 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-aware Dynamic Pruning for Efficient Vision-Language-Action Manipulation
Sep 26, 2025Robotic manipulation with Vision-Language-Action models requires efficient inference over long-horizon multi-modal context, where attention to dense visual tokens dominates computational cost. Existing methods optimize inference speed by reducing visual redundancy within VLA models, but they overlook the varying redundancy across robotic manipulation stages. We observe that the visual token redundancy is higher in coarse manipulation phase than in fine-grained operations, and is strongly correlated with the action dynamic. Motivated by this observation, we propose \textbf{A}ction-aware \textbf{D}ynamic \textbf{P}runing (\textbf{ADP}), a multi-modal pruning framework that integrates text-driven token selection with action-aware trajectory gating. Our method introduces a gating mechanism that conditions the pruning signal on recent action trajectories, using past motion windows to adaptively adjust token retention ratios in accordance with dynamics, thereby balancing computational efficiency and perceptual precision across different manipulation stages. Extensive experiments on the LIBERO suites and diverse real-world scenarios demonstrate that our method significantly reduces FLOPs and action inference latency (\textit{e.g.} $1.35 \times$ speed up on OpenVLA-OFT) while maintaining competitive success rates (\textit{e.g.} 25.8\% improvements with OpenVLA) compared to baselines, thereby providing a simple plug-in path to efficient robot policies that advances the efficiency and performance frontier of robotic manipulation. Our project website is: \href{https://vla-adp.github.io/}{ADP.com}.
Rethinking Causal Mask Attention for Vision-Language Inference
May 24, 2025Causal attention has become a foundational mechanism in autoregressive vision-language models (VLMs), unifying textual and visual inputs under a single generative framework. However, existing causal mask-based strategies are inherited from large language models (LLMs) where they are tailored for text-only decoding, and their adaptation to vision tokens is insufficiently addressed in the prefill stage. Strictly masking future positions for vision queries introduces overly rigid constraints, which hinder the model's ability to leverage future context that often contains essential semantic cues for accurate inference. In this work, we empirically investigate how different causal masking strategies affect vision-language inference and then propose a family of future-aware attentions tailored for this setting. We first empirically analyze the effect of previewing future tokens for vision queries and demonstrate that rigid masking undermines the model's capacity to capture useful contextual semantic representations. Based on these findings, we propose a lightweight attention family that aggregates future visual context into past representations via pooling, effectively preserving the autoregressive structure while enhancing cross-token dependencies. We evaluate a range of causal masks across diverse vision-language inference settings and show that selectively compressing future semantic context into past representations benefits the inference.
Cross-Self KV Cache Pruning for Efficient Vision-Language Inference
Dec 05, 2024



KV cache pruning has emerged as a promising technique for reducing memory and computation costs in long-context auto-regressive generation. Existing methods for vision-language models (VLMs) typically rely on self-attention scores from large language models (LLMs) to identify and prune irrelevant tokens. However, these approaches overlook the inherent distributional discrepancies between modalities, often leading to inaccurate token importance estimation and the over-pruning of critical visual tokens. To address this, we propose decomposing attention scores into intra-modality attention (within the same modality) and inter-modality attention (across modalities), enabling more precise KV cache pruning by independently managing these distinct attention types. Additionally, we introduce an n-softmax function to counteract distribution shifts caused by pruning, preserving the original smoothness of attention scores and ensuring stable performance. Our final training-free method, \textbf{C}ross-\textbf{S}elf \textbf{P}runing (CSP), achieves competitive performance compared to models with full KV caches while significantly outperforming previous pruning methods. Extensive evaluations on MileBench, a benchmark encompassing 29 multimodal datasets, demonstrate CSP's effectiveness, achieving up to a 41\% performance improvement on challenging tasks like conversational embodied dialogue while reducing the KV cache budget by 13.6\%. The code is available at https://github.com/TerryPei/CSP
EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
Mar 15, 2024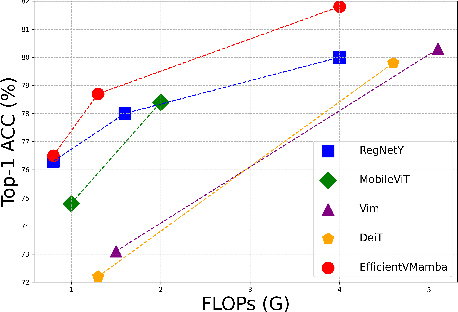



Prior efforts in light-weight model development mainly centered on CNN and Transformer-based designs yet faced persistent challenges. CNNs adept at local feature extraction compromise resolution while Transformers offer global reach but escalate computational demands $\mathcal{O}(N^2)$. This ongoing trade-off between accuracy and efficiency remains a significant hurdle. Recently, state space models (SSMs), such as Mamba, have shown outstanding performance and competitiveness in various tasks such as language modeling and computer vision, while reducing the time complexity of global information extraction to $\mathcal{O}(N)$. Inspired by this, this work proposes to explore the potential of visual state space models in light-weight model design and introduce a novel efficient model variant dubbed EfficientVMamba. Concretely, our EfficientVMamba integrates a atrous-based selective scan approach by efficient skip sampling, constituting building blocks designed to harness both global and local representational features. Additionally, we investigate the integration between SSM blocks and convolutions, and introduce an efficient visual state space block combined with an additional convolution branch, which further elevate the model performance. Experimental results show that, EfficientVMamba scales down the computational complexity while yields competitive results across a variety of vision tasks. For example, our EfficientVMamba-S with $1.3$G FLOPs improves Vim-Ti with $1.5$G FLOPs by a large margin of $5.6\%$ accuracy on ImageNet. Code is available at: \url{https://github.com/TerryPei/EfficientVMamba}.
LocalMamba: Visual State Space Model with Windowed Selective Scan
Mar 14, 2024



Recent advancements in state space models, notably Mamba, have demonstrated significant progress in modeling long sequences for tasks like language understanding. Yet, their application in vision tasks has not markedly surpassed the performance of traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This paper posits that the key to enhancing Vision Mamba (ViM) lies in optimizing scan directions for sequence modeling. Traditional ViM approaches, which flatten spatial tokens, overlook the preservation of local 2D dependencies, thereby elongating the distance between adjacent tokens. We introduce a novel local scanning strategy that divides images into distinct windows, effectively capturing local dependencies while maintaining a global perspective. Additionally, acknowledging the varying preferences for scan patterns across different network layers, we propose a dynamic method to independently search for the optimal scan choices for each layer, substantially improving performance. Extensive experiments across both plain and hierarchical models underscore our approach's superiority in effectively capturing image representations. For example, our model significantly outperforms Vim-Ti by 3.1% on ImageNet with the same 1.5G FLOPs. Code is available at: https://github.com/hunto/LocalMamba.
Neural Architecture Retrieval
Jul 16, 2023



With the increasing number of new neural architecture designs and substantial existing neural architectures, it becomes difficult for the researchers to situate their contributions compared with existing neural architectures or establish the connections between their designs and other relevant ones. To discover similar neural architectures in an efficient and automatic manner, we define a new problem Neural Architecture Retrieval which retrieves a set of existing neural architectures which have similar designs to the query neural architecture. Existing graph pre-training strategies cannot address the computational graph in neural architectures due to the graph size and motifs. To fulfill this potential, we propose to divide the graph into motifs which are used to rebuild the macro graph to tackle these issues, and introduce multi-level contrastive learning to achieve accurate graph representation learning. Extensive evaluations on both human-designed and synthesized neural architectures demonstrate the superiority of our algorithm. Such a dataset which contains 12k real-world network architectures, as well as their embedding, is built for neural architecture retrieval.
GPT Self-Supervision for a Better Data Annotator
Jun 08, 2023



The task of annotating data into concise summaries poses a significant challenge across various domains, frequently requiring the allocation of significant time and specialized knowledge by human experts. Despite existing efforts to use large language models for annotation tasks, significant problems such as limited applicability to unlabeled data, the absence of self-supervised methods, and the lack of focus on complex structured data still persist. In this work, we propose a GPT self-supervision annotation method, which embodies a generating-recovering paradigm that leverages the one-shot learning capabilities of the Generative Pretrained Transformer (GPT). The proposed approach comprises a one-shot tuning phase followed by a generation phase. In the one-shot tuning phase, we sample a data from the support set as part of the prompt for GPT to generate a textual summary, which is then used to recover the original data. The alignment score between the recovered and original data serves as a self-supervision navigator to refine the process. In the generation stage, the optimally selected one-shot sample serves as a template in the prompt and is applied to generating summaries from challenging datasets. The annotation performance is evaluated by tuning several human feedback reward networks and by calculating alignment scores between original and recovered data at both sentence and structure levels. Our self-supervised annotation method consistently achieves competitive scores, convincingly demonstrating its robust strength in various data-to-summary annotation tasks.