 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Level Recombination and Lightweight Fusion Scheme for RGB-D Salient Object Detection
Paper and Code

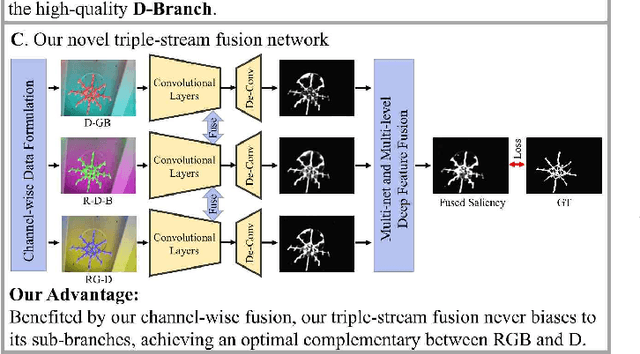

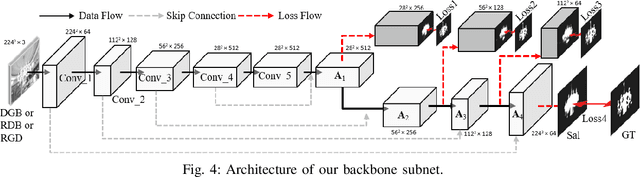
Existing RGB-D salient object detection methods treat depth information as an independent component to complement its RGB part, and widely follow the bi-stream parallel network architecture. To selectively fuse the CNNs features extracted from both RGB and depth as a final result, the state-of-the-art (SOTA) bi-stream networks usually consist of two independent subbranches; i.e., one subbranch is used for RGB saliency and the other aims for depth saliency. However, its depth saliency is persistently inferior to the RGB saliency because the RGB component is intrinsically more informative than the depth component. The bi-stream architecture easily biases its subsequent fusion procedure to the RGB subbranch, leading to a performance bottleneck. In this paper, we propose a novel data-level recombination strategy to fuse RGB with D (depth) before deep feature extraction, where we cyclically convert the original 4-dimensional RGB-D into \textbf{D}GB, R\textbf{D}B and RG\textbf{D}. Then, a newly lightweight designed triple-stream network is applied over these novel formulated data to achieve an optimal channel-wise complementary fusion status between the RGB and D, achieving a new SOTA performance.