 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration under Ambiguous Ground Truth
Mar 24, 2026Confidence calibration assumes a unique ground-truth label per input, yet this assumption fails wherever annotators genuinely disagree. Post-hoc calibrators fitted on majority-voted labels, the standard single-label targets used in practice, can appear well-calibrated under conventional evaluation yet remain substantially miscalibrated against the underlying annotator distribution. We show that this failure is structural: under simplifying assumptions, Temperature Scaling is biased toward temperatures that underestimate annotator uncertainty, with true-label miscalibration increasing monotonically with annotation entropy. To address this, we develop a family of ambiguity-aware post-hoc calibrators that optimise proper scoring rules against the full label distribution and require no model retraining. Our methods span progressively weaker annotation requirements: Dirichlet-Soft leverages the full annotator distribution and achieves the best overall calibration quality across settings; Monte Carlo Temperature Scaling with a single annotation per example (MCTS S=1) matches full-distribution calibration across all benchmarks, demonstrating that pre-aggregated label distributions are unnecessary; and Label-Smooth Temperature Scaling (LS-TS) operates with voted labels alone by constructing data-driven pseudo-soft targets from the model's own confidence. Experiments on four benchmarks with real multi-annotator distributions (CIFAR-10H, ChaosNLI) and clinically-informed synthetic annotations (ISIC~2019, DermaMNIST) show that Dirichlet-Soft reduces true-label ECE by 55-87% relative to Temperature Scaling, while LS-TS reduces ECE by 9-77% without any annotator data.
Revisiting Uncertainty Estimation and Calibration of Large Language Models
May 29, 2025As large language models (LLMs) are increasingly deployed in high-stakes applications, robust uncertainty estimation is essential for ensuring the safe and trustworthy deployment of LLMs. We present the most comprehensive study to date of uncertainty estimation in LLMs, evaluating 80 models spanning open- and closed-source families, dense and Mixture-of-Experts (MoE) architectures, reasoning and non-reasoning modes, quantization variants and parameter scales from 0.6B to 671B. Focusing on three representative black-box single-pass methods, including token probability-based uncertainty (TPU), numerical verbal uncertainty (NVU), and linguistic verbal uncertainty (LVU), we systematically evaluate uncertainty calibration and selective classification using the challenging MMLU-Pro benchmark, which covers both reasoning-intensive and knowledge-based tasks. Our results show that LVU consistently outperforms TPU and NVU, offering stronger calibration and discrimination while being more interpretable. We also find that high accuracy does not imply reliable uncertainty, and that model scale, post-training, reasoning ability and quantization all influence estimation performance. Notably, LLMs exhibit better uncertainty estimates on reasoning tasks than on knowledge-heavy ones, and good calibration does not necessarily translate to effective error ranking. These findings highlight the need for multi-perspective evaluation and position LVU as a practical tool for improving the reliability of LLMs in real-world settings.
Beyond One-Hot Labels: Semantic Mixing for Model Calibration
Apr 18, 2025
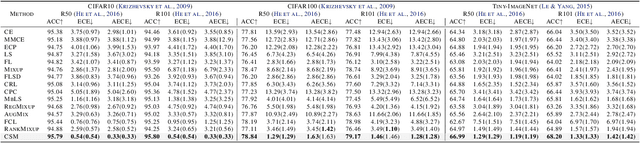
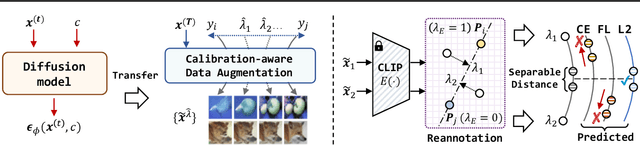

Model calibration seeks to ensure that models produce confidence scores that accurately reflect the true likelihood of their predictions being correct. However, existing calibration approaches are fundamentally tied to datasets of one-hot labels implicitly assuming full certainty in all the annotations. Such datasets are effective for classification but provides insufficient knowledge of uncertainty for model calibration, necessitating the curation of datasets with numerically rich ground-truth confidence values. However, due to the scarcity of uncertain visual examples, such samples are not easily available as real datasets. In this paper, we introduce calibration-aware data augmentation to create synthetic datasets of diverse samples and their ground-truth uncertainty. Specifically, we present Calibration-aware Semantic Mixing (CSM), a novel framework that generates training samples with mixed class characteristics and annotates them with distinct confidence scores via diffusion models. Based on this framework, we propose calibrated reannotation to tackle the misalignment between the annotated confidence score and the mixing ratio during the diffusion reverse process. Besides, we explore the loss functions that better fit the new data representation paradigm. Experimental results demonstrate that CSM achieves superior calibration compared to the state-of-the-art calibration approaches. Code is available at github.com/E-Galois/CSM.
Diffusion Attribution Score: Evaluating Training Data Influence in Diffusion Model
Oct 24, 2024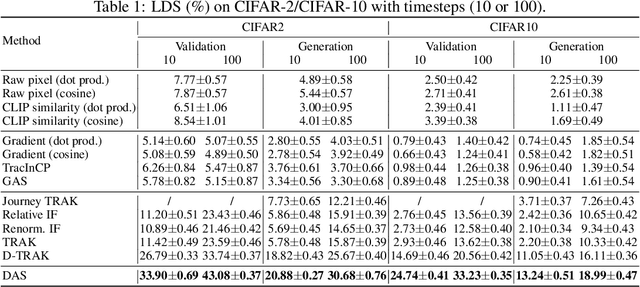


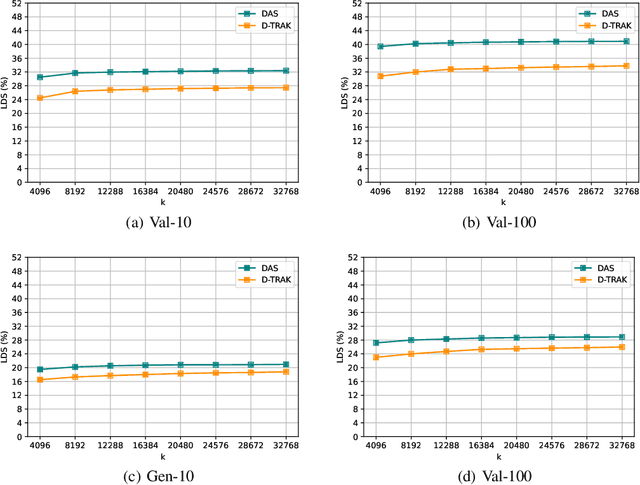
As diffusion models become increasingly popular, the misuse of copyrighted and private images has emerged as a major concern. One promising solution to mitigate this issue is identifying the contribution of specific training samples in generative models, a process known as data attribution. Existing data attribution methods for diffusion models typically quantify the contribution of a training sample by evaluating the change in diffusion loss when the sample is included or excluded from the training process. However, we argue that the direct usage of diffusion loss cannot represent such a contribution accurately due to the calculation of diffusion loss. Specifically, these approaches measure the divergence between predicted and ground truth distributions, which leads to an indirect comparison between the predicted distributions and cannot represent the variances between model behaviors. To address these issues, we aim to measure the direct comparison between predicted distributions with an attribution score to analyse the training sample importance, which is achieved by Diffusion Attribution Score (DAS). Underpinned by rigorous theoretical analysis, we elucidate the effectiveness of DAS. Additionally, we explore strategies to accelerate DAS calculations, facilitating its application to large-scale diffusion models. Our extensive experiments across various datasets and diffusion models demonstrate that DAS significantly surpasses previous benchmarks in terms of the linear data-modelling score, establishing new state-of-the-art performance.
Consistency Calibration: Improving Uncertainty Calibration via Consistency among Perturbed Neighbors
Oct 16, 2024Calibration is crucial in deep learning applications, especially in fields like healthcare and autonomous driving, where accurate confidence estimates are vital for decision-making. However, deep neural networks often suffer from miscalibration, with reliability diagrams and Expected Calibration Error (ECE) being the only standard perspective for evaluating calibration performance. In this paper, we introduce the concept of consistency as an alternative perspective on model calibration, inspired by uncertainty estimation literature in large language models (LLMs). We highlight its advantages over the traditional reliability-based view. Building on this concept, we propose a post-hoc calibration method called Consistency Calibration (CC), which adjusts confidence based on the model's consistency across perturbed inputs. CC is particularly effective in locally uncertainty estimation, as it requires no additional data samples or label information, instead generating input perturbations directly from the source data. Moreover, we show that performing perturbations at the logit level significantly improves computational efficiency. We validate the effectiveness of CC through extensive comparisons with various post-hoc and training-time calibration methods, demonstrating state-of-the-art performance on standard datasets such as CIFAR-10, CIFAR-100, and ImageNet, as well as on long-tailed datasets like ImageNet-LT.
Visual Imitation Learning with Calibrated Contrastive Representation
Jan 21, 2024Adversarial Imitation Learning (AIL) allows the agent to reproduce expert behavior with low-dimensional states and actions. However, challenges arise in handling visual states due to their less distinguishable representation compared to low-dimensional proprioceptive features. While existing methods resort to adopt complex network architectures or separate the process of learning representation and decision-making, they overlook valuable intra-agent information within demonstrations. To address this problem, this paper proposes a simple and effective solution by incorporating calibrated contrastive representative learning into visual AIL framework. Specifically, we present an image encoder in visual AIL, utilizing a combination of unsupervised and supervised contrastive learning to extract valuable features from visual states. Based on the fact that the improved agent often produces demonstrations of varying quality, we propose to calibrate the contrastive loss by treating each agent demonstrations as a mixed sample. The incorporation of contrastive learning can be jointly optimized with the AIL framework, without modifying the architecture or incurring significant computational costs. Experimental results on DMControl Suite demonstrate our proposed method is sample efficient and can outperform other compared methods from different aspects.
A Benchmark Study on Calibration
Aug 23, 2023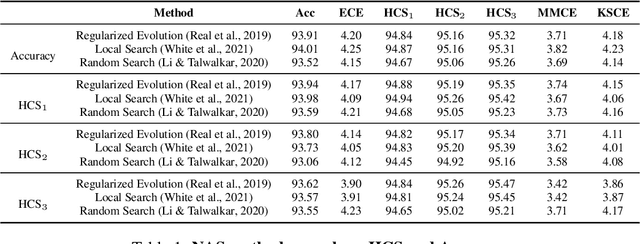
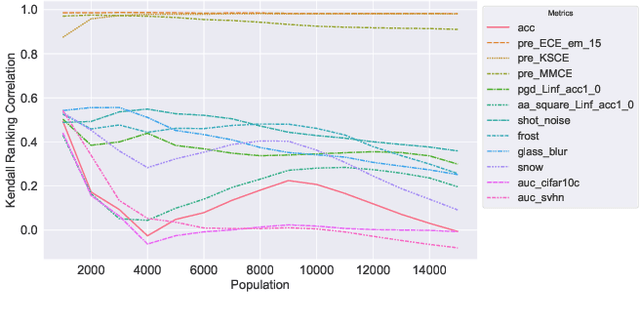
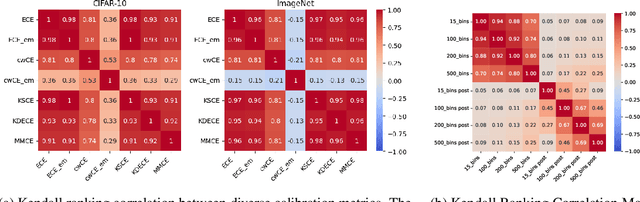
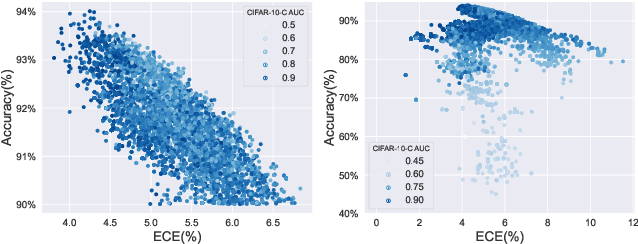
Deep neural networks are increasingly utilized in various machine learning tasks. However, as these models grow in complexity, they often face calibration issues, despite enhanced prediction accuracy. Many studies have endeavored to improve calibration performance through data preprocessing, the use of specific loss functions, and training frameworks. Yet, investigations into calibration properties have been somewhat overlooked. Our study leverages the Neural Architecture Search (NAS) search space, offering an exhaustive model architecture space for thorough calibration properties exploration. We specifically create a model calibration dataset. This dataset evaluates 90 bin-based and 12 additional calibration measurements across 117,702 unique neural networks within the widely employed NATS-Bench search space. Our analysis aims to answer several longstanding questions in the field, using our proposed dataset: (i) Can model calibration be generalized across different tasks? (ii) Can robustness be used as a calibration measurement? (iii) How reliable are calibration metrics? (iv) Does a post-hoc calibration method affect all models uniformly? (v) How does calibration interact with accuracy? (vi) What is the impact of bin size on calibration measurement? (vii) Which architectural designs are beneficial for calibration? Additionally, our study bridges an existing gap by exploring calibration within NAS. By providing this dataset, we enable further research into NAS calibration. As far as we are aware, our research represents the first large-scale investigation into calibration properties and the premier study of calibration issues within NAS.
Dual Focal Loss for Calibration
May 23, 2023The use of deep neural networks in real-world applications require well-calibrated networks with confidence scores that accurately reflect the actual probability. However, it has been found that these networks often provide over-confident predictions, which leads to poor calibration. Recent efforts have sought to address this issue by focal loss to reduce over-confidence, but this approach can also lead to under-confident predictions. While different variants of focal loss have been explored, it is difficult to find a balance between over-confidence and under-confidence. In our work, we propose a new loss function by focusing on dual logits. Our method not only considers the ground truth logit, but also take into account the highest logit ranked after the ground truth logit. By maximizing the gap between these two logits, our proposed dual focal loss can achieve a better balance between over-confidence and under-confidence. We provide theoretical evidence to support our approach and demonstrate its effectiveness through evaluations on multiple models and datasets, where it achieves state-of-the-art performance. Code is available at https://github.com/Linwei94/DualFocalLoss
Calibrating a Deep Neural Network with Its Predecessors
Feb 13, 2023



Confidence calibration - the process to calibrate the output probability distribution of neural networks - is essential for safety-critical applications of such networks. Recent works verify the link between mis-calibration and overfitting. However, early stopping, as a well-known technique to mitigate overfitting, fails to calibrate networks. In this work, we study the limitions of early stopping and comprehensively analyze the overfitting problem of a network considering each individual block. We then propose a novel regularization method, predecessor combination search (PCS), to improve calibration by searching a combination of best-fitting block predecessors, where block predecessors are the corresponding network blocks with weight parameters from earlier training stages. PCS achieves the state-of-the-art calibration performance on multiple datasets and architectures. In addition, PCS improves model robustness under dataset distribution shift.