 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structure-Guided Diffusion Model for 2D Human Pose Estimation
Jun 29, 2023One of the mainstream schemes for 2D human pose estimation (HPE) is learning keypoints heatmaps by a neural network. Existing methods typically improve the quality of heatmaps by customized architectures, such as high-resolution representation and vision Transformers. In this paper, we propose \textbf{DiffusionPose}, a new scheme that formulates 2D HPE as a keypoints heatmaps generation problem from noised heatmaps. During training, the keypoints are diffused to random distribution by adding noises and the diffusion model learns to recover ground-truth heatmaps from noised heatmaps with respect to conditions constructed by image feature. During inference, the diffusion model generates heatmaps from initialized heatmaps in a progressive denoising way. Moreover, we further explore improving the performance of DiffusionPose with conditions from human structural information. Extensive experiments show the prowess of our DiffusionPose, with improvements of 1.6, 1.2, and 1.2 mAP on widely-used COCO, CrowdPose, and AI Challenge datasets, respectively.
Dynamic Graph Reasoning for Multi-person 3D Pose Estimation
Aug 06, 2022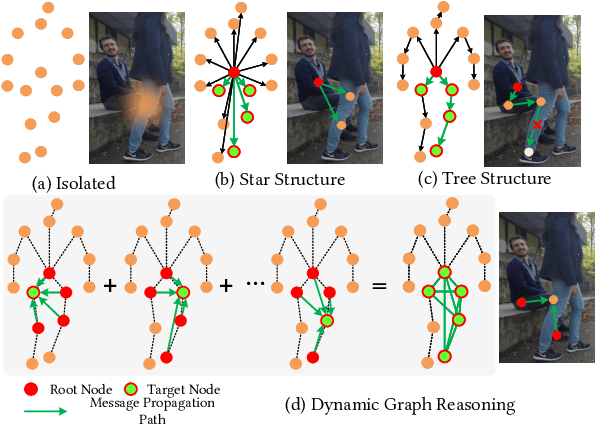


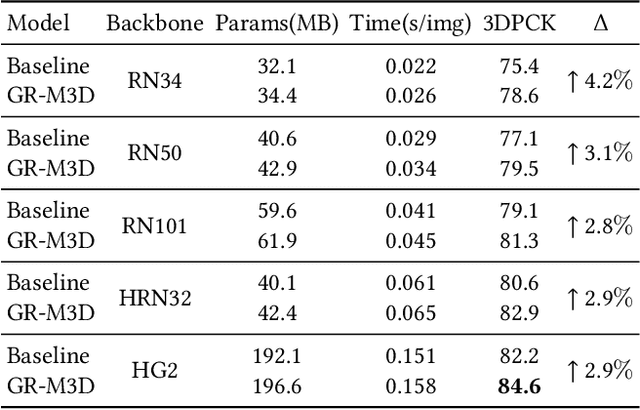
Multi-person 3D pose estimation is a challenging task because of occlusion and depth ambiguity, especially in the cases of crowd scenes. To solve these problems, most existing methods explore modeling body context cues by enhancing feature representation with graph neural networks or adding structural constraints. However, these methods are not robust for their single-root formulation that decoding 3D poses from a root node with a pre-defined graph. In this paper, we propose GR-M3D, which models the \textbf{M}ulti-person \textbf{3D} pose estimation with dynamic \textbf{G}raph \textbf{R}easoning. The decoding graph in GR-M3D is predicted instead of pre-defined. In particular, It firstly generates several data maps and enhances them with a scale and depth aware refinement module (SDAR). Then multiple root keypoints and dense decoding paths for each person are estimated from these data maps. Based on them, dynamic decoding graphs are built by assigning path weights to the decoding paths, while the path weights are inferred from those enhanced data maps. And this process is named dynamic graph reasoning (DGR). Finally, the 3D poses are decoded according to dynamic decoding graphs for each detected person. GR-M3D can adjust the structure of the decoding graph implicitly by adopting soft path weights according to input data, which makes the decoding graphs be adaptive to different input persons to the best extent and more capable of handling occlusion and depth ambiguity than previous methods. We empirically show that the proposed bottom-up approach even outperforms top-down methods and achieves state-of-the-art results on three 3D pose datasets.
IVT: An End-to-End Instance-guided Video Transformer for 3D Pose Estimation
Aug 06, 2022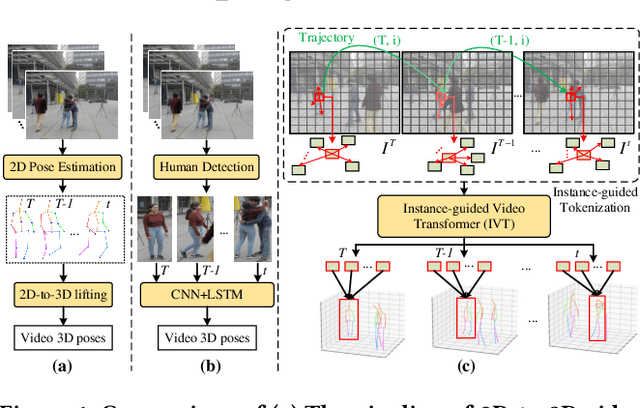
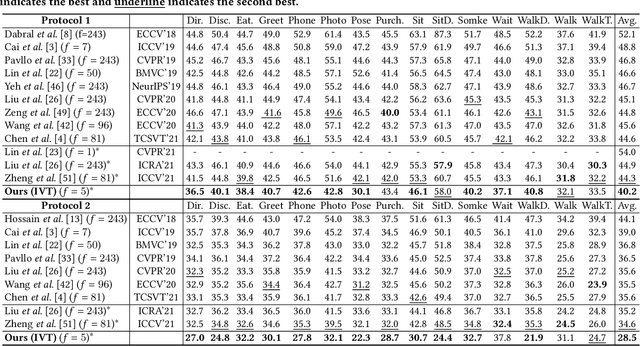
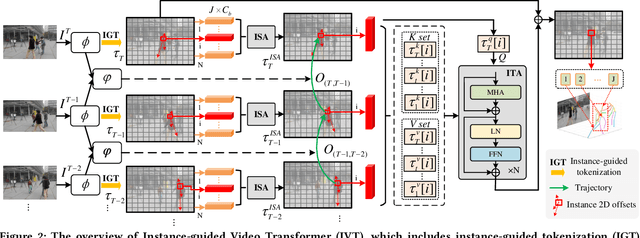
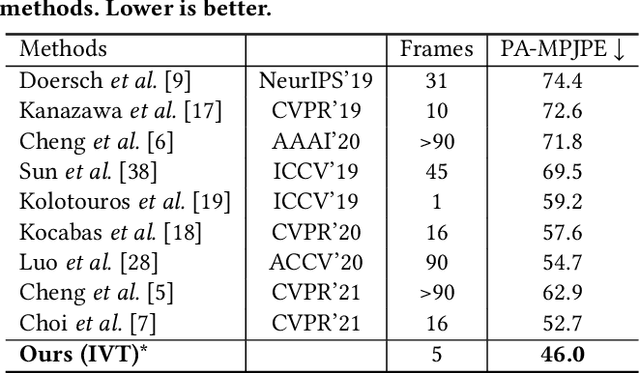
Video 3D human pose estimation aims to localize the 3D coordinates of human joints from videos. Recent transformer-based approaches focus on capturing the spatiotemporal information from sequential 2D poses, which cannot model the contextual depth feature effectively since the visual depth features are lost in the step of 2D pose estimation. In this paper, we simplify the paradigm into an end-to-end framework, Instance-guided Video Transformer (IVT), which enables learning spatiotemporal contextual depth information from visual features effectively and predicts 3D poses directly from video frames. In particular, we firstly formulate video frames as a series of instance-guided tokens and each token is in charge of predicting the 3D pose of a human instance. These tokens contain body structure information since they are extracted by the guidance of joint offsets from the human center to the corresponding body joints. Then, these tokens are sent into IVT for learning spatiotemporal contextual depth. In addition, we propose a cross-scale instance-guided attention mechanism to handle the variational scales among multiple persons. Finally, the 3D poses of each person are decoded from instance-guided tokens by coordinate regression. Experiments on three widely-used 3D pose estimation benchmarks show that the proposed IVT achieves state-of-the-art performances.