 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotlighting Partially Visible Cinematic Language for Video-to-Audio Generation via Self-distillation
Jul 03, 2025Video-to-Audio (V2A) Generation achieves significant progress and plays a crucial role in film and video post-production. However, current methods overlook the cinematic language, a critical component of artistic expression in filmmaking. As a result, their performance deteriorates in scenarios where Foley targets are only partially visible. To address this challenge, we propose a simple self-distillation approach to extend V2A models to cinematic language scenarios. By simulating the cinematic language variations, the student model learns to align the video features of training pairs with the same audio-visual correspondences, enabling it to effectively capture the associations between sounds and partial visual information. Our method not only achieves impressive improvements under partial visibility across all evaluation metrics, but also enhances performance on the large-scale V2A dataset, VGGSound.
MAC: A Benchmark for Multiple Attributes Compositional Zero-Shot Learning
Jun 18, 2024

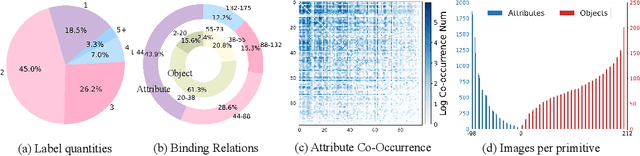

Compositional Zero-Shot Learning (CZSL) aims to learn semantic primitives (attributes and objects) from seen compositions and recognize unseen attribute-object compositions. Existing CZSL datasets focus on single attributes, neglecting the fact that objects naturally exhibit multiple interrelated attributes. Real-world objects often possess multiple interrelated attributes, and current datasets' narrow attribute scope and single attribute labeling introduce annotation biases, undermining model performance and evaluation. To address these limitations, we introduce the Multi-Attribute Composition (MAC) dataset, encompassing 18,217 images and 11,067 compositions with comprehensive, representative, and diverse attribute annotations. MAC includes an average of 30.2 attributes per object and 65.4 objects per attribute, facilitating better multi-attribute composition predictions. Our dataset supports deeper semantic understanding and higher-order attribute associations, providing a more realistic and challenging benchmark for the CZSL task. We also develop solutions for multi-attribute compositional learning and propose the MM-encoder to disentangling the attributes and objects.
Improving Bird's Eye View Semantic Segmentation by Task Decomposition
Apr 02, 2024



Semantic segmentation in bird's eye view (BEV) plays a crucial role in autonomous driving. Previous methods usually follow an end-to-end pipeline, directly predicting the BEV segmentation map from monocular RGB inputs. However, the challenge arises when the RGB inputs and BEV targets from distinct perspectives, making the direct point-to-point predicting hard to optimize. In this paper, we decompose the original BEV segmentation task into two stages, namely BEV map reconstruction and RGB-BEV feature alignment. In the first stage, we train a BEV autoencoder to reconstruct the BEV segmentation maps given corrupted noisy latent representation, which urges the decoder to learn fundamental knowledge of typical BEV patterns. The second stage involves mapping RGB input images into the BEV latent space of the first stage, directly optimizing the correlations between the two views at the feature level. Our approach simplifies the complexity of combining perception and generation into distinct steps, equipping the model to handle intricate and challenging scenes effectively. Besides, we propose to transform the BEV segmentation map from the Cartesian to the polar coordinate system to establish the column-wise correspondence between RGB images and BEV maps. Moreover, our method requires neither multi-scale features nor camera intrinsic parameters for depth estimation and saves computational overhead. Extensive experiments on nuScenes and Argoverse show the effectiveness and efficiency of our method. Code is available at https://github.com/happytianhao/TaDe.
Visual Imitation Learning with Calibrated Contrastive Representation
Jan 21, 2024Adversarial Imitation Learning (AIL) allows the agent to reproduce expert behavior with low-dimensional states and actions. However, challenges arise in handling visual states due to their less distinguishable representation compared to low-dimensional proprioceptive features. While existing methods resort to adopt complex network architectures or separate the process of learning representation and decision-making, they overlook valuable intra-agent information within demonstrations. To address this problem, this paper proposes a simple and effective solution by incorporating calibrated contrastive representative learning into visual AIL framework. Specifically, we present an image encoder in visual AIL, utilizing a combination of unsupervised and supervised contrastive learning to extract valuable features from visual states. Based on the fact that the improved agent often produces demonstrations of varying quality, we propose to calibrate the contrastive loss by treating each agent demonstrations as a mixed sample. The incorporation of contrastive learning can be jointly optimized with the AIL framework, without modifying the architecture or incurring significant computational costs. Experimental results on DMControl Suite demonstrate our proposed method is sample efficient and can outperform other compared methods from different aspects.
Revisit Weakly-Supervised Audio-Visual Video Parsing from the Language Perspective
Jun 14, 2023



We focus on the weakly-supervised audio-visual video parsing task (AVVP), which aims to identify and locate all the events in audio/visual modalities. Previous works only concentrate on video-level overall label denoising across modalities, but overlook the segment-level label noise, where adjacent video segments (i.e., 1-second video clips) may contain different events. However, recognizing events in the segment is challenging because its label could be any combination of events that occur in the video. To address this issue, we consider tackling AVVP from the language perspective, since language could freely describe how various events appear in each segment beyond fixed labels. Specifically, we design language prompts to describe all cases of event appearance for each video. Then, the similarity between language prompts and segments is calculated, where the event of the most similar prompt is regarded as the segment-level label. In addition, to deal with the mislabeled segments, we propose to perform dynamic re-weighting on the unreliable segments to adjust their labels. Experiments show that our simple yet effective approach outperforms state-of-the-art methods by a large margin.
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Feb 16, 2023Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could ntroduce extra noise, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. In this way, the modellearns to recognize a person through patches of different styles, and the modality semantic correspondence is directly embodied. With the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. In addition, the relationship between identity centers among modalities is explored to further reduce the modality variance, and the global-to-part constraint is introduced to regularize representation learning of part features. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
MixSiam: A Mixture-based Approach to Self-supervised Representation Learning
Nov 04, 2021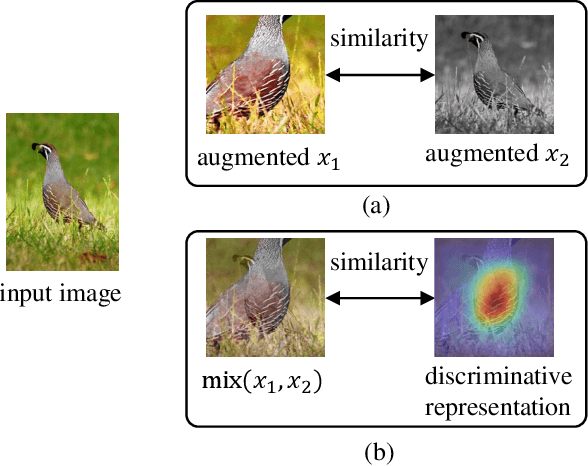
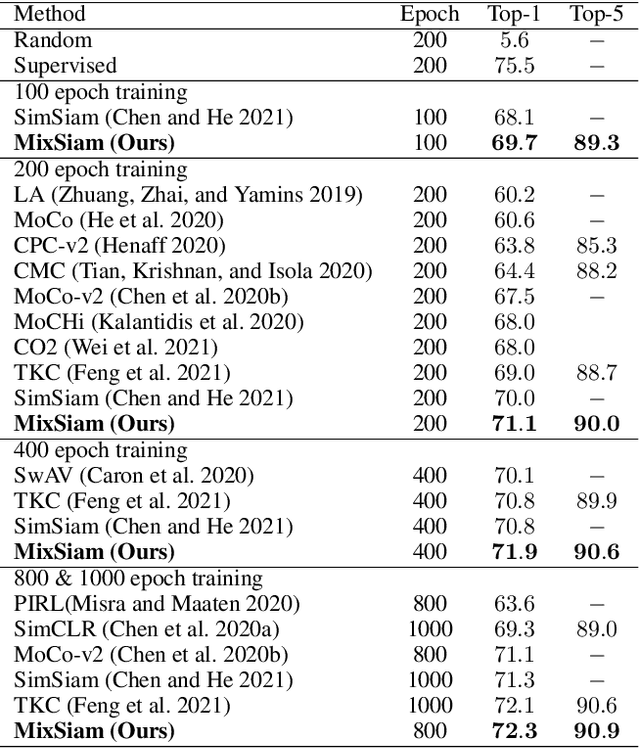
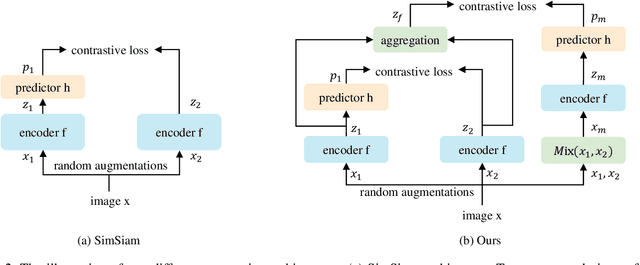
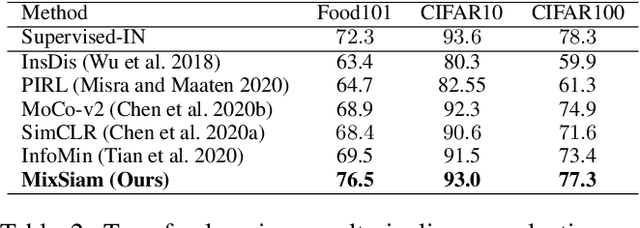
Recently contrastive learning has shown significant progress in learning visual representations from unlabeled data. The core idea is training the backbone to be invariant to different augmentations of an instance. While most methods only maximize the feature similarity between two augmented data, we further generate more challenging training samples and force the model to keep predicting discriminative representation on these hard samples. In this paper, we propose MixSiam, a mixture-based approach upon the traditional siamese network. On the one hand, we input two augmented images of an instance to the backbone and obtain the discriminative representation by performing an element-wise maximum of two features. On the other hand, we take the mixture of these augmented images as input, and expect the model prediction to be close to the discriminative representation. In this way, the model could access more variant data samples of an instance and keep predicting invariant discriminative representations for them. Thus the learned model is more robust compared to previous contrastive learning methods. Extensive experiments on large-scale datasets show that MixSiam steadily improves the baseline and achieves competitive results with state-of-the-art methods. Our code will be released soon.
Unsupervised Person Re-identification with Stochastic Training Strategy
Aug 16, 2021

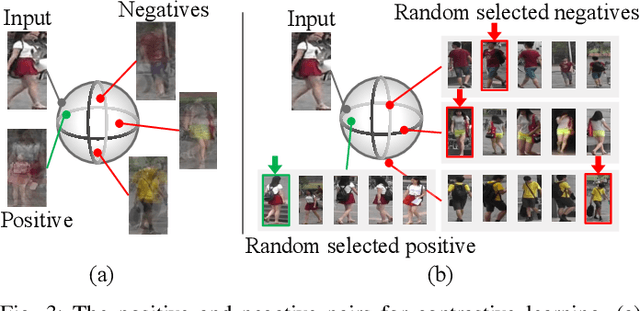
Unsupervised person re-identification (re-ID) has attracted increasing research interests because of its scalability and possibility for real-world applications. State-of-the-art unsupervised re-ID methods usually follow a clustering-based strategy, which generates pseudo labels by clustering and maintains a memory to store instance features and represent the centroid of the clusters for contrastive learning. This approach suffers two problems. First, the centroid generated by unsupervised learning may not be a perfect prototype. Forcing images to get closer to the centroid emphasizes the result of clustering, which could accumulate clustering errors during iterations. Second, previous methods utilize features obtained at different training iterations to represent one centroid, which is not consistent with the current training sample, since the features are not directly comparable. To this end, we propose an unsupervised re-ID approach with a stochastic learning strategy. Specifically, we adopt a stochastic updated memory, where a random instance from a cluster is used to update the cluster-level memory for contrastive learning. In this way, the relationship between randomly selected pair of images are learned to avoid the training bias caused by unreliable pseudo labels. The stochastic memory is also always up-to-date for classifying to keep the consistency. Besides, to relieve the issue of camera variance, a unified distance matrix is proposed during clustering, where the distance bias from different camera domain is reduced and the variances of identities is emphasized.
Re-identification = Retrieval + Verification: Back to Essence and Forward with a New Metric
Nov 23, 2020



Re-identification (re-ID) is currently investigated as a closed-world image retrieval task, and evaluated by retrieval based metrics. The algorithms return ranking lists to users, but cannot tell which images are the true target. In essence, current re-ID overemphasizes the importance of retrieval but underemphasizes that of verification, \textit{i.e.}, all returned images are considered as the target. On the other hand, re-ID should also include the scenario that the query identity does not appear in the gallery. To this end, we go back to the essence of re-ID, \textit{i.e.}, a combination of retrieval and verification in an open-set setting, and put forward a new metric, namely, Genuine Open-set re-ID Metric (GOM). GOM explicitly balances the effect of performing retrieval and verification into a single unified metric. It can also be decomposed into a family of sub-metrics, enabling a clear analysis of re-ID performance. We evaluate the effectiveness of GOM on the re-ID benchmarks, showing its ability to capture important aspects of re-ID performance that have not been taken into account by established metrics so far. Furthermore, we show GOM scores excellent in aligning with human visual evaluation of re-ID performance. Related codes are available at https://github.com/YuanXinCherry/Person-reID-Evaluation
Unsupervised Person Re-identification via Softened Similarity Learning
Apr 07, 2020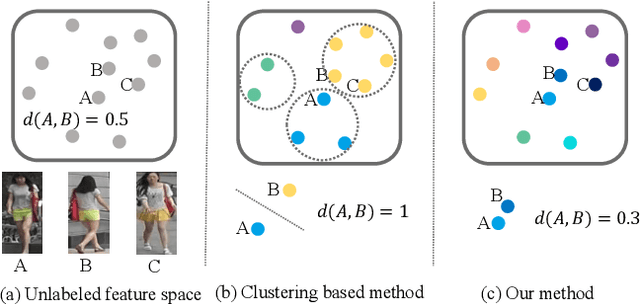


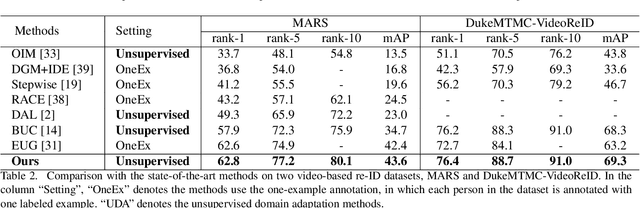
Person re-identification (re-ID) is an important topic in computer vision. This paper studies the unsupervised setting of re-ID, which does not require any labeled information and thus is freely deployed to new scenarios. There are very few studies under this setting, and one of the best approach till now used iterative clustering and classification, so that unlabeled images are clustered into pseudo classes for a classifier to get trained, and the updated features are used for clustering and so on. This approach suffers two problems, namely, the difficulty of determining the number of clusters, and the hard quantization loss in clustering. In this paper, we follow the iterative training mechanism but discard clustering, since it incurs loss from hard quantization, yet its only product, image-level similarity, can be easily replaced by pairwise computation and a softened classification task. With these improvements, our approach becomes more elegant and is more robust to hyper-parameter changes. Experiments on two image-based and video-based datasets demonstrate state-of-the-art performance under the unsupervised re-ID setting.