 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSSD: Vision Mamba with Non-Casual State Space Duality
Paper and Code
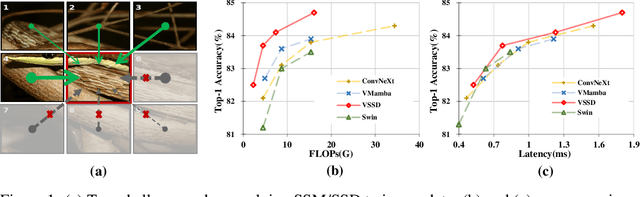
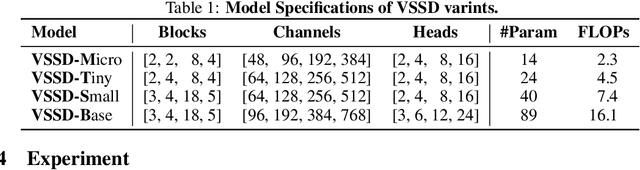

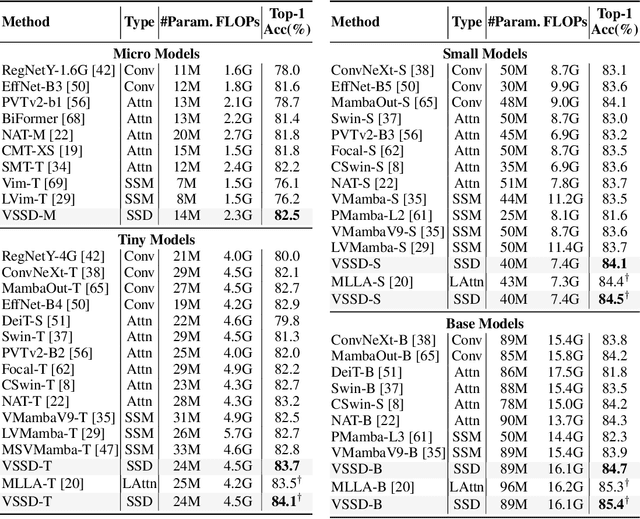
Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at \url{https://github.com/YuHengsss/VSSD}.