 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Counterattacks: Orthogonal Exploration for Robust CLIP Inference
Nov 12, 2025Vision-language pre-training models (VLPs) demonstrate strong multimodal understanding and zero-shot generalization, yet remain vulnerable to adversarial examples, raising concerns about their reliability. Recent work, Test-Time Counterattack (TTC), improves robustness by generating perturbations that maximize the embedding deviation of adversarial inputs using PGD, pushing them away from their adversarial representations. However, due to the fundamental difference in optimization objectives between adversarial attacks and counterattacks, generating counterattacks solely based on gradients with respect to the adversarial input confines the search to a narrow space. As a result, the counterattacks could overfit limited adversarial patterns and lack the diversity to fully neutralize a broad range of perturbations. In this work, we argue that enhancing the diversity and coverage of counterattacks is crucial to improving adversarial robustness in test-time defense. Accordingly, we propose Directional Orthogonal Counterattack (DOC), which augments counterattack optimization by incorporating orthogonal gradient directions and momentum-based updates. This design expands the exploration of the counterattack space and increases the diversity of perturbations, which facilitates the discovery of more generalizable counterattacks and ultimately improves the ability to neutralize adversarial perturbations. Meanwhile, we present a directional sensitivity score based on averaged cosine similarity to boost DOC by improving example discrimination and adaptively modulating the counterattack strength. Extensive experiments on 16 datasets demonstrate that DOC improves adversarial robustness under various attacks while maintaining competitive clean accuracy. Code is available at https://github.com/bookman233/DOC.
Survey of Adversarial Robustness in Multimodal Large Language Models
Mar 18, 2025


Multimodal Large Language Models (MLLMs) have demonstrated exceptional performance in artificial intelligence by facilitating integrated understanding across diverse modalities, including text, images, video, audio, and speech. However, their deployment in real-world applications raises significant concerns about adversarial vulnerabilities that could compromise their safety and reliability. Unlike unimodal models, MLLMs face unique challenges due to the interdependencies among modalities, making them susceptible to modality-specific threats and cross-modal adversarial manipulations. This paper reviews the adversarial robustness of MLLMs, covering different modalities. We begin with an overview of MLLMs and a taxonomy of adversarial attacks tailored to each modality. Next, we review key datasets and evaluation metrics used to assess the robustness of MLLMs. After that, we provide an in-depth review of attacks targeting MLLMs across different modalities. Our survey also identifies critical challenges and suggests promising future research directions.
Improving Fast Adversarial Training via Self-Knowledge Guidance
Sep 26, 2024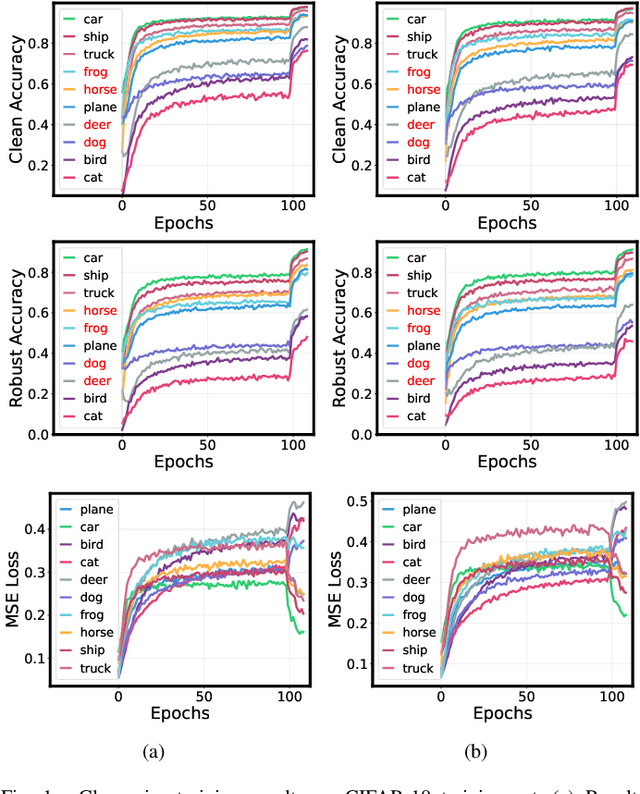
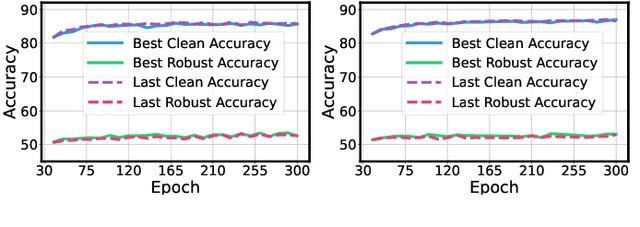
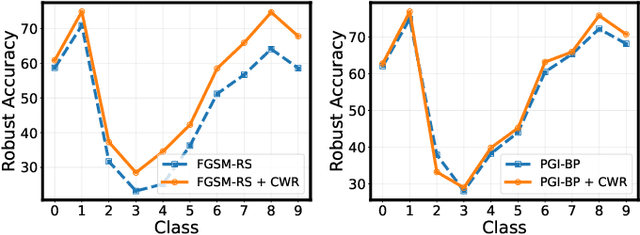
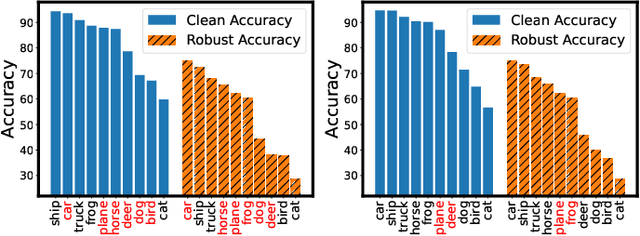
Adversarial training has achieved remarkable advancements in defending against adversarial attacks. Among them, fast adversarial training (FAT) is gaining attention for its ability to achieve competitive robustness with fewer computing resources. Existing FAT methods typically employ a uniform strategy that optimizes all training data equally without considering the influence of different examples, which leads to an imbalanced optimization. However, this imbalance remains unexplored in the field of FAT. In this paper, we conduct a comprehensive study of the imbalance issue in FAT and observe an obvious class disparity regarding their performances. This disparity could be embodied from a perspective of alignment between clean and robust accuracy. Based on the analysis, we mainly attribute the observed misalignment and disparity to the imbalanced optimization in FAT, which motivates us to optimize different training data adaptively to enhance robustness. Specifically, we take disparity and misalignment into consideration. First, we introduce self-knowledge guided regularization, which assigns differentiated regularization weights to each class based on its training state, alleviating class disparity. Additionally, we propose self-knowledge guided label relaxation, which adjusts label relaxation according to the training accuracy, alleviating the misalignment and improving robustness. By combining these methods, we formulate the Self-Knowledge Guided FAT (SKG-FAT), leveraging naturally generated knowledge during training to enhance the adversarial robustness without compromising training efficiency. Extensive experiments on four standard datasets demonstrate that the SKG-FAT improves the robustness and preserves competitive clean accuracy, outperforming the state-of-the-art methods.
Taxonomy Driven Fast Adversarial Training
Jul 22, 2024Adversarial training (AT) is an effective defense method against gradient-based attacks to enhance the robustness of neural networks. Among them, single-step AT has emerged as a hotspot topic due to its simplicity and efficiency, requiring only one gradient propagation in generating adversarial examples. Nonetheless, the problem of catastrophic overfitting (CO) that causes training collapse remains poorly understood, and there exists a gap between the robust accuracy achieved through single- and multi-step AT. In this paper, we present a surprising finding that the taxonomy of adversarial examples reveals the truth of CO. Based on this conclusion, we propose taxonomy driven fast adversarial training (TDAT) which jointly optimizes learning objective, loss function, and initialization method, thereby can be regarded as a new paradigm of single-step AT. Compared with other fast AT methods, TDAT can boost the robustness of neural networks, alleviate the influence of misclassified examples, and prevent CO during the training process while requiring almost no additional computational and memory resources. Our method achieves robust accuracy improvement of $1.59\%$, $1.62\%$, $0.71\%$, and $1.26\%$ on CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet-100 datasets, when against projected gradient descent PGD10 attack with perturbation budget 8/255. Furthermore, our proposed method also achieves state-of-the-art robust accuracy against other attacks. Code is available at https://github.com/bookman233/TDAT.
Residual-Based Adaptive Coefficient and Noise-Immunity ZNN for Perturbed Time-Dependent Quadratic Minimization
Dec 03, 2021



The time-dependent quadratic minimization (TDQM) problem appears in many applications and research projects. It has been reported that the zeroing neural network (ZNN) models can effectively solve the TDQM problem. However, the convergent and robust performance of the existing ZNN models are restricted for lack of a joint-action mechanism of adaptive coefficient and integration enhanced term. Consequently, the residual-based adaption coefficient zeroing neural network (RACZNN) model with integration term is proposed in this paper for solving the TDQM problem. The adaptive coefficient is proposed to improve the performance of convergence and the integration term is embedded to ensure the RACZNN model can maintain reliable robustness while perturbed by variant measurement noises. Compared with the state-of-the-art models, the proposed RACZNN model owns faster convergence and more reliable robustness. Then, theorems are provided to prove the convergence of the RACZNN model. Finally, corresponding quantitative numerical experiments are designed and performed in this paper to verify the performance of the proposed RACZNN model.