 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiskProp: Collision-Anchored Self-Supervised Risk Propagation for Early Accident Anticipation
Mar 28, 2026Accident anticipation aims to predict impending collisions from dashcam videos and trigger early alerts. Existing methods rely on binary supervision with manually annotated "anomaly onset" frames, which are subjective and inconsistent, leading to inaccurate risk estimation. In contrast, we propose RiskProp, a novel collision-anchored self-supervised risk propagation paradigm for early accident anticipation, which removes the need for anomaly onset annotations and leverages only the reliably annotated collision frame. RiskProp models temporal risk evolution through two observation-driven losses: first, since future frames contain more definitive evidence of an impending accident, we introduce a future-frame regularization loss that uses the model's next-frame prediction as a soft target to supervise the current frame, enabling backward propagation of risk signals; second, inspired by the empirical trend of rising risk before accidents, we design an adaptive monotonic constraint to encourage a non-decreasing progression over time. Experiments on CAP and Nexar demonstrate that RiskProp achieves state-of-the-art performance and produces smoother, more discriminative risk curves, improving both early anticipation and interpretability.
Improving Bird's Eye View Semantic Segmentation by Task Decomposition
Apr 02, 2024



Semantic segmentation in bird's eye view (BEV) plays a crucial role in autonomous driving. Previous methods usually follow an end-to-end pipeline, directly predicting the BEV segmentation map from monocular RGB inputs. However, the challenge arises when the RGB inputs and BEV targets from distinct perspectives, making the direct point-to-point predicting hard to optimize. In this paper, we decompose the original BEV segmentation task into two stages, namely BEV map reconstruction and RGB-BEV feature alignment. In the first stage, we train a BEV autoencoder to reconstruct the BEV segmentation maps given corrupted noisy latent representation, which urges the decoder to learn fundamental knowledge of typical BEV patterns. The second stage involves mapping RGB input images into the BEV latent space of the first stage, directly optimizing the correlations between the two views at the feature level. Our approach simplifies the complexity of combining perception and generation into distinct steps, equipping the model to handle intricate and challenging scenes effectively. Besides, we propose to transform the BEV segmentation map from the Cartesian to the polar coordinate system to establish the column-wise correspondence between RGB images and BEV maps. Moreover, our method requires neither multi-scale features nor camera intrinsic parameters for depth estimation and saves computational overhead. Extensive experiments on nuScenes and Argoverse show the effectiveness and efficiency of our method. Code is available at https://github.com/happytianhao/TaDe.
Hybrid Adaptive Fuzzy Extreme Learning Machine for text classification
May 10, 2018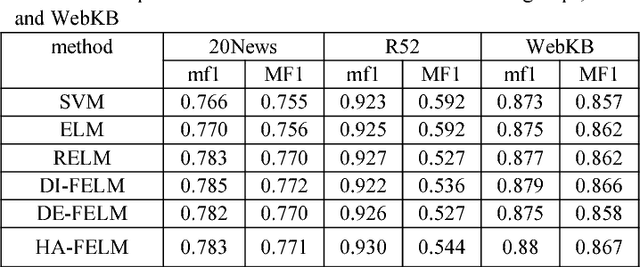
In traditional ELM and its improved versions suffer from the problems of outliers or noises due to overfitting and imbalance due to distribution. We propose a novel hybrid adaptive fuzzy ELM(HA-FELM), which introduces a fuzzy membership function to the traditional ELM method to deal with the above problems. We define the fuzzy membership function not only basing on the distance between each sample and the center of the class but also the density among samples which based on the quantum harmonic oscillator model. The proposed fuzzy membership function overcomes the shortcoming of the traditional fuzzy membership function and could make itself adjusted according to the specific distribution of different samples adaptively. Experiments show the proposed HA-FELM can produce better performance than SVM, ELM, and RELM in text classification.
Text classification based on ensemble extreme learning machine
May 10, 2018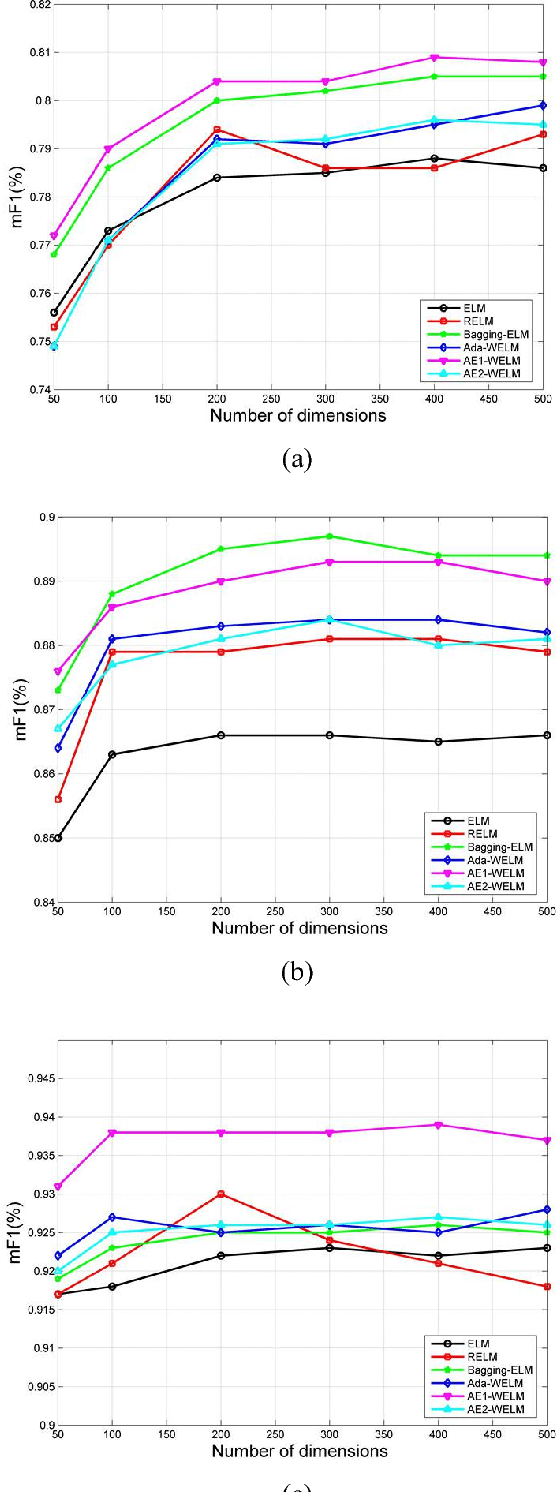
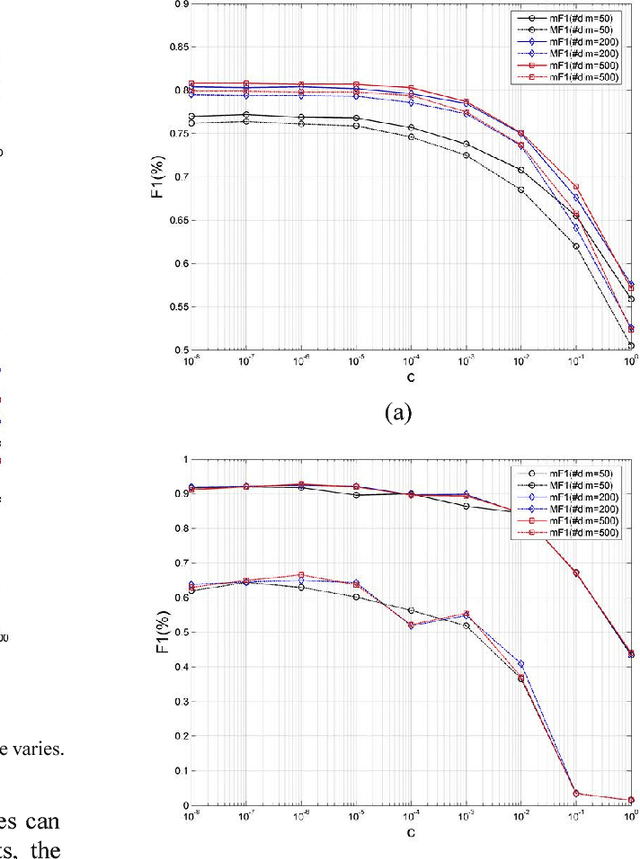
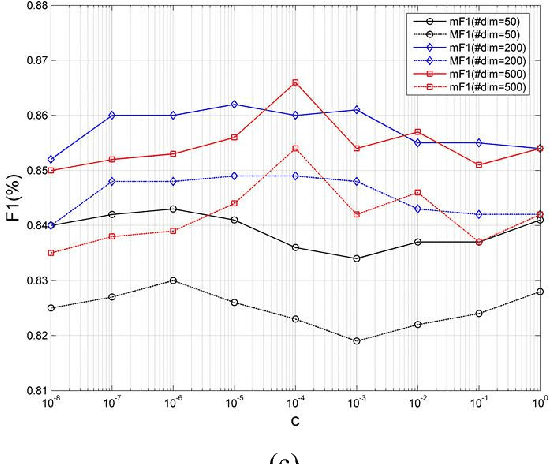
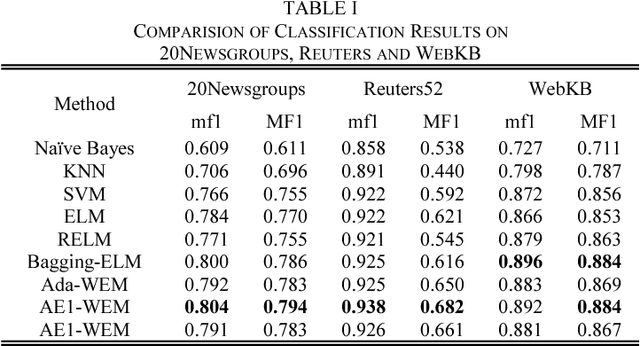
In this paper, we propose a novel approach based on cost-sensitive ensemble weighted extreme learning machine; we call this approach AE1-WELM. We apply this approach to text classification. AE1-WELM is an algorithm including balanced and imbalanced multiclassification for text classification. Weighted ELM assigning the different weights to the different samples improves the classification accuracy to a certain extent, but weighted ELM considers the differences between samples in the different categories only and ignores the differences between samples within the same categories. We measure the importance of the documents by the sample information entropy, and generate cost-sensitive matrix and factor based on the document importance, then embed the cost-sensitive weighted ELM into the AdaBoost.M1 framework seamlessly. Vector space model(VSM) text representation produces the high dimensions and sparse features which increase the burden of ELM. To overcome this problem, we develop a text classification framework combining the word vector and AE1-WELM. The experimental results show that our method provides an accurate, reliable and effective solution for text classification.
A WL-SPPIM Semantic Model for Document Classification
May 26, 2017
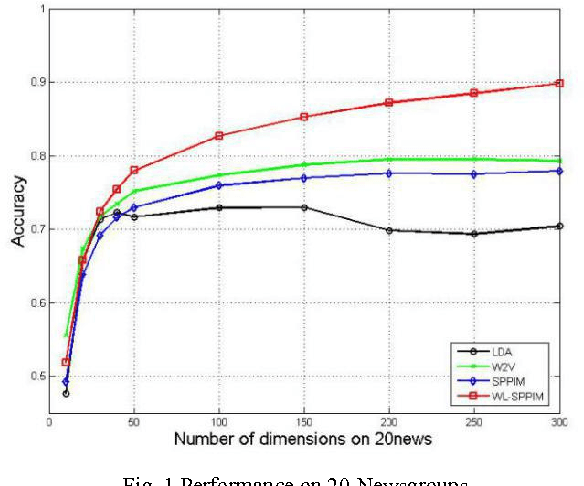
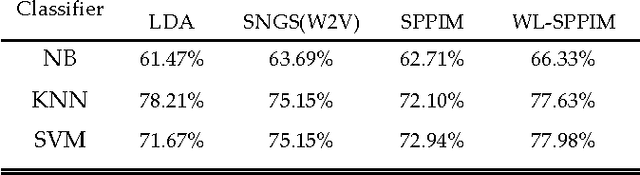
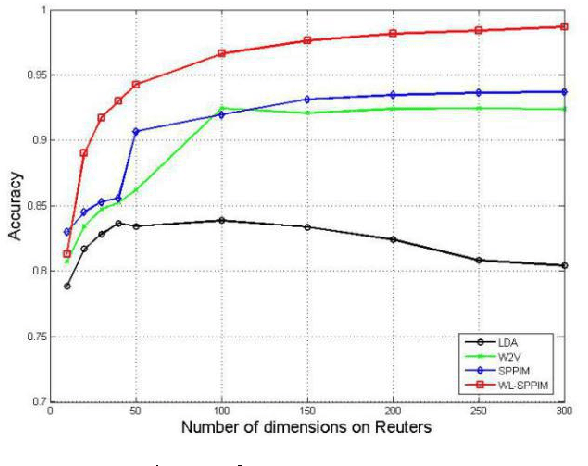
In this paper, we explore SPPIM-based text classification method, and the experiment reveals that the SPPIM method is equal to or even superior than SGNS method in text classification task on three international and standard text datasets, namely 20newsgroups, Reuters52 and WebKB. Comparing to SGNS, although SPPMI provides a better solution, it is not necessarily better than SGNS in text classification tasks. Based on our analysis, SGNS takes into the consideration of weight calculation during decomposition process, so it has better performance than SPPIM in some standard datasets. Inspired by this, we propose a WL-SPPIM semantic model based on SPPIM model, and experiment shows that WL-SPPIM approach has better classification and higher scalability in the text classification task compared with LDA, SGNS and SPPIM approaches.