 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Gigapixels: Bridging Local Inductive Bias and Long-Range Dependencies with Pixel-Mamba
Dec 21, 2024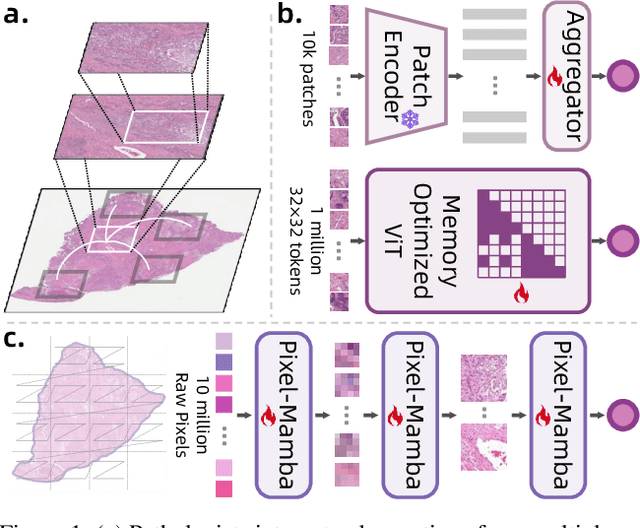
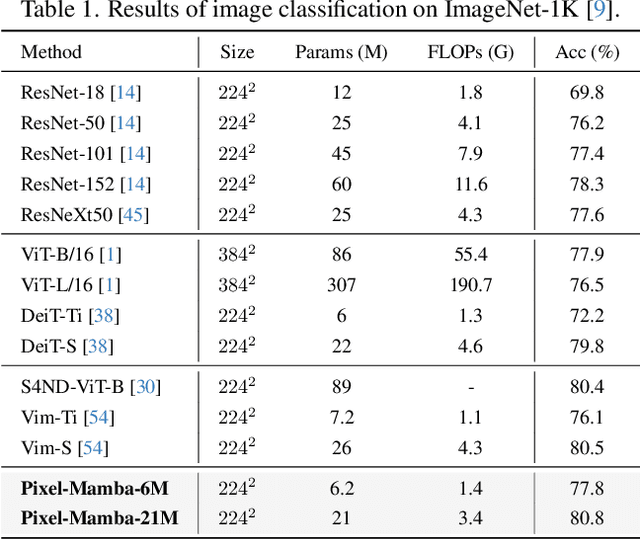
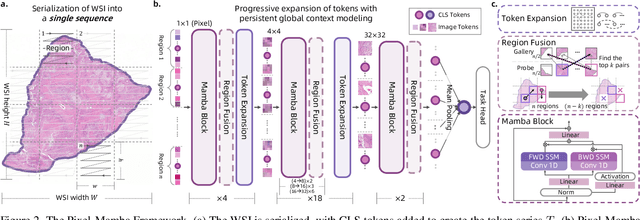
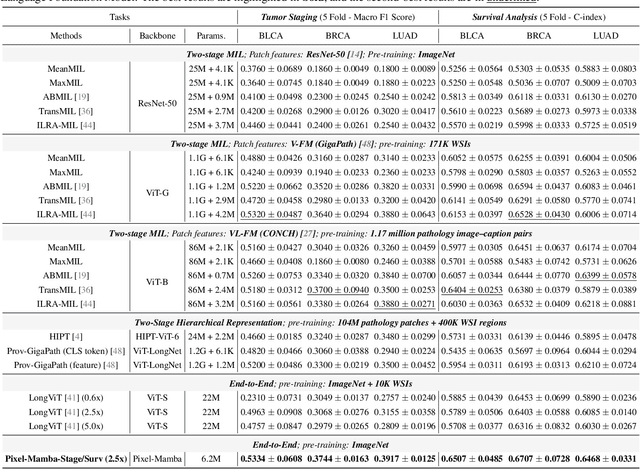
Histopathology plays a critical role in medical diagnostics, with whole slide images (WSIs) offering valuable insights that directly influence clinical decision-making. However, the large size and complexity of WSIs may pose significant challenges for deep learning models, in both computational efficiency and effective representation learning. In this work, we introduce Pixel-Mamba, a novel deep learning architecture designed to efficiently handle gigapixel WSIs. Pixel-Mamba leverages the Mamba module, a state-space model (SSM) with linear memory complexity, and incorporates local inductive biases through progressively expanding tokens, akin to convolutional neural networks. This enables Pixel-Mamba to hierarchically combine both local and global information while efficiently addressing computational challenges. Remarkably, Pixel-Mamba achieves or even surpasses the quantitative performance of state-of-the-art (SOTA) foundation models that were pretrained on millions of WSIs or WSI-text pairs, in a range of tumor staging and survival analysis tasks, {\bf even without requiring any pathology-specific pretraining}. Extensive experiments demonstrate the efficacy of Pixel-Mamba as a powerful and efficient framework for end-to-end WSI analysis.
From Histopathology Images to Cell Clouds: Learning Slide Representations with Hierarchical Cell Transformer
Dec 21, 2024It is clinically crucial and potentially very beneficial to be able to analyze and model directly the spatial distributions of cells in histopathology whole slide images (WSI). However, most existing WSI datasets lack cell-level annotations, owing to the extremely high cost over giga-pixel images. Thus, it remains an open question whether deep learning models can directly and effectively analyze WSIs from the semantic aspect of cell distributions. In this work, we construct a large-scale WSI dataset with more than 5 billion cell-level annotations, termed WSI-Cell5B, and a novel hierarchical Cell Cloud Transformer (CCFormer) to tackle these challenges. WSI-Cell5B is based on 6,998 WSIs of 11 cancers from The Cancer Genome Atlas Program, and all WSIs are annotated per cell by coordinates and types. To the best of our knowledge, WSI-Cell5B is the first WSI-level large-scale dataset integrating cell-level annotations. On the other hand, CCFormer formulates the collection of cells in each WSI as a cell cloud and models cell spatial distribution. Specifically, Neighboring Information Embedding (NIE) is proposed to characterize the distribution of cells within the neighborhood of each cell, and a novel Hierarchical Spatial Perception (HSP) module is proposed to learn the spatial relationship among cells in a bottom-up manner. The clinical analysis indicates that WSI-Cell5B can be used to design clinical evaluation metrics based on counting cells that effectively assess the survival risk of patients. Extensive experiments on survival prediction and cancer staging show that learning from cell spatial distribution alone can already achieve state-of-the-art (SOTA) performance, i.e., CCFormer strongly outperforms other competing methods.
Taylor-Sensus Network: Embracing Noise to Enlighten Uncertainty for Scientific Data
Sep 12, 2024



Uncertainty estimation is crucial in scientific data for machine learning. Current uncertainty estimation methods mainly focus on the model's inherent uncertainty, while neglecting the explicit modeling of noise in the data. Furthermore, noise estimation methods typically rely on temporal or spatial dependencies, which can pose a significant challenge in structured scientific data where such dependencies among samples are often absent. To address these challenges in scientific research, we propose the Taylor-Sensus Network (TSNet). TSNet innovatively uses a Taylor series expansion to model complex, heteroscedastic noise and proposes a deep Taylor block for aware noise distribution. TSNet includes a noise-aware contrastive learning module and a data density perception module for aleatoric and epistemic uncertainty. Additionally, an uncertainty combination operator is used to integrate these uncertainties, and the network is trained using a novel heteroscedastic mean square error loss. TSNet demonstrates superior performance over mainstream and state-of-the-art methods in experiments, highlighting its potential in scientific research and noise resistance. It will be open-source to facilitate the community of "AI for Science".
End-to-end Multi-source Visual Prompt Tuning for Survival Analysis in Whole Slide Images
Sep 05, 2024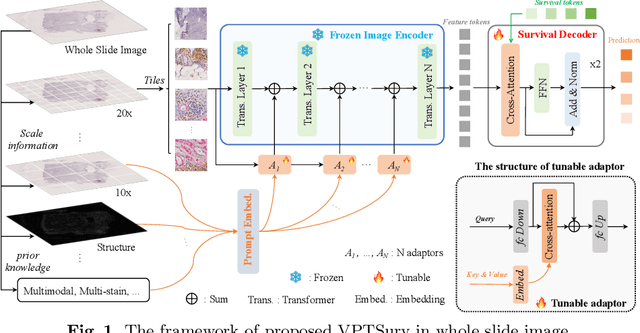
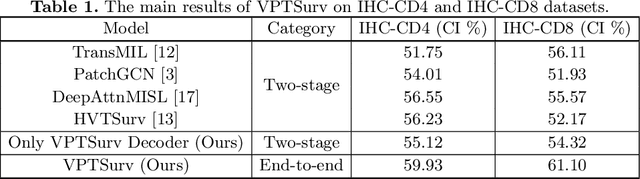
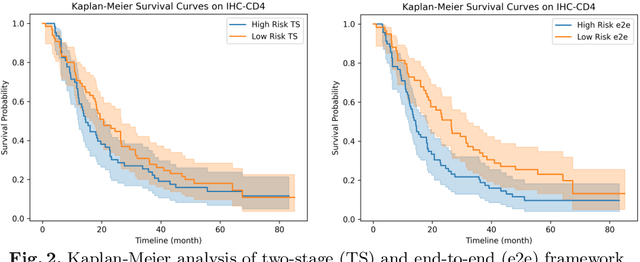

Survival analysis using pathology images poses a considerable challenge, as it requires the localization of relevant information from the multitude of tiles within whole slide images (WSIs). Current methods typically resort to a two-stage approach, where a pre-trained network extracts features from tiles, which are then used by survival models. This process, however, does not optimize the survival models in an end-to-end manner, and the pre-extracted features may not be ideally suited for survival prediction. To address this limitation, we present a novel end-to-end Visual Prompt Tuning framework for survival analysis, named VPTSurv. VPTSurv refines feature embeddings through an efficient encoder-decoder framework. The encoder remains fixed while the framework introduces tunable visual prompts and adaptors, thus permitting end-to-end training specifically for survival prediction by optimizing only the lightweight adaptors and the decoder. Moreover, the versatile VPTSurv framework accommodates multi-source information as prompts, thereby enriching the survival model. VPTSurv achieves substantial increases of 8.7% and 12.5% in the C-index on two immunohistochemical pathology image datasets. These significant improvements highlight the transformative potential of the end-to-end VPT framework over traditional two-stage methods.
Multi-scale Contrastive Adaptor Learning for Segmenting Anything in Underperformed Scenes
Aug 12, 2024



Foundational vision models, such as the Segment Anything Model (SAM), have achieved significant breakthroughs through extensive pre-training on large-scale visual datasets. Despite their general success, these models may fall short in specialized tasks with limited data, and fine-tuning such large-scale models is often not feasible. Current strategies involve incorporating adaptors into the pre-trained SAM to facilitate downstream task performance with minimal model adjustment. However, these strategies can be hampered by suboptimal learning approaches for the adaptors. In this paper, we introduce a novel Multi-scale Contrastive Adaptor learning method named MCA-SAM, which enhances adaptor performance through a meticulously designed contrastive learning framework at both token and sample levels. Our Token-level Contrastive adaptor (TC-adaptor) focuses on refining local representations by improving the discriminability of patch tokens, while the Sample-level Contrastive adaptor (SC-adaptor) amplifies global understanding across different samples. Together, these adaptors synergistically enhance feature comparison within and across samples, bolstering the model's representational strength and its ability to adapt to new tasks. Empirical results demonstrate that MCA-SAM sets new benchmarks, outperforming existing methods in three challenging domains: camouflage object detection, shadow segmentation, and polyp segmentation. Specifically, MCA-SAM exhibits substantial relative performance enhancements, achieving a 20.0% improvement in MAE on the COD10K dataset, a 6.0% improvement in MAE on the CAMO dataset, a 15.4% improvement in BER on the ISTD dataset, and a 7.9% improvement in mDice on the Kvasir-SEG dataset.
Bridging the Semantic-Numerical Gap: A Numerical Reasoning Method of Cross-modal Knowledge Graph for Material Property Prediction
Dec 15, 2023



Using machine learning (ML) techniques to predict material properties is a crucial research topic. These properties depend on numerical data and semantic factors. Due to the limitations of small-sample datasets, existing methods typically adopt ML algorithms to regress numerical properties or transfer other pre-trained knowledge graphs (KGs) to the material. However, these methods cannot simultaneously handle semantic and numerical information. In this paper, we propose a numerical reasoning method for material KGs (NR-KG), which constructs a cross-modal KG using semantic nodes and numerical proxy nodes. It captures both types of information by projecting KG into a canonical KG and utilizes a graph neural network to predict material properties. In this process, a novel projection prediction loss is proposed to extract semantic features from numerical information. NR-KG facilitates end-to-end processing of cross-modal data, mining relationships and cross-modal information in small-sample datasets, and fully utilizes valuable experimental data to enhance material prediction. We further propose two new High-Entropy Alloys (HEA) property datasets with semantic descriptions. NR-KG outperforms state-of-the-art (SOTA) methods, achieving relative improvements of 25.9% and 16.1% on two material datasets. Besides, NR-KG surpasses SOTA methods on two public physical chemistry molecular datasets, showing improvements of 22.2% and 54.3%, highlighting its potential application and generalizability. We hope the proposed datasets, algorithms, and pre-trained models can facilitate the communities of KG and AI for materials.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
MM-NeRF: Multimodal-Guided 3D Multi-Style Transfer of Neural Radiance Field
Sep 24, 20233D style transfer aims to render stylized novel views of 3D scenes with the specified style, which requires high-quality rendering and keeping multi-view consistency. Benefiting from the ability of 3D representation from Neural Radiance Field (NeRF), existing methods learn the stylized NeRF by giving a reference style from an image. However, they suffer the challenges of high-quality stylization with texture details for multi-style transfer and stylization with multimodal guidance. In this paper, we reveal that the same objects in 3D scenes show various states (color tone, details, etc.) from different views after stylization since previous methods optimized by single-view image-based style loss functions, leading NeRF to tend to smooth texture details, further resulting in low-quality rendering. To tackle these problems, we propose a novel Multimodal-guided 3D Multi-style transfer of NeRF, termed MM-NeRF, which achieves high-quality 3D multi-style rendering with texture details and can be driven by multimodal-style guidance. First, MM-NeRF adopts a unified framework to project multimodal guidance into CLIP space and extracts multimodal style features to guide the multi-style stylization. To relieve the problem of lacking details, we propose a novel Multi-Head Learning Scheme (MLS), in which each style head predicts the parameters of the color head of NeRF. MLS decomposes the learning difficulty caused by the inconsistency of multi-style transfer and improves the quality of stylization. In addition, the MLS can generalize pre-trained MM-NeRF to any new styles by adding heads with small training costs (a few minutes). Extensive experiments on three real-world 3D scene datasets show that MM-NeRF achieves high-quality 3D multi-style stylization with multimodal guidance, keeps multi-view consistency, and keeps semantic consistency of multimodal style guidance. Codes will be released later.
Learning Structure-Guided Diffusion Model for 2D Human Pose Estimation
Jun 29, 2023One of the mainstream schemes for 2D human pose estimation (HPE) is learning keypoints heatmaps by a neural network. Existing methods typically improve the quality of heatmaps by customized architectures, such as high-resolution representation and vision Transformers. In this paper, we propose \textbf{DiffusionPose}, a new scheme that formulates 2D HPE as a keypoints heatmaps generation problem from noised heatmaps. During training, the keypoints are diffused to random distribution by adding noises and the diffusion model learns to recover ground-truth heatmaps from noised heatmaps with respect to conditions constructed by image feature. During inference, the diffusion model generates heatmaps from initialized heatmaps in a progressive denoising way. Moreover, we further explore improving the performance of DiffusionPose with conditions from human structural information. Extensive experiments show the prowess of our DiffusionPose, with improvements of 1.6, 1.2, and 1.2 mAP on widely-used COCO, CrowdPose, and AI Challenge datasets, respectively.
Stable Diffusion is Unstable
Jun 06, 2023Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.