 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS2AD-LiDAR: End-to-End Autonomous Driving LiDAR Data Generation from Roadside Sensor Observations
May 22, 2026End-to-end autonomous driving solutions, which directly process multimodal sensory data and output fine-grained control commands, have gradually become a mainstream direction with the development of autonomous driving technology. However, current methods in this category rely on single-vehicle data collection for model training and optimization, which suffers from high acquisition and annotation costs, scarcity of valuable scenarios, and data silos. To address these challenges, we propose RS2AD-LiDAR, a novel framework for reconstructing and generating vehicle-mounted LiDAR data from roadside sensor observations. Since no public dataset currently provides highly overlapping perception coverage between roadside and vehicle-mounted LiDAR sensors, which is essential for studying roadside-to-vehicle data generation, we constructed a dedicated dataset named R2V-LiDAR which is used solely for evaluation in this work. Specifically, our method transforms roadside LiDAR point clouds into the vehicle-mounted LiDAR coordinate system, and synthesizes high-fidelity vehicle-mounted data via virtual LiDAR modeling and point cloud resampling techniques. To the best of our knowledge, this is the first approach to reconstruct vehicle-mounted LiDAR data from roadside sensor inputs. Extensive experimental comparisons demonstrate the semantic similarity between the generated data and real data. Furthermore, object detection experiments show that incorporating the generated data into real data for model training improves both Bird's Eye View (BEV) and 3D detection accuracy, thereby validating the effectiveness of the proposed method.
Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal Large Language Models
Apr 08, 2026MLLMs require high-resolution visual inputs for fine-grained tasks like document understanding and dense scene perception. However, current global resolution scaling paradigms indiscriminately flood the quadratic self-attention mechanism with visually redundant tokens, severely bottlenecking inference throughput while ignoring spatial sparsity and query intent. To overcome this, we propose Q-Zoom, a query-aware adaptive high-resolution perception framework that operates in an efficient coarse-to-fine manner. First, a lightweight Dynamic Gating Network safely bypasses high-resolution processing when coarse global features suffice. Second, for queries demanding fine-grained perception, a Self-Distilled Region Proposal Network (SD-RPN) precisely localizes the task-relevant Region-of-Interest (RoI) directly from intermediate feature spaces. To optimize these modules efficiently, the gating network uses a consistency-aware generation strategy to derive deterministic routing labels, while the SD-RPN employs a fully self-supervised distillation paradigm. A continuous spatio-temporal alignment scheme and targeted fine-tuning then seamlessly fuse the dense local RoI with the coarse global layout. Extensive experiments demonstrate that Q-Zoom establishes a dominant Pareto frontier. Using Qwen2.5-VL-7B as a primary testbed, Q-Zoom accelerates inference by 2.52 times on Document & OCR benchmarks and 4.39 times in High-Resolution scenarios while matching the baseline's peak accuracy. Furthermore, when configured for maximum perceptual fidelity, Q-Zoom surpasses the baseline's peak performance by 1.1% and 8.1% on these respective benchmarks. These robust improvements transfer seamlessly to Qwen3-VL, LLaVA, and emerging RL-based thinking-with-image models. Project page is available at https://yuhengsss.github.io/Q-Zoom/.
Action-aware Dynamic Pruning for Efficient Vision-Language-Action Manipulation
Sep 26, 2025Robotic manipulation with Vision-Language-Action models requires efficient inference over long-horizon multi-modal context, where attention to dense visual tokens dominates computational cost. Existing methods optimize inference speed by reducing visual redundancy within VLA models, but they overlook the varying redundancy across robotic manipulation stages. We observe that the visual token redundancy is higher in coarse manipulation phase than in fine-grained operations, and is strongly correlated with the action dynamic. Motivated by this observation, we propose \textbf{A}ction-aware \textbf{D}ynamic \textbf{P}runing (\textbf{ADP}), a multi-modal pruning framework that integrates text-driven token selection with action-aware trajectory gating. Our method introduces a gating mechanism that conditions the pruning signal on recent action trajectories, using past motion windows to adaptively adjust token retention ratios in accordance with dynamics, thereby balancing computational efficiency and perceptual precision across different manipulation stages. Extensive experiments on the LIBERO suites and diverse real-world scenarios demonstrate that our method significantly reduces FLOPs and action inference latency (\textit{e.g.} $1.35 \times$ speed up on OpenVLA-OFT) while maintaining competitive success rates (\textit{e.g.} 25.8\% improvements with OpenVLA) compared to baselines, thereby providing a simple plug-in path to efficient robot policies that advances the efficiency and performance frontier of robotic manipulation. Our project website is: \href{https://vla-adp.github.io/}{ADP.com}.
Harnessing Vision Foundation Models for High-Performance, Training-Free Open Vocabulary Segmentation
Nov 14, 2024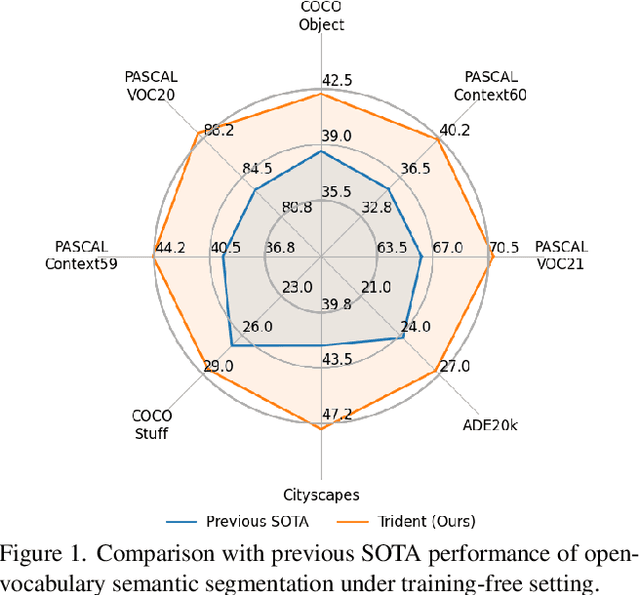


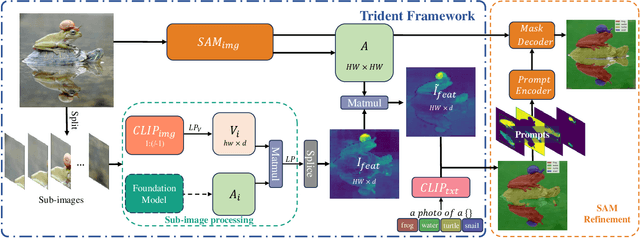
While Contrastive Language-Image Pre-training (CLIP) has advanced open-vocabulary predictions, its performance on semantic segmentation remains suboptimal. This shortfall primarily stems from its spatial-invariant semantic features and constrained resolution. While previous adaptations addressed spatial invariance semantic by modifying the self-attention in CLIP's image encoder, the issue of limited resolution remains unexplored. Different from previous segment-then-splice methods that segment sub-images via a sliding window and splice the results, we introduce a splice-then-segment paradigm that incorporates Segment-Anything Model (SAM) to tackle the resolution issue since SAM excels at extracting fine-grained semantic correlations from high-resolution images. Specifically, we introduce Trident, a training-free framework that first splices features extracted by CLIP and DINO from sub-images, then leverages SAM's encoder to create a correlation matrix for global aggregation, enabling a broadened receptive field for effective segmentation. Besides, we propose a refinement strategy for CLIP's coarse segmentation outputs by transforming them into prompts for SAM, further enhancing the segmentation performance. Trident achieves a significant improvement in the mIoU across eight benchmarks compared with the current SOTA, increasing from 44.4 to 48.6.Code is available at https://github.com/YuHengsss/Trident.
VSSD: Vision Mamba with Non-Causal State Space Duality
Aug 04, 2024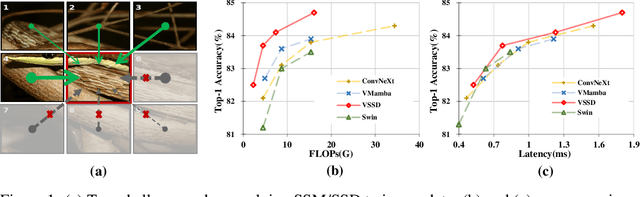
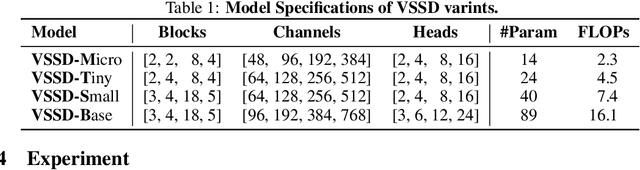

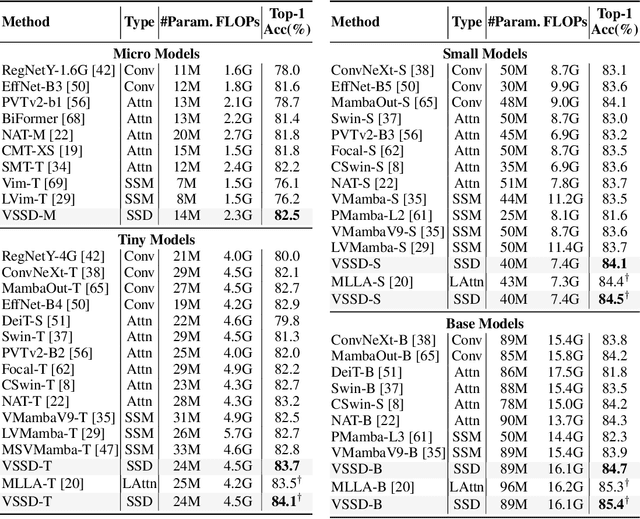
Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at \url{https://github.com/YuHengsss/VSSD}.
Practical Video Object Detection via Feature Selection and Aggregation
Jul 29, 2024Compared with still image object detection, video object detection (VOD) needs to particularly concern the high across-frame variation in object appearance, and the diverse deterioration in some frames. In principle, the detection in a certain frame of a video can benefit from information in other frames. Thus, how to effectively aggregate features across different frames is key to the target problem. Most of contemporary aggregation methods are tailored for two-stage detectors, suffering from high computational costs due to the dual-stage nature. On the other hand, although one-stage detectors have made continuous progress in handling static images, their applicability to VOD lacks sufficient exploration. To tackle the above issues, this study invents a very simple yet potent strategy of feature selection and aggregation, gaining significant accuracy at marginal computational expense. Concretely, for cutting the massive computation and memory consumption from the dense prediction characteristic of one-stage object detectors, we first condense candidate features from dense prediction maps. Then, the relationship between a target frame and its reference frames is evaluated to guide the aggregation. Comprehensive experiments and ablation studies are conducted to validate the efficacy of our design, and showcase its advantage over other cutting-edge VOD methods in both effectiveness and efficiency. Notably, our model reaches \emph{a new record performance, i.e., 92.9\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 3090 GPU}, making it a compelling option for large-scale or real-time applications. The implementation is simple, and accessible at \url{https://github.com/YuHengsss/YOLOV}.
VSSD: Vision Mamba with Non-Casual State Space Duality
Jul 26, 2024Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at \url{https://github.com/YuHengsss/VSSD}.
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
May 23, 2024Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at \url{https://github.com/YuHengsss/MSVMamba}.
TSTTC: A Large-Scale Dataset for Time-to-Contact Estimation in Driving Scenarios
Sep 06, 2023Time-to-Contact (TTC) estimation is a critical task for assessing collision risk and is widely used in various driver assistance and autonomous driving systems. The past few decades have witnessed development of related theories and algorithms. The prevalent learning-based methods call for a large-scale TTC dataset in real-world scenarios. In this work, we present a large-scale object oriented TTC dataset in the driving scene for promoting the TTC estimation by a monocular camera. To collect valuable samples and make data with different TTC values relatively balanced, we go through thousands of hours of driving data and select over 200K sequences with a preset data distribution. To augment the quantity of small TTC cases, we also generate clips using the latest Neural rendering methods. Additionally, we provide several simple yet effective TTC estimation baselines and evaluate them extensively on the proposed dataset to demonstrate their effectiveness. The proposed dataset is publicly available at https://open-dataset.tusen.ai/TSTTC.
Knowledge Prompting for Few-shot Action Recognition
Nov 22, 2022



Few-shot action recognition in videos is challenging for its lack of supervision and difficulty in generalizing to unseen actions. To address this task, we propose a simple yet effective method, called knowledge prompting, which leverages commonsense knowledge of actions from external resources to prompt a powerful pre-trained vision-language model for few-shot classification. We first collect large-scale language descriptions of actions, defined as text proposals, to build an action knowledge base. The collection of text proposals is done by filling in handcraft sentence templates with external action-related corpus or by extracting action-related phrases from captions of Web instruction videos.Then we feed these text proposals into the pre-trained vision-language model along with video frames to generate matching scores of the proposals to each frame, and the scores can be treated as action semantics with strong generalization. Finally, we design a lightweight temporal modeling network to capture the temporal evolution of action semantics for classification.Extensive experiments on six benchmark datasets demonstrate that our method generally achieves the state-of-the-art performance while reducing the training overhead to 0.001 of existing methods.