 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Semantic Grounding in Image Editing Models for Zero-Shot Referring Image Segmentation
May 13, 2026Instruction-based image editing (IIE) models have recently demonstrated strong capability in modifying specific image regions according to natural language instructions, which implicitly requires identifying where an edit should be applied. This indicates that such models inherently perform language-conditioned visual semantic grounding. In this work, we investigate whether this implicit grounding can be leveraged for zero-shot referring image segmentation (RIS), a task that requires pixel-level localization of objects described by natural language expressions. Through systematic analysis, we reveal that strong foreground-background separability emerges in the internal representations of these models at the earliest denoising timestep, well before any visible image transformation occurs. Building on this insight, we propose a training-free framework that repurposes pretrained image editing models for RIS by exploiting their intermediate representations. Our approach decomposes localization into two complementary components: attention-based spatial priors that estimate where to focus, and feature-based semantic discrimination that determines what to segment. By leveraging feature-space separability, the framework produces accurate segmentation masks using only a single denoising step, without requiring full image synthesis. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg demonstrate that our method achieves superior performance over existing zero-shot baselines.
Beam Scheduling for Cross-Layer ISAC: A Deep Reinforcement Learning Approach
Apr 27, 2026Resource allocation in integrated sensing and communication (ISAC) systems needs to be optimized to balance the requirements of the communication and sensing modules considering complicated cross-layer data traffic and queue status in dynamic multi-user environments. This paper studies the beam allocation for cross-layer ISAC that achieves low-latency communication and minimizes sensing parameters estimation error. To handle the complex coupling between practical data buffer dynamics and varying wireless channels, we propose a deep reinforcement learning (DRL)-assisted approach. Rather than relying on explicit channel state information, the DRL-assisted beam allocation reduces feedback overhead by leveraging sensing observations. Simulation results verify that the DRL framework effectively takes buffer status into account and adapts to the wireless environment while allocating resources. The proposed multi-beam scheme improves overall throughput with only modest delay increases. Finally, the DRL-assisted beam management achieves both communication and sensing performance close to that of the genie-aided benchmark with perfect angle-of-departure (AoD) knowledge. These contributions advance the state-of-the-art intelligent resource management for ISAC systems.
Rethinking Where to Edit: Task-Aware Localization for Instruction-Based Image Editing
Apr 22, 2026Instruction-based image editing (IIE) aims to modify images according to textual instructions while preserving irrelevant content. Despite recent advances in diffusion transformers, existing methods often suffer from over-editing, introducing unintended changes to regions unrelated to the desired edit. We identify that this limitation arises from the lack of an explicit mechanism for edit localization. In particular, different editing operations (e.g., addition, removal and replacement) induce distinct spatial patterns, yet current IIE models typically treat localization in a task-agnostic manner. To address this limitation, we propose a training-free, task-aware edit localization framework that exploits the intrinsic source and target image streams within IIE models. For each image stream, We first obtain attention-based edit cues, and then construct feature centroids based on these attentive cues to partition tokens into edit and non-edit regions. Based on the observation that optimal localization is inherently task-dependent, we further introduce a unified mask construction strategy that selectively leverages source and target image streams for different editing tasks. We provide a systematic analysis for our proposed insights and approaches. Extensive experiments on EdiVal-Bench demonstrate our framework consistently improves non-edit region consistency while maintaining strong instruction-following performance on top of powerful recent image editing backbones, including Step1X-Edit and Qwen-Image-Edit.
Make Tracking Easy: Neural Motion Retargeting for Humanoid Whole-body Control
Mar 23, 2026Humanoid robots require diverse motor skills to integrate into complex environments, but bridging the kinematic and dynamic embodiment gap from human data remains a major bottleneck. We demonstrate through Hessian analysis that traditional optimization-based retargeting is inherently non-convex and prone to local optima, leading to physical artifacts like joint jumps and self-penetration. To address this, we reformulate the targeting problem as learning data distribution rather than optimizing optimal solutions, where we propose NMR, a Neural Motion Retargeting framework that transforms static geometric mapping into a dynamics-aware learned process. We first propose Clustered-Expert Physics Refinement (CEPR), a hierarchical data pipeline that leverages VAE-based motion clustering to group heterogeneous movements into latent motifs. This strategy significantly reduces the computational overhead of massively parallel reinforcement learning experts, which project and repair noisy human demonstrations onto the robot's feasible motion manifold. The resulting high-fidelity data supervises a non-autoregressive CNN-Transformer architecture that reasons over global temporal context to suppress reconstruction noise and bypass geometric traps. Experiments on the Unitree G1 humanoid across diverse dynamic tasks (e.g., martial arts, dancing) show that NMR eliminates joint jumps and significantly reduces self-collisions compared to state-of-the-art baselines. Furthermore, NMR-generated references accelerate the convergence of downstream whole-body control policies, establishing a scalable path for bridging the human-robot embodiment gap.
ICH-Qwen: A Large Language Model Towards Chinese Intangible Cultural Heritage
May 28, 2025



The intangible cultural heritage (ICH) of China, a cultural asset transmitted across generations by various ethnic groups, serves as a significant testament to the evolution of human civilization and holds irreplaceable value for the preservation of historical lineage and the enhancement of cultural self-confidence. However, the rapid pace of modernization poses formidable challenges to ICH, including threats damage, disappearance and discontinuity of inheritance. China has the highest number of items on the UNESCO Intangible Cultural Heritage List, which is indicative of the nation's abundant cultural resources and emphasises the pressing need for ICH preservation. In recent years, the rapid advancements in large language modelling have provided a novel technological approach for the preservation and dissemination of ICH. This study utilises a substantial corpus of open-source Chinese ICH data to develop a large language model, ICH-Qwen, for the ICH domain. The model employs natural language understanding and knowledge reasoning capabilities of large language models, augmented with synthetic data and fine-tuning techniques. The experimental results demonstrate the efficacy of ICH-Qwen in executing tasks specific to the ICH domain. It is anticipated that the model will provide intelligent solutions for the protection, inheritance and dissemination of intangible cultural heritage, as well as new theoretical and practical references for the sustainable development of intangible cultural heritage. Furthermore, it is expected that the study will open up new paths for digital humanities research.
Multi-User Beamforming with Deep Reinforcement Learning in Sensing-Aided Communication
May 09, 2025Mobile users are prone to experience beam failure due to beam drifting in millimeter wave (mmWave) communications. Sensing can help alleviate beam drifting with timely beam changes and low overhead since it does not need user feedback. This work studies the problem of optimizing sensing-aided communication by dynamically managing beams allocated to mobile users. A multi-beam scheme is introduced, which allocates multiple beams to the users that need an update on the angle of departure (AoD) estimates and a single beam to the users that have satisfied AoD estimation precision. A deep reinforcement learning (DRL) assisted method is developed to optimize the beam allocation policy, relying only upon the sensing echoes. For comparison, a heuristic AoD-based method using approximated Cram\'er-Rao lower bound (CRLB) for allocation is also presented. Both methods require neither user feedback nor prior state evolution information. Results show that the DRL-assisted method achieves a considerable gain in throughput than the conventional beam sweeping method and the AoD-based method, and it is robust to different user speeds.
Towards Robust and Reliable Concept Representations: Reliability-Enhanced Concept Embedding Model
Feb 03, 2025



Concept Bottleneck Models (CBMs) aim to enhance interpretability by predicting human-understandable concepts as intermediates for decision-making. However, these models often face challenges in ensuring reliable concept representations, which can propagate to downstream tasks and undermine robustness, especially under distribution shifts. Two inherent issues contribute to concept unreliability: sensitivity to concept-irrelevant features (e.g., background variations) and lack of semantic consistency for the same concept across different samples. To address these limitations, we propose the Reliability-Enhanced Concept Embedding Model (RECEM), which introduces a two-fold strategy: Concept-Level Disentanglement to separate irrelevant features from concept-relevant information and a Concept Mixup mechanism to ensure semantic alignment across samples. These mechanisms work together to improve concept reliability, enabling the model to focus on meaningful object attributes and generate faithful concept representations. Experimental results demonstrate that RECEM consistently outperforms existing baselines across multiple datasets, showing superior performance under background and domain shifts. These findings highlight the effectiveness of disentanglement and alignment strategies in enhancing both reliability and robustness in CBMs.
SoftShadow: Leveraging Penumbra-Aware Soft Masks for Shadow Removal
Sep 11, 2024
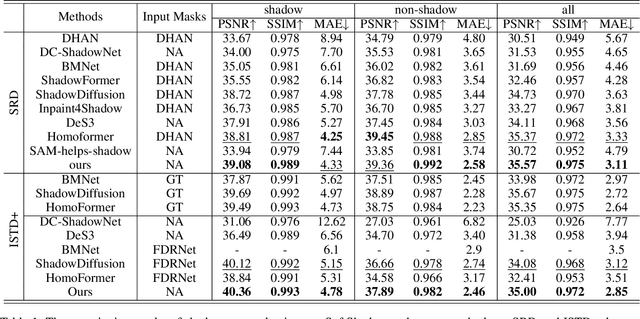
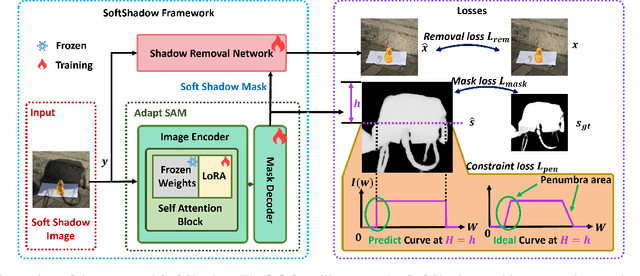
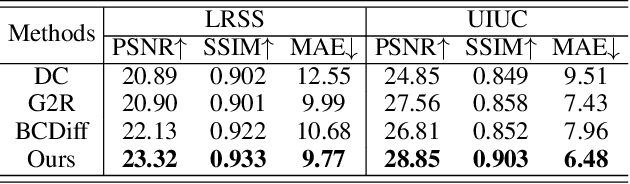
Recent advancements in deep learning have yielded promising results for the image shadow removal task. However, most existing methods rely on binary pre-generated shadow masks. The binary nature of such masks could potentially lead to artifacts near the boundary between shadow and non-shadow areas. In view of this, inspired by the physical model of shadow formation, we introduce novel soft shadow masks specifically designed for shadow removal. To achieve such soft masks, we propose a \textit{SoftShadow} framework by leveraging the prior knowledge of pretrained SAM and integrating physical constraints. Specifically, we jointly tune the SAM and the subsequent shadow removal network using penumbra formation constraint loss and shadow removal loss. This framework enables accurate predictions of penumbra (partially shaded regions) and umbra (fully shaded regions) areas while simultaneously facilitating end-to-end shadow removal. Through extensive experiments on popular datasets, we found that our SoftShadow framework, which generates soft masks, can better restore boundary artifacts, achieve state-of-the-art performance, and demonstrate superior generalizability.
Evolving Storytelling: Benchmarks and Methods for New Character Customization with Diffusion Models
May 20, 2024Diffusion-based models for story visualization have shown promise in generating content-coherent images for storytelling tasks. However, how to effectively integrate new characters into existing narratives while maintaining character consistency remains an open problem, particularly with limited data. Two major limitations hinder the progress: (1) the absence of a suitable benchmark due to potential character leakage and inconsistent text labeling, and (2) the challenge of distinguishing between new and old characters, leading to ambiguous results. To address these challenges, we introduce the NewEpisode benchmark, comprising refined datasets designed to evaluate generative models' adaptability in generating new stories with fresh characters using just a single example story. The refined dataset involves refined text prompts and eliminates character leakage. Additionally, to mitigate the character confusion of generated results, we propose EpicEvo, a method that customizes a diffusion-based visual story generation model with a single story featuring the new characters seamlessly integrating them into established character dynamics. EpicEvo introduces a novel adversarial character alignment module to align the generated images progressively in the diffusive process, with exemplar images of new characters, while applying knowledge distillation to prevent forgetting of characters and background details. Our evaluation quantitatively demonstrates that EpicEvo outperforms existing baselines on the NewEpisode benchmark, and qualitative studies confirm its superior customization of visual story generation in diffusion models. In summary, EpicEvo provides an effective way to incorporate new characters using only one example story, unlocking new possibilities for applications such as serialized cartoons.
Boosting Diffusion Models with an Adaptive Momentum Sampler
Aug 23, 2023



Diffusion probabilistic models (DPMs) have been shown to generate high-quality images without the need for delicate adversarial training. However, the current sampling process in DPMs is prone to violent shaking. In this paper, we present a novel reverse sampler for DPMs inspired by the widely-used Adam optimizer. Our proposed sampler can be readily applied to a pre-trained diffusion model, utilizing momentum mechanisms and adaptive updating to smooth the reverse sampling process and ensure stable generation, resulting in outputs of enhanced quality. By implicitly reusing update directions from early steps, our proposed sampler achieves a better balance between high-level semantics and low-level details. Additionally, this sampler is flexible and can be easily integrated into pre-trained DPMs regardless of the sampler used during training. Our experimental results on multiple benchmarks demonstrate that our proposed reverse sampler yields remarkable improvements over different baselines. We will make the source code available.