 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Guidance Information to Utilize Unlabeled Samples:A Label Encoding Perspective
Jun 05, 2024



Empirical Risk Minimization (ERM) is fragile in scenarios with insufficient labeled samples. A vanilla extension of ERM to unlabeled samples is Entropy Minimization (EntMin), which employs the soft-labels of unlabeled samples to guide their learning. However, EntMin emphasizes prediction discriminability while neglecting prediction diversity. To alleviate this issue, in this paper, we rethink the guidance information to utilize unlabeled samples. By analyzing the learning objective of ERM, we find that the guidance information for labeled samples in a specific category is the corresponding label encoding. Inspired by this finding, we propose a Label-Encoding Risk Minimization (LERM). It first estimates the label encodings through prediction means of unlabeled samples and then aligns them with their corresponding ground-truth label encodings. As a result, the LERM ensures both prediction discriminability and diversity, and it can be integrated into existing methods as a plugin. Theoretically, we analyze the relationships between LERM and ERM as well as EntMin. Empirically, we verify the superiority of the LERM under several label insufficient scenarios. The codes are available at https://github.com/zhangyl660/LERM.
Large Language Models as Visual Cross-Domain Learners
Jan 06, 2024



Recent advances achieved by deep learning models rely on the independent and identically distributed assumption, hindering their applications in real-world scenarios with domain shifts. To address the above issues, cross-domain learning aims at extracting domain-invariant knowledge to reduce the domain shift between training and testing data. However, in visual cross-domain learning, traditional methods concentrate solely on the image modality, neglecting the use of the text modality to alleviate the domain shift. In this work, we propose Large Language models as Visual cross-dOmain learners (LLaVO). LLaVO uses vision-language models to convert images into detailed textual descriptions. A large language model is then finetuned on textual descriptions of the source/target domain generated by a designed instruction template. Extensive experimental results on various cross-domain tasks under the domain generalization and unsupervised domain adaptation settings have demonstrated the effectiveness of the proposed method.
Domain-Guided Conditional Diffusion Model for Unsupervised Domain Adaptation
Sep 23, 2023Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, Unsupervised Domain Adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, the performance of existing UDA methods is constrained by the large domain shift and limited target domain data. To alleviate these issues, we propose DomAin-guided Conditional Diffusion Model (DACDM) to generate high-fidelity and diversity samples for the target domain. In the proposed DACDM, by introducing class information, the labels of generated samples can be controlled, and a domain classifier is further introduced in DACDM to guide the generated samples for the target domain. The generated samples help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that DACDM brings a large improvement to the performance of existing UDA methods.
Diffusion-based Target Sampler for Unsupervised Domain Adaptation
Mar 17, 2023Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, unsupervised domain adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, large domain shifts and the sample scarcity in the target domain make existing UDA methods achieve suboptimal performance. To alleviate these issues, we propose a plug-and-play Diffusion-based Target Sampler (DTS) to generate high fidelity and diversity pseudo target samples. By introducing class-conditional information, the labels of the generated target samples can be controlled. The generated samples can well simulate the data distribution of the target domain and help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that the performance of existing UDA methods can be greatly improved through the proposed DTS method.
Query-free Black-box Adversarial Attacks on Graphs
Dec 12, 2020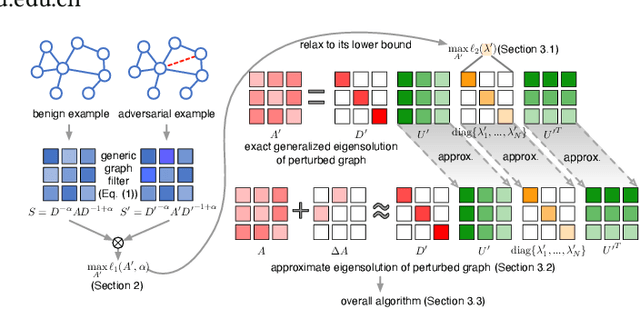
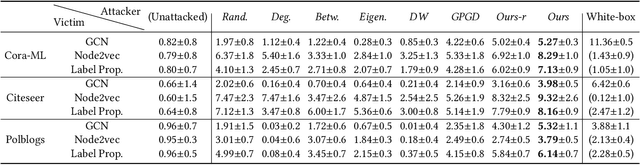
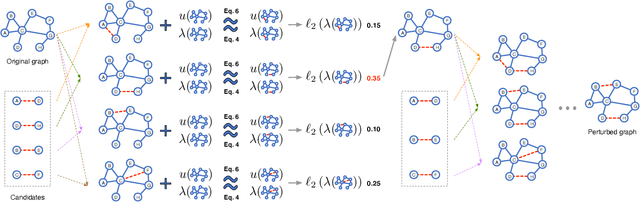

Many graph-based machine learning models are known to be vulnerable to adversarial attacks, where even limited perturbations on input data can result in dramatic performance deterioration. Most existing works focus on moderate settings in which the attacker is either aware of the model structure and parameters (white-box), or able to send queries to fetch model information. In this paper, we propose a query-free black-box adversarial attack on graphs, in which the attacker has no knowledge of the target model and no query access to the model. With the mere observation of the graph topology, the proposed attack strategy flips a limited number of links to mislead the graph models. We prove that the impact of the flipped links on the target model can be quantified by spectral changes, and thus be approximated using the eigenvalue perturbation theory. Accordingly, we model the proposed attack strategy as an optimization problem, and adopt a greedy algorithm to select the links to be flipped. Due to its simplicity and scalability, the proposed model is not only generic in various graph-based models, but can be easily extended when different knowledge levels are accessible as well. Extensive experiments demonstrate the effectiveness and efficiency of the proposed model on various downstream tasks, as well as several different graph-based learning models.
Unsupervised Adversarially-Robust Representation Learning on Graphs
Dec 04, 2020
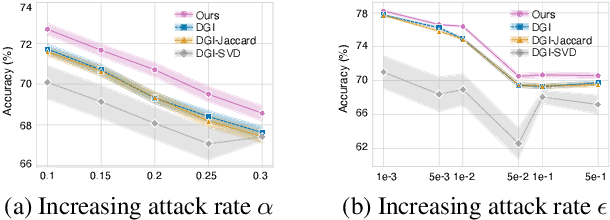
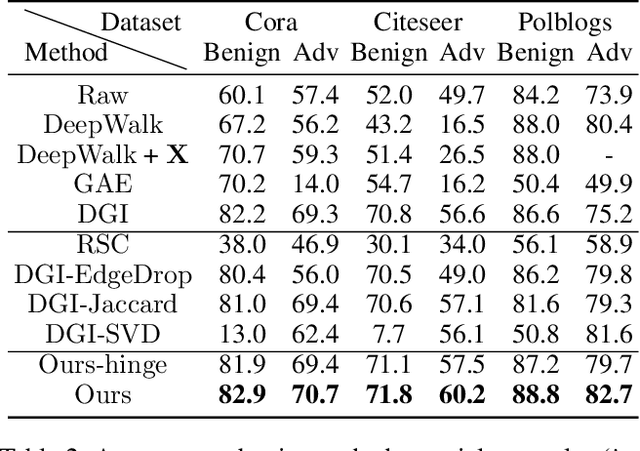

Recent works have demonstrated that deep learning on graphs is vulnerable to adversarial attacks, in that imperceptible perturbations on input data can lead to dramatic performance deterioration. In this paper, we focus on the underlying problem of learning robust representations on graphs via mutual information. In contrast to previous works measure the task-specific robustness based on the label space, we here take advantage of the representation space to study a task-free robustness measure given the joint input space w.r.t graph topology and node attributes. We formulate this problem as a constrained saddle point optimization problem and solve it efficiently in a reduced search space. Furthermore, we provably establish theoretical connections between our task-free robustness measure and the robustness of downstream classifiers. Extensive experiments demonstrate that our proposed method is able to enhance robustness against adversarial attacks on graphs, yet even increases natural accuracy.