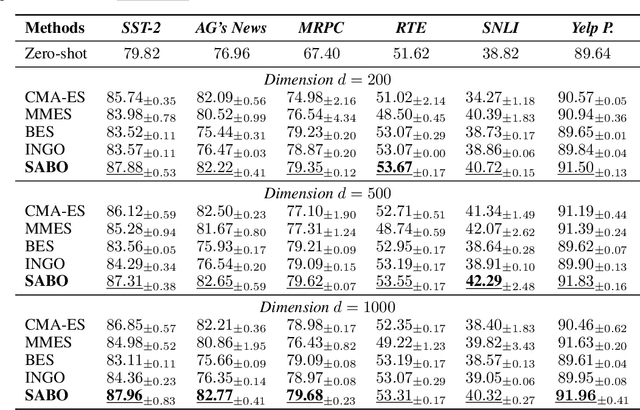


Black-box optimization algorithms have been widely used in various machine learning problems, including reinforcement learning and prompt fine-tuning. However, directly optimizing the training loss value, as commonly done in existing black-box optimization methods, could lead to suboptimal model quality and generalization performance. To address those problems in black-box optimization, we propose a novel Sharpness-Aware Black-box Optimization (SABO) algorithm, which applies a sharpness-aware minimization strategy to improve the model generalization. Specifically, the proposed SABO method first reparameterizes the objective function by its expectation over a Gaussian distribution. Then it iteratively updates the parameterized distribution by approximated stochastic gradients of the maximum objective value within a small neighborhood around the current solution in the Gaussian distribution space. Theoretically, we prove the convergence rate and generalization bound of the proposed SABO algorithm. Empirically, extensive experiments on the black-box prompt fine-tuning tasks demonstrate the effectiveness of the proposed SABO method in improving model generalization performance.
Enhancing Sharpness-Aware Minimization by Learning Perturbation Radius
Aug 15, 2024Sharpness-aware minimization (SAM) is to improve model generalization by searching for flat minima in the loss landscape. The SAM update consists of one step for computing the perturbation and the other for computing the update gradient. Within the two steps, the choice of the perturbation radius is crucial to the performance of SAM, but finding an appropriate perturbation radius is challenging. In this paper, we propose a bilevel optimization framework called LEarning the perTurbation radiuS (LETS) to learn the perturbation radius for sharpness-aware minimization algorithms. Specifically, in the proposed LETS method, the upper-level problem aims at seeking a good perturbation radius by minimizing the squared generalization gap between the training and validation losses, while the lower-level problem is the SAM optimization problem. Moreover, the LETS method can be combined with any variant of SAM. Experimental results on various architectures and benchmark datasets in computer vision and natural language processing demonstrate the effectiveness of the proposed LETS method in improving the performance of SAM.
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.
Knowing Depth Quality In Advance: A Depth Quality Assessment Method For RGB-D Salient Object Detection
Aug 07, 2020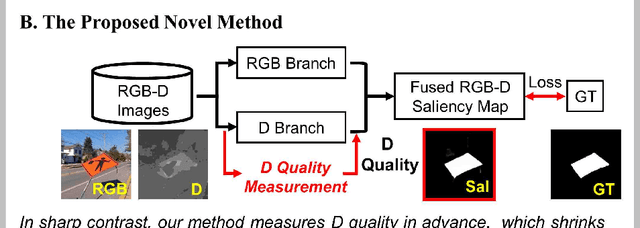
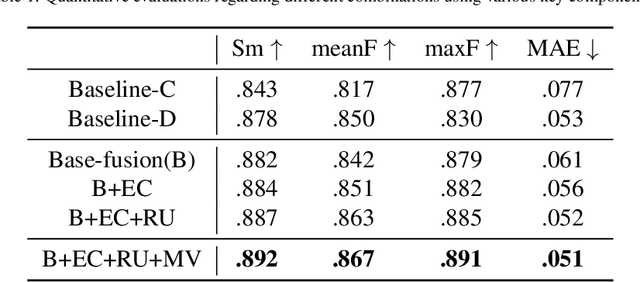
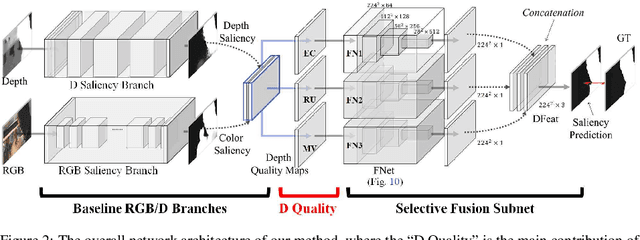
Previous RGB-D salient object detection (SOD) methods have widely adopted deep learning tools to automatically strike a trade-off between RGB and D (depth), whose key rationale is to take full advantage of their complementary nature, aiming for a much-improved SOD performance than that of using either of them solely. However, such fully automatic fusions may not always be helpful for the SOD task because the D quality itself usually varies from scene to scene. It may easily lead to a suboptimal fusion result if the D quality is not considered beforehand. Moreover, as an objective factor, the D quality has long been overlooked by previous work. As a result, it is becoming a clear performance bottleneck. Thus, we propose a simple yet effective scheme to measure D quality in advance, the key idea of which is to devise a series of features in accordance with the common attributes of high-quality D regions. To be more concrete, we conduct D quality assessments for each image region, following a multi-scale methodology that includes low-level edge consistency, mid-level regional uncertainty and high-level model variance. All these components will be computed independently and then be assembled with RGB and D features, applied as implicit indicators, to guide the selective fusion. Compared with the state-of-the-art fusion schemes, our method can achieve a more reasonable fusion status between RGB and D. Specifically, the proposed D quality measurement method achieves steady performance improvements for almost 2.0\% in general.
Data-Level Recombination and Lightweight Fusion Scheme for RGB-D Salient Object Detection
Aug 07, 2020
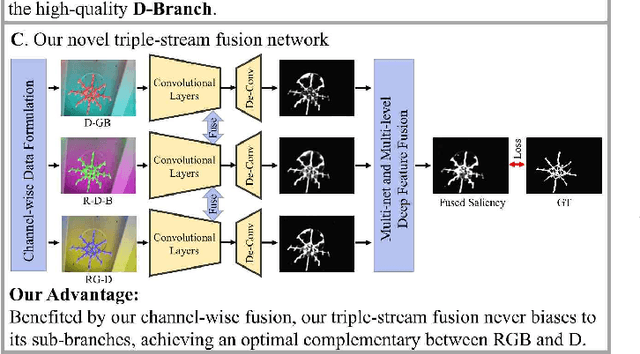

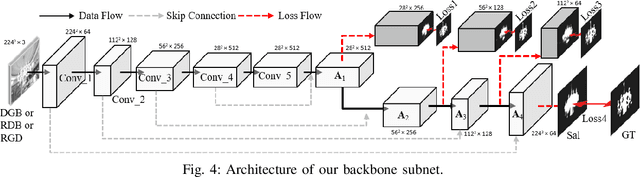
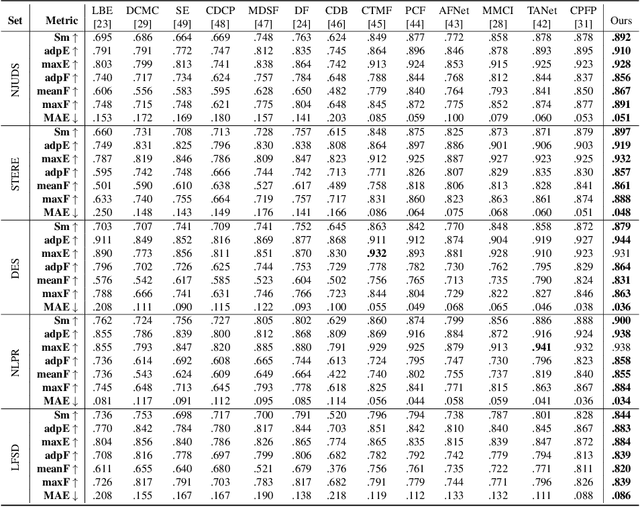
Existing RGB-D salient object detection methods treat depth information as an independent component to complement its RGB part, and widely follow the bi-stream parallel network architecture. To selectively fuse the CNNs features extracted from both RGB and depth as a final result, the state-of-the-art (SOTA) bi-stream networks usually consist of two independent subbranches; i.e., one subbranch is used for RGB saliency and the other aims for depth saliency. However, its depth saliency is persistently inferior to the RGB saliency because the RGB component is intrinsically more informative than the depth component. The bi-stream architecture easily biases its subsequent fusion procedure to the RGB subbranch, leading to a performance bottleneck. In this paper, we propose a novel data-level recombination strategy to fuse RGB with D (depth) before deep feature extraction, where we cyclically convert the original 4-dimensional RGB-D into \textbf{D}GB, R\textbf{D}B and RG\textbf{D}. Then, a newly lightweight designed triple-stream network is applied over these novel formulated data to achieve an optimal channel-wise complementary fusion status between the RGB and D, achieving a new SOTA performance.