 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration under Ambiguous Ground Truth
Mar 24, 2026Confidence calibration assumes a unique ground-truth label per input, yet this assumption fails wherever annotators genuinely disagree. Post-hoc calibrators fitted on majority-voted labels, the standard single-label targets used in practice, can appear well-calibrated under conventional evaluation yet remain substantially miscalibrated against the underlying annotator distribution. We show that this failure is structural: under simplifying assumptions, Temperature Scaling is biased toward temperatures that underestimate annotator uncertainty, with true-label miscalibration increasing monotonically with annotation entropy. To address this, we develop a family of ambiguity-aware post-hoc calibrators that optimise proper scoring rules against the full label distribution and require no model retraining. Our methods span progressively weaker annotation requirements: Dirichlet-Soft leverages the full annotator distribution and achieves the best overall calibration quality across settings; Monte Carlo Temperature Scaling with a single annotation per example (MCTS S=1) matches full-distribution calibration across all benchmarks, demonstrating that pre-aggregated label distributions are unnecessary; and Label-Smooth Temperature Scaling (LS-TS) operates with voted labels alone by constructing data-driven pseudo-soft targets from the model's own confidence. Experiments on four benchmarks with real multi-annotator distributions (CIFAR-10H, ChaosNLI) and clinically-informed synthetic annotations (ISIC~2019, DermaMNIST) show that Dirichlet-Soft reduces true-label ECE by 55-87% relative to Temperature Scaling, while LS-TS reduces ECE by 9-77% without any annotator data.
PA-Attack: Guiding Gray-Box Attacks on LVLM Vision Encoders with Prototypes and Attention
Feb 23, 2026Large Vision-Language Models (LVLMs) are foundational to modern multimodal applications, yet their susceptibility to adversarial attacks remains a critical concern. Prior white-box attacks rarely generalize across tasks, and black-box methods depend on expensive transfer, which limits efficiency. The vision encoder, standardized and often shared across LVLMs, provides a stable gray-box pivot with strong cross-model transfer. Building on this premise, we introduce PA-Attack (Prototype-Anchored Attentive Attack). PA-Attack begins with a prototype-anchored guidance that provides a stable attack direction towards a general and dissimilar prototype, tackling the attribute-restricted issue and limited task generalization of vanilla attacks. Building on this, we propose a two-stage attention enhancement mechanism: (i) leverage token-level attention scores to concentrate perturbations on critical visual tokens, and (ii) adaptively recalibrate attention weights to track the evolving attention during the adversarial process. Extensive experiments across diverse downstream tasks and LVLM architectures show that PA-Attack achieves an average 75.1% score reduction rate (SRR), demonstrating strong attack effectiveness, efficiency, and task generalization in LVLMs. Code is available at https://github.com/hefeimei06/PA-Attack.
Diversifying Counterattacks: Orthogonal Exploration for Robust CLIP Inference
Nov 12, 2025Vision-language pre-training models (VLPs) demonstrate strong multimodal understanding and zero-shot generalization, yet remain vulnerable to adversarial examples, raising concerns about their reliability. Recent work, Test-Time Counterattack (TTC), improves robustness by generating perturbations that maximize the embedding deviation of adversarial inputs using PGD, pushing them away from their adversarial representations. However, due to the fundamental difference in optimization objectives between adversarial attacks and counterattacks, generating counterattacks solely based on gradients with respect to the adversarial input confines the search to a narrow space. As a result, the counterattacks could overfit limited adversarial patterns and lack the diversity to fully neutralize a broad range of perturbations. In this work, we argue that enhancing the diversity and coverage of counterattacks is crucial to improving adversarial robustness in test-time defense. Accordingly, we propose Directional Orthogonal Counterattack (DOC), which augments counterattack optimization by incorporating orthogonal gradient directions and momentum-based updates. This design expands the exploration of the counterattack space and increases the diversity of perturbations, which facilitates the discovery of more generalizable counterattacks and ultimately improves the ability to neutralize adversarial perturbations. Meanwhile, we present a directional sensitivity score based on averaged cosine similarity to boost DOC by improving example discrimination and adaptively modulating the counterattack strength. Extensive experiments on 16 datasets demonstrate that DOC improves adversarial robustness under various attacks while maintaining competitive clean accuracy. Code is available at https://github.com/bookman233/DOC.
Revisiting Uncertainty Estimation and Calibration of Large Language Models
May 29, 2025As large language models (LLMs) are increasingly deployed in high-stakes applications, robust uncertainty estimation is essential for ensuring the safe and trustworthy deployment of LLMs. We present the most comprehensive study to date of uncertainty estimation in LLMs, evaluating 80 models spanning open- and closed-source families, dense and Mixture-of-Experts (MoE) architectures, reasoning and non-reasoning modes, quantization variants and parameter scales from 0.6B to 671B. Focusing on three representative black-box single-pass methods, including token probability-based uncertainty (TPU), numerical verbal uncertainty (NVU), and linguistic verbal uncertainty (LVU), we systematically evaluate uncertainty calibration and selective classification using the challenging MMLU-Pro benchmark, which covers both reasoning-intensive and knowledge-based tasks. Our results show that LVU consistently outperforms TPU and NVU, offering stronger calibration and discrimination while being more interpretable. We also find that high accuracy does not imply reliable uncertainty, and that model scale, post-training, reasoning ability and quantization all influence estimation performance. Notably, LLMs exhibit better uncertainty estimates on reasoning tasks than on knowledge-heavy ones, and good calibration does not necessarily translate to effective error ranking. These findings highlight the need for multi-perspective evaluation and position LVU as a practical tool for improving the reliability of LLMs in real-world settings.
VEAttack: Downstream-agnostic Vision Encoder Attack against Large Vision Language Models
May 23, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation, yet their vulnerability to adversarial attacks raises significant robustness concerns. While existing effective attacks always focus on task-specific white-box settings, these approaches are limited in the context of LVLMs, which are designed for diverse downstream tasks and require expensive full-model gradient computations. Motivated by the pivotal role and wide adoption of the vision encoder in LVLMs, we propose a simple yet effective Vision Encoder Attack (VEAttack), which targets the vision encoder of LVLMs only. Specifically, we propose to generate adversarial examples by minimizing the cosine similarity between the clean and perturbed visual features, without accessing the following large language models, task information, and labels. It significantly reduces the computational overhead while eliminating the task and label dependence of traditional white-box attacks in LVLMs. To make this simple attack effective, we propose to perturb images by optimizing image tokens instead of the classification token. We provide both empirical and theoretical evidence that VEAttack can easily generalize to various tasks. VEAttack has achieved a performance degradation of 94.5% on image caption task and 75.7% on visual question answering task. We also reveal some key observations to provide insights into LVLM attack/defense: 1) hidden layer variations of LLM, 2) token attention differential, 3) M\"obius band in transfer attack, 4) low sensitivity to attack steps. The code is available at https://github.com/hfmei/VEAttack-LVLM
A Survey on Small Sample Imbalance Problem: Metrics, Feature Analysis, and Solutions
Apr 21, 2025The small sample imbalance (S&I) problem is a major challenge in machine learning and data analysis. It is characterized by a small number of samples and an imbalanced class distribution, which leads to poor model performance. In addition, indistinct inter-class feature distributions further complicate classification tasks. Existing methods often rely on algorithmic heuristics without sufficiently analyzing the underlying data characteristics. We argue that a detailed analysis from the data perspective is essential before developing an appropriate solution. Therefore, this paper proposes a systematic analytical framework for the S\&I problem. We first summarize imbalance metrics and complexity analysis methods, highlighting the need for interpretable benchmarks to characterize S&I problems. Second, we review recent solutions for conventional, complexity-based, and extreme S&I problems, revealing methodological differences in handling various data distributions. Our summary finds that resampling remains a widely adopted solution. However, we conduct experiments on binary and multiclass datasets, revealing that classifier performance differences significantly exceed the improvements achieved through resampling. Finally, this paper highlights open questions and discusses future trends.
Beyond One-Hot Labels: Semantic Mixing for Model Calibration
Apr 18, 2025
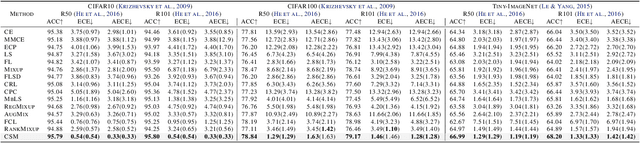
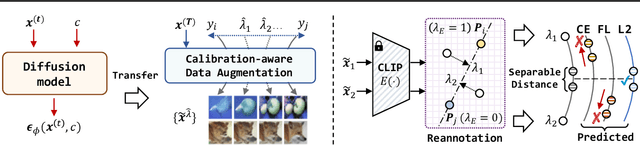

Model calibration seeks to ensure that models produce confidence scores that accurately reflect the true likelihood of their predictions being correct. However, existing calibration approaches are fundamentally tied to datasets of one-hot labels implicitly assuming full certainty in all the annotations. Such datasets are effective for classification but provides insufficient knowledge of uncertainty for model calibration, necessitating the curation of datasets with numerically rich ground-truth confidence values. However, due to the scarcity of uncertain visual examples, such samples are not easily available as real datasets. In this paper, we introduce calibration-aware data augmentation to create synthetic datasets of diverse samples and their ground-truth uncertainty. Specifically, we present Calibration-aware Semantic Mixing (CSM), a novel framework that generates training samples with mixed class characteristics and annotates them with distinct confidence scores via diffusion models. Based on this framework, we propose calibrated reannotation to tackle the misalignment between the annotated confidence score and the mixing ratio during the diffusion reverse process. Besides, we explore the loss functions that better fit the new data representation paradigm. Experimental results demonstrate that CSM achieves superior calibration compared to the state-of-the-art calibration approaches. Code is available at github.com/E-Galois/CSM.
Survey of Adversarial Robustness in Multimodal Large Language Models
Mar 18, 2025


Multimodal Large Language Models (MLLMs) have demonstrated exceptional performance in artificial intelligence by facilitating integrated understanding across diverse modalities, including text, images, video, audio, and speech. However, their deployment in real-world applications raises significant concerns about adversarial vulnerabilities that could compromise their safety and reliability. Unlike unimodal models, MLLMs face unique challenges due to the interdependencies among modalities, making them susceptible to modality-specific threats and cross-modal adversarial manipulations. This paper reviews the adversarial robustness of MLLMs, covering different modalities. We begin with an overview of MLLMs and a taxonomy of adversarial attacks tailored to each modality. Next, we review key datasets and evaluation metrics used to assess the robustness of MLLMs. After that, we provide an in-depth review of attacks targeting MLLMs across different modalities. Our survey also identifies critical challenges and suggests promising future research directions.
Harnessing Vision Foundation Models for High-Performance, Training-Free Open Vocabulary Segmentation
Nov 14, 2024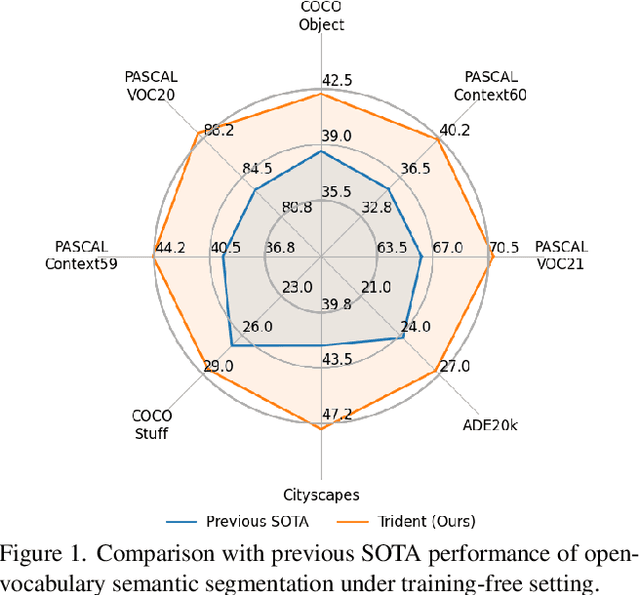


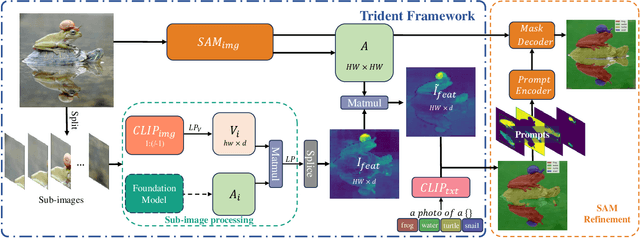
While Contrastive Language-Image Pre-training (CLIP) has advanced open-vocabulary predictions, its performance on semantic segmentation remains suboptimal. This shortfall primarily stems from its spatial-invariant semantic features and constrained resolution. While previous adaptations addressed spatial invariance semantic by modifying the self-attention in CLIP's image encoder, the issue of limited resolution remains unexplored. Different from previous segment-then-splice methods that segment sub-images via a sliding window and splice the results, we introduce a splice-then-segment paradigm that incorporates Segment-Anything Model (SAM) to tackle the resolution issue since SAM excels at extracting fine-grained semantic correlations from high-resolution images. Specifically, we introduce Trident, a training-free framework that first splices features extracted by CLIP and DINO from sub-images, then leverages SAM's encoder to create a correlation matrix for global aggregation, enabling a broadened receptive field for effective segmentation. Besides, we propose a refinement strategy for CLIP's coarse segmentation outputs by transforming them into prompts for SAM, further enhancing the segmentation performance. Trident achieves a significant improvement in the mIoU across eight benchmarks compared with the current SOTA, increasing from 44.4 to 48.6.Code is available at https://github.com/YuHengsss/Trident.
Diffusion Attribution Score: Evaluating Training Data Influence in Diffusion Model
Oct 24, 2024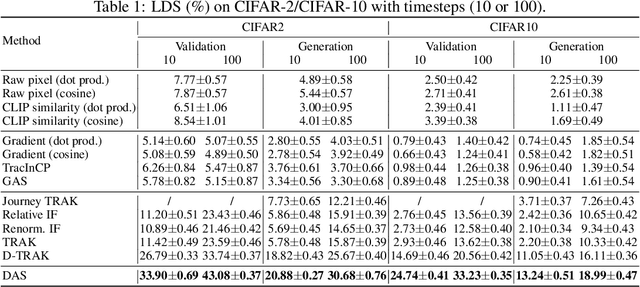


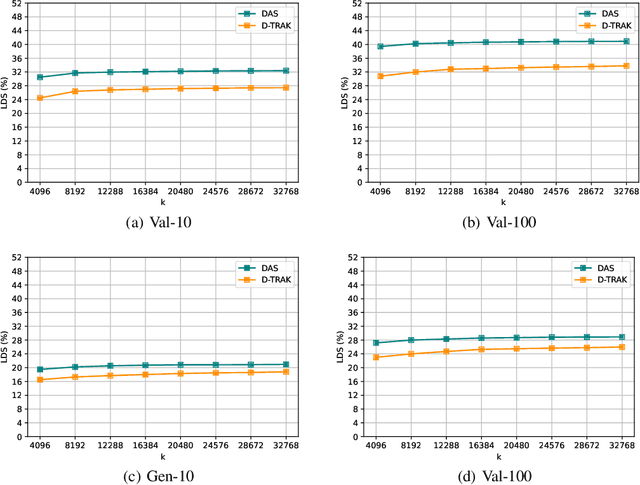
As diffusion models become increasingly popular, the misuse of copyrighted and private images has emerged as a major concern. One promising solution to mitigate this issue is identifying the contribution of specific training samples in generative models, a process known as data attribution. Existing data attribution methods for diffusion models typically quantify the contribution of a training sample by evaluating the change in diffusion loss when the sample is included or excluded from the training process. However, we argue that the direct usage of diffusion loss cannot represent such a contribution accurately due to the calculation of diffusion loss. Specifically, these approaches measure the divergence between predicted and ground truth distributions, which leads to an indirect comparison between the predicted distributions and cannot represent the variances between model behaviors. To address these issues, we aim to measure the direct comparison between predicted distributions with an attribution score to analyse the training sample importance, which is achieved by Diffusion Attribution Score (DAS). Underpinned by rigorous theoretical analysis, we elucidate the effectiveness of DAS. Additionally, we explore strategies to accelerate DAS calculations, facilitating its application to large-scale diffusion models. Our extensive experiments across various datasets and diffusion models demonstrate that DAS significantly surpasses previous benchmarks in terms of the linear data-modelling score, establishing new state-of-the-art performance.