 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Robustness of Visual State Space Models for Image Classification
Mar 16, 2024Visual State Space Model (VMamba) has recently emerged as a promising architecture, exhibiting remarkable performance in various computer vision tasks. However, its robustness has not yet been thoroughly studied. In this paper, we delve into the robustness of this architecture through comprehensive investigations from multiple perspectives. Firstly, we investigate its robustness to adversarial attacks, employing both whole-image and patch-specific adversarial attacks. Results demonstrate superior adversarial robustness compared to Transformer architectures while revealing scalability weaknesses. Secondly, the general robustness of VMamba is assessed against diverse scenarios, including natural adversarial examples, out-of-distribution data, and common corruptions. VMamba exhibits exceptional generalizability with out-of-distribution data but shows scalability weaknesses against natural adversarial examples and common corruptions. Additionally, we explore VMamba's gradients and back-propagation during white-box attacks, uncovering unique vulnerabilities and defensive capabilities of its novel components. Lastly, the sensitivity of VMamba to image structure variations is examined, highlighting vulnerabilities associated with the distribution of disturbance areas and spatial information, with increased susceptibility closer to the image center. Through these comprehensive studies, we contribute to a deeper understanding of VMamba's robustness, providing valuable insights for refining and advancing the capabilities of deep neural networks in computer vision applications.
Neural Architecture Retrieval
Jul 16, 2023



With the increasing number of new neural architecture designs and substantial existing neural architectures, it becomes difficult for the researchers to situate their contributions compared with existing neural architectures or establish the connections between their designs and other relevant ones. To discover similar neural architectures in an efficient and automatic manner, we define a new problem Neural Architecture Retrieval which retrieves a set of existing neural architectures which have similar designs to the query neural architecture. Existing graph pre-training strategies cannot address the computational graph in neural architectures due to the graph size and motifs. To fulfill this potential, we propose to divide the graph into motifs which are used to rebuild the macro graph to tackle these issues, and introduce multi-level contrastive learning to achieve accurate graph representation learning. Extensive evaluations on both human-designed and synthesized neural architectures demonstrate the superiority of our algorithm. Such a dataset which contains 12k real-world network architectures, as well as their embedding, is built for neural architecture retrieval.
GPT Self-Supervision for a Better Data Annotator
Jun 08, 2023



The task of annotating data into concise summaries poses a significant challenge across various domains, frequently requiring the allocation of significant time and specialized knowledge by human experts. Despite existing efforts to use large language models for annotation tasks, significant problems such as limited applicability to unlabeled data, the absence of self-supervised methods, and the lack of focus on complex structured data still persist. In this work, we propose a GPT self-supervision annotation method, which embodies a generating-recovering paradigm that leverages the one-shot learning capabilities of the Generative Pretrained Transformer (GPT). The proposed approach comprises a one-shot tuning phase followed by a generation phase. In the one-shot tuning phase, we sample a data from the support set as part of the prompt for GPT to generate a textual summary, which is then used to recover the original data. The alignment score between the recovered and original data serves as a self-supervision navigator to refine the process. In the generation stage, the optimally selected one-shot sample serves as a template in the prompt and is applied to generating summaries from challenging datasets. The annotation performance is evaluated by tuning several human feedback reward networks and by calculating alignment scores between original and recovered data at both sentence and structure levels. Our self-supervised annotation method consistently achieves competitive scores, convincingly demonstrating its robust strength in various data-to-summary annotation tasks.
Stable Diffusion is Unstable
Jun 06, 2023Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 25, 2021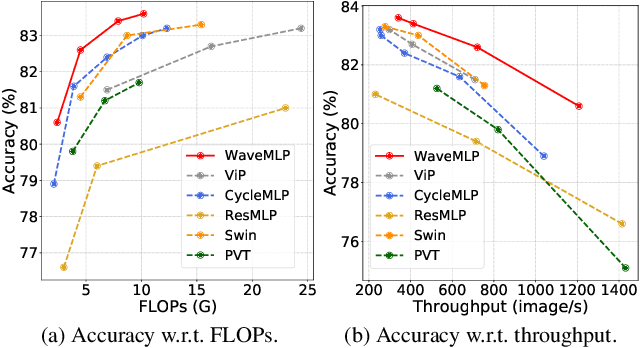
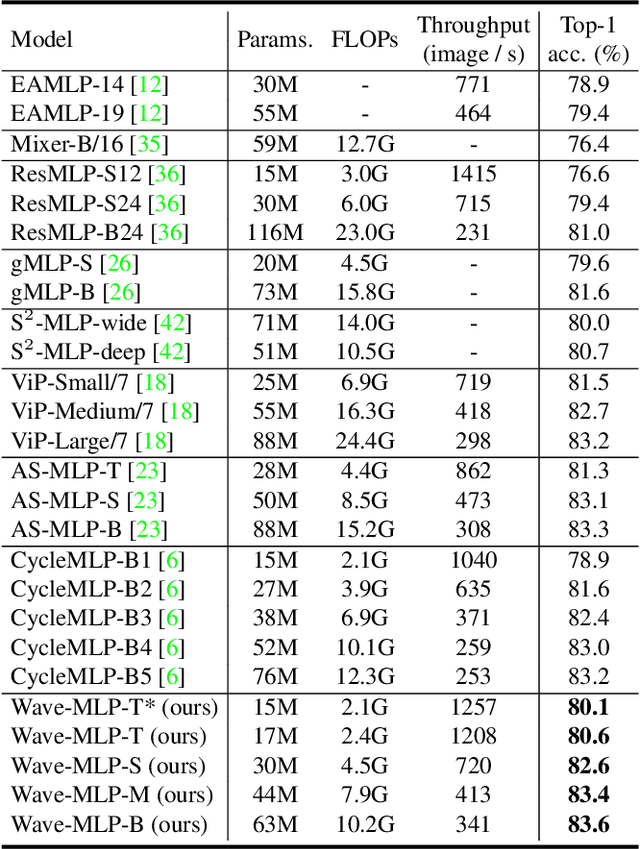
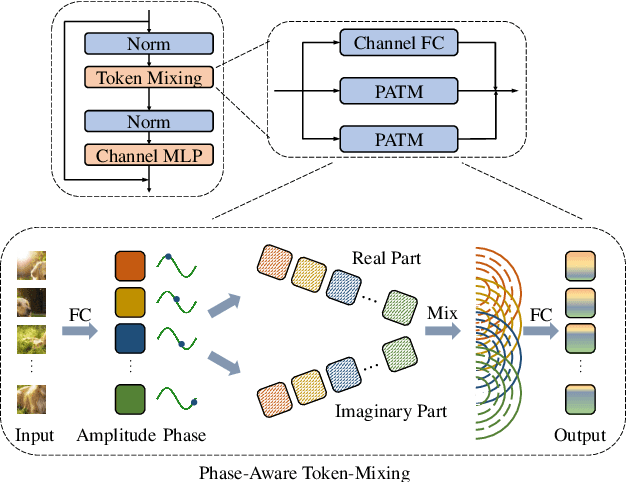
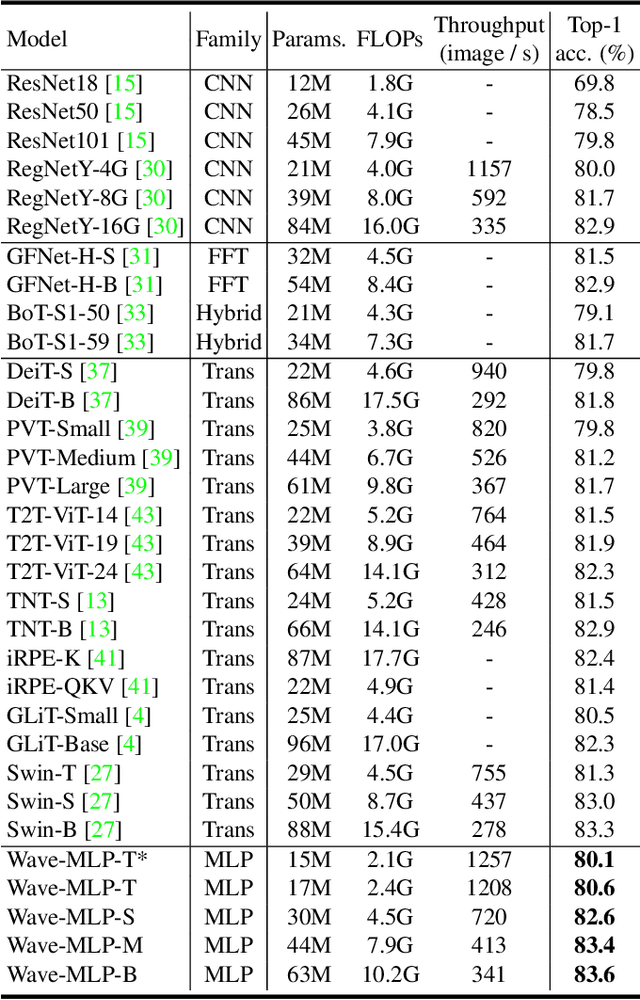
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
Neural Architecture Dilation for Adversarial Robustness
Aug 16, 2021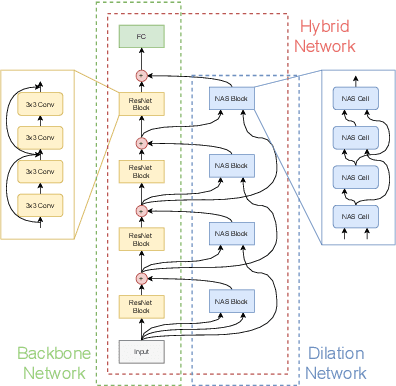



With the tremendous advances in the architecture and scale of convolutional neural networks (CNNs) over the past few decades, they can easily reach or even exceed the performance of humans in certain tasks. However, a recently discovered shortcoming of CNNs is that they are vulnerable to adversarial attacks. Although the adversarial robustness of CNNs can be improved by adversarial training, there is a trade-off between standard accuracy and adversarial robustness. From the neural architecture perspective, this paper aims to improve the adversarial robustness of the backbone CNNs that have a satisfactory accuracy. Under a minimal computational overhead, the introduction of a dilation architecture is expected to be friendly with the standard performance of the backbone CNN while pursuing adversarial robustness. Theoretical analyses on the standard and adversarial error bounds naturally motivate the proposed neural architecture dilation algorithm. Experimental results on real-world datasets and benchmark neural networks demonstrate the effectiveness of the proposed algorithm to balance the accuracy and adversarial robustness.
Prioritized Architecture Sampling with Monto-Carlo Tree Search
Mar 22, 2021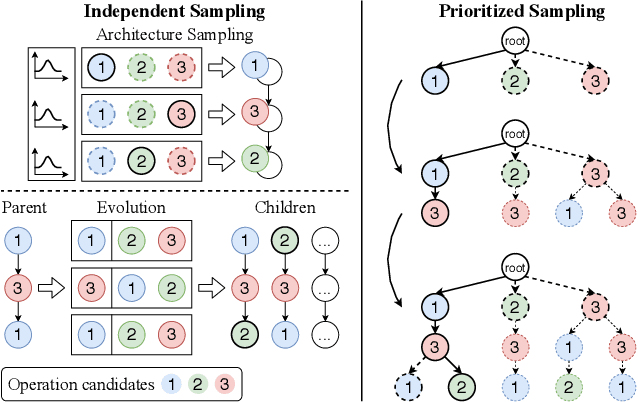
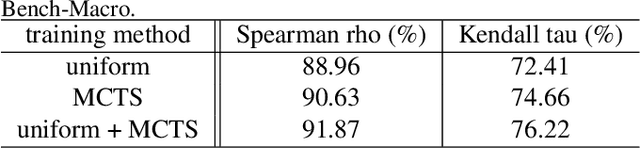
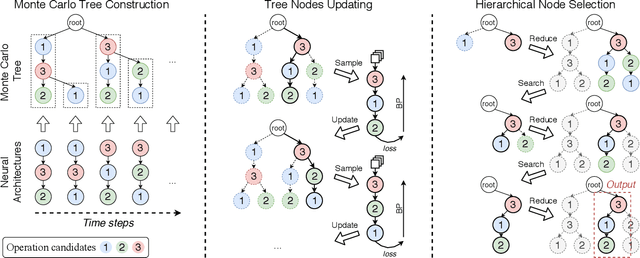
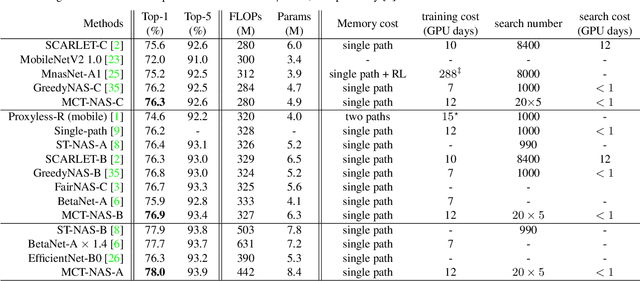
One-shot neural architecture search (NAS) methods significantly reduce the search cost by considering the whole search space as one network, which only needs to be trained once. However, current methods select each operation independently without considering previous layers. Besides, the historical information obtained with huge computation cost is usually used only once and then discarded. In this paper, we introduce a sampling strategy based on Monte Carlo tree search (MCTS) with the search space modeled as a Monte Carlo tree (MCT), which captures the dependency among layers. Furthermore, intermediate results are stored in the MCT for the future decision and a better exploration-exploitation balance. Concretely, MCT is updated using the training loss as a reward to the architecture performance; for accurately evaluating the numerous nodes, we propose node communication and hierarchical node selection methods in the training and search stages, respectively, which make better uses of the operation rewards and hierarchical information. Moreover, for a fair comparison of different NAS methods, we construct an open-source NAS benchmark of a macro search space evaluated on CIFAR-10, namely NAS-Bench-Macro. Extensive experiments on NAS-Bench-Macro and ImageNet demonstrate that our method significantly improves search efficiency and performance. For example, by only searching $20$ architectures, our obtained architecture achieves $78.0\%$ top-1 accuracy with 442M FLOPs on ImageNet. Code (Benchmark) is available at: \url{https://github.com/xiusu/NAS-Bench-Macro}.
Adversarially Robust Neural Architectures
Sep 02, 2020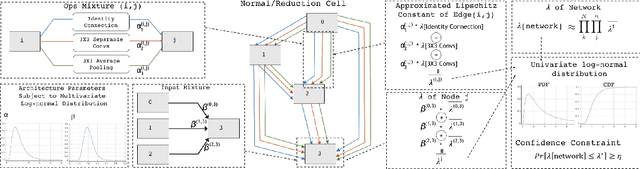
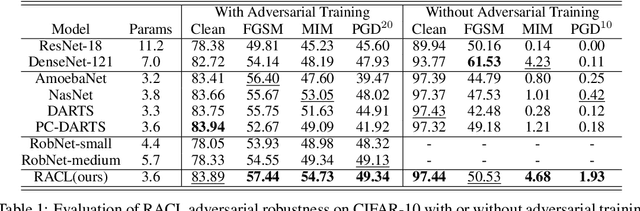
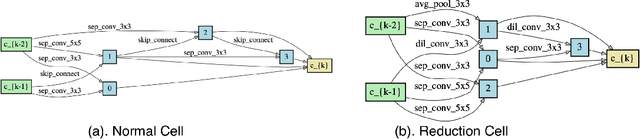
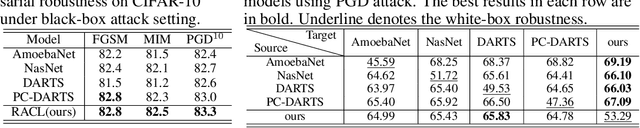
Deep Neural Network (DNN) are vulnerable to adversarial attack. Existing methods are devoted to developing various robust training strategies or regularizations to update the weights of the neural network. But beyond the weights, the overall structure and information flow in the network are explicitly determined by the neural architecture, which remains unexplored. This paper thus aims to improve the adversarial robustness of the network from the architecture perspective with NAS framework. We explore the relationship among adversarial robustness, Lipschitz constant, and architecture parameters and show that an appropriate constraint on architecture parameters could reduce the Lipschitz constant to further improve the robustness. For NAS framework, all the architecture parameters are equally treated when the discrete architecture is sampled from supernet. However, the importance of architecture parameters could vary from operation to operation or connection to connection, which is not explored and might reduce the confidence of robust architecture sampling. Thus, we propose to sample architecture parameters from trainable multivariate log-normal distributions, with which the Lipschitz constant of entire network can be approximated using a univariate log-normal distribution with mean and variance related to architecture parameters. Compared with adversarially trained neural architectures searched by various NAS algorithms as well as efficient human-designed models, our algorithm empirically achieves the best performance among all the models under various attacks on different datasets.