 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Exploring Structured Semantic Priors Underlying Diffusion Score for Test-time Adaptation
Jan 01, 2025
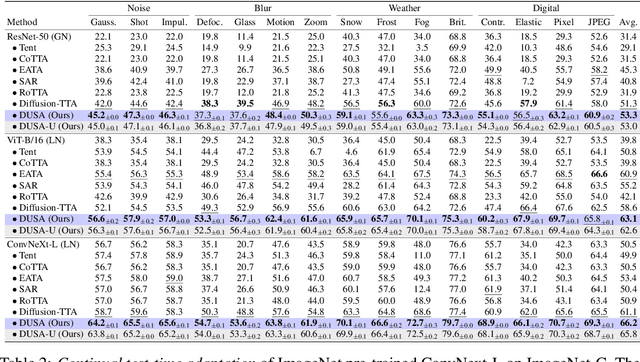


Capitalizing on the complementary advantages of generative and discriminative models has always been a compelling vision in machine learning, backed by a growing body of research. This work discloses the hidden semantic structure within score-based generative models, unveiling their potential as effective discriminative priors. Inspired by our theoretical findings, we propose DUSA to exploit the structured semantic priors underlying diffusion score to facilitate the test-time adaptation of image classifiers or dense predictors. Notably, DUSA extracts knowledge from a single timestep of denoising diffusion, lifting the curse of Monte Carlo-based likelihood estimation over timesteps. We demonstrate the efficacy of our DUSA in adapting a wide variety of competitive pre-trained discriminative models on diverse test-time scenarios. Additionally, a thorough ablation study is conducted to dissect the pivotal elements in DUSA. Code is publicly available at https://github.com/BIT-DA/DUSA.
ShadowHack: Hacking Shadows via Luminance-Color Divide and Conquer
Dec 03, 2024
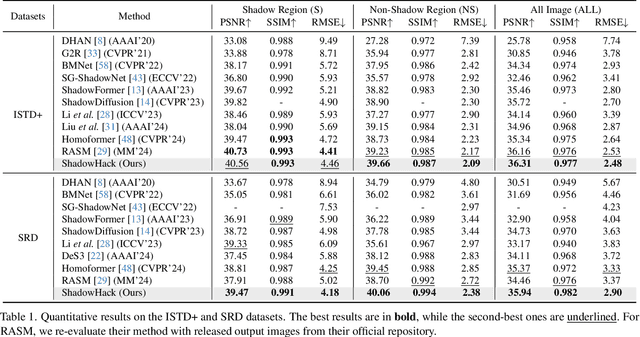
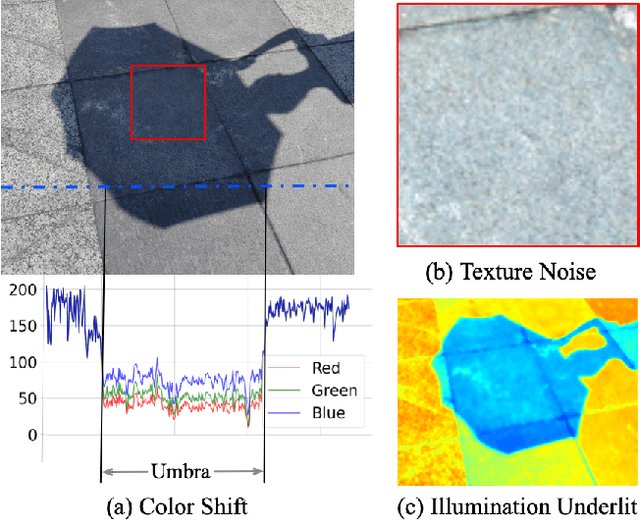
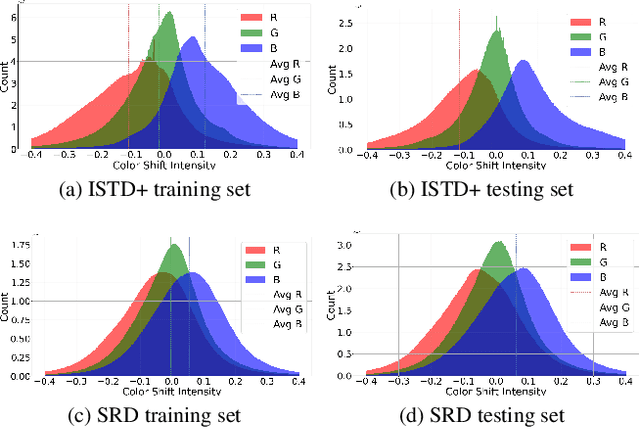
Shadows introduce challenges such as reduced brightness, texture deterioration, and color distortion in images, complicating a holistic solution. This study presents \textbf{ShadowHack}, a divide-and-conquer strategy that tackles these complexities by decomposing the original task into luminance recovery and color remedy. To brighten shadow regions and repair the corrupted textures in the luminance space, we customize LRNet, a U-shaped network with a rectified outreach attention module, to enhance information interaction and recalibrate contaminated attention maps. With luminance recovered, CRNet then leverages cross-attention mechanisms to revive vibrant colors, producing visually compelling results. Extensive experiments on multiple datasets are conducted to demonstrate the superiority of ShadowHack over existing state-of-the-art solutions both quantitatively and qualitatively, highlighting the effectiveness of our design. Our code will be made publicly available at https://github.com/lime-j/ShadowHack
Regional Attention for Shadow Removal
Nov 21, 2024



Shadow, as a natural consequence of light interacting with objects, plays a crucial role in shaping the aesthetics of an image, which however also impairs the content visibility and overall visual quality. Recent shadow removal approaches employ the mechanism of attention, due to its effectiveness, as a key component. However, they often suffer from two issues including large model size and high computational complexity for practical use. To address these shortcomings, this work devises a lightweight yet accurate shadow removal framework. First, we analyze the characteristics of the shadow removal task to seek the key information required for reconstructing shadow regions and designing a novel regional attention mechanism to effectively capture such information. Then, we customize a Regional Attention Shadow Removal Model (RASM, in short), which leverages non-shadow areas to assist in restoring shadow ones. Unlike existing attention-based models, our regional attention strategy allows each shadow region to interact more rationally with its surrounding non-shadow areas, for seeking the regional contextual correlation between shadow and non-shadow areas. Extensive experiments are conducted to demonstrate that our proposed method delivers superior performance over other state-of-the-art models in terms of accuracy and efficiency, making it appealing for practical applications.
LIME-Eval: Rethinking Low-light Image Enhancement Evaluation via Object Detection
Oct 11, 2024



Due to the nature of enhancement--the absence of paired ground-truth information, high-level vision tasks have been recently employed to evaluate the performance of low-light image enhancement. A widely-used manner is to see how accurately an object detector trained on enhanced low-light images by different candidates can perform with respect to annotated semantic labels. In this paper, we first demonstrate that the mentioned approach is generally prone to overfitting, and thus diminishes its measurement reliability. In search of a proper evaluation metric, we propose LIME-Bench, the first online benchmark platform designed to collect human preferences for low-light enhancement, providing a valuable dataset for validating the correlation between human perception and automated evaluation metrics. We then customize LIME-Eval, a novel evaluation framework that utilizes detectors pre-trained on standard-lighting datasets without object annotations, to judge the quality of enhanced images. By adopting an energy-based strategy to assess the accuracy of output confidence maps, our LIME-Eval can simultaneously bypass biases associated with retraining detectors and circumvent the reliance on annotations for dim images. Comprehensive experiments are provided to reveal the effectiveness of our LIME-Eval. Our benchmark platform (https://huggingface.co/spaces/lime-j/eval) and code (https://github.com/lime-j/lime-eval) are available online.
Reversible Decoupling Network for Single Image Reflection Removal
Oct 10, 2024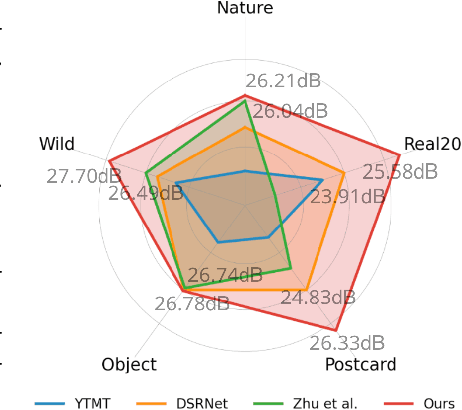
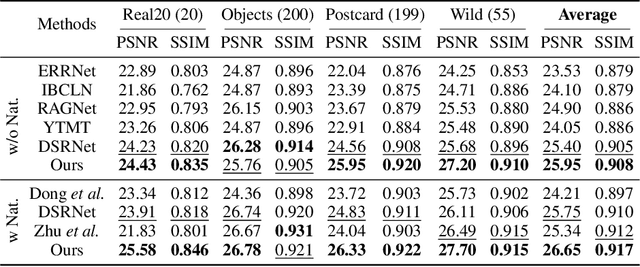
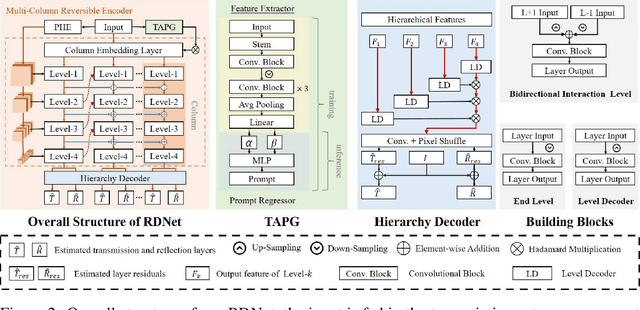

Recent deep-learning-based approaches to single-image reflection removal have shown promising advances, primarily for two reasons: 1) the utilization of recognition-pretrained features as inputs, and 2) the design of dual-stream interaction networks. However, according to the Information Bottleneck principle, high-level semantic clues tend to be compressed or discarded during layer-by-layer propagation. Additionally, interactions in dual-stream networks follow a fixed pattern across different layers, limiting overall performance. To address these limitations, we propose a novel architecture called Reversible Decoupling Network (RDNet), which employs a reversible encoder to secure valuable information while flexibly decoupling transmission- and reflection-relevant features during the forward pass. Furthermore, we customize a transmission-rate-aware prompt generator to dynamically calibrate features, further boosting performance. Extensive experiments demonstrate the superiority of RDNet over existing SOTA methods on five widely-adopted benchmark datasets. Our code will be made publicly available.
VSSD: Vision Mamba with Non-Causal State Space Duality
Aug 04, 2024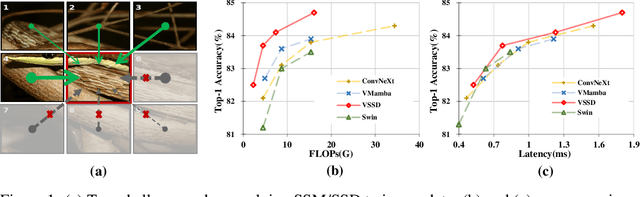
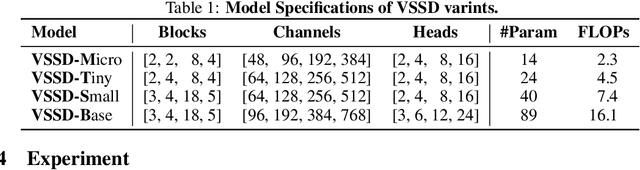

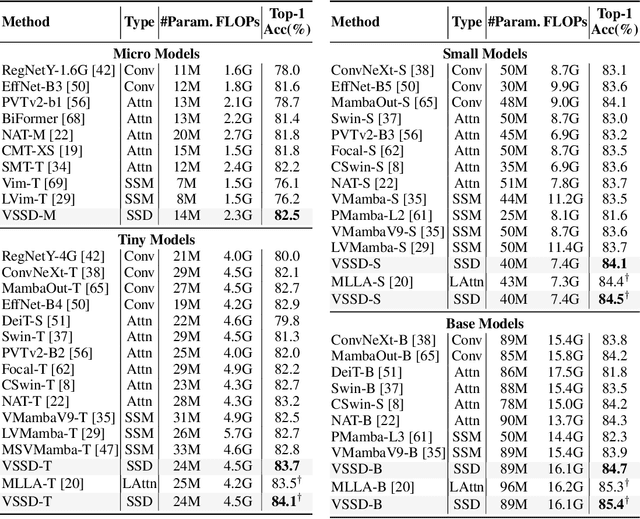
Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at \url{https://github.com/YuHengsss/VSSD}.
VSSD: Vision Mamba with Non-Casual State Space Duality
Jul 26, 2024Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at \url{https://github.com/YuHengsss/VSSD}.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024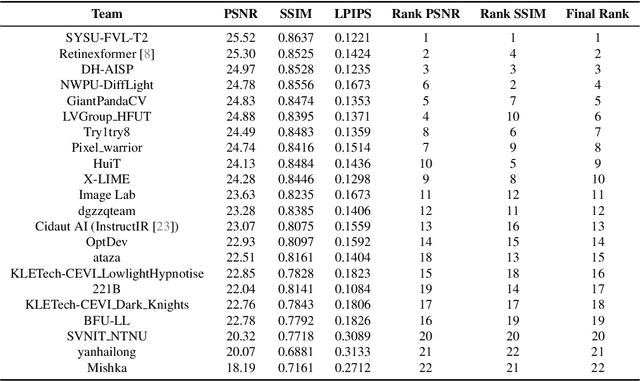


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Adaptive Texture Filtering for Single-Domain Generalized Segmentation
Mar 06, 2023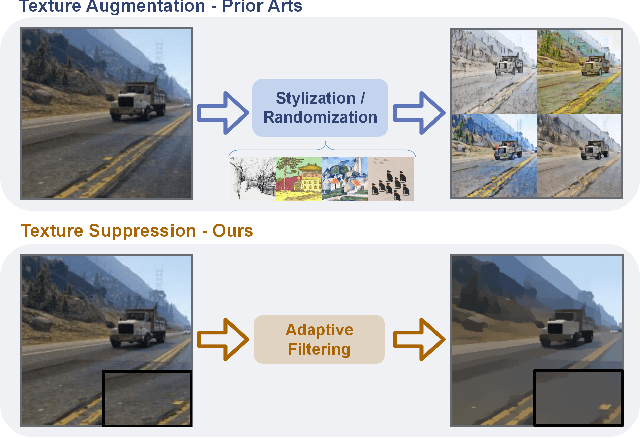
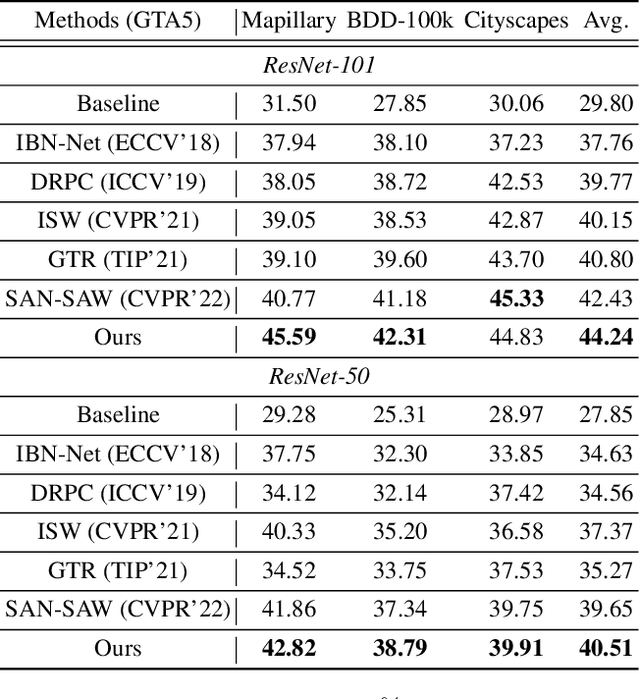
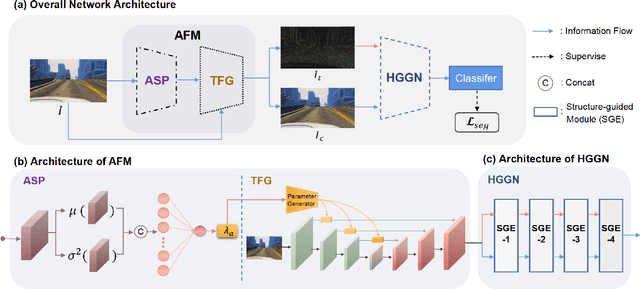
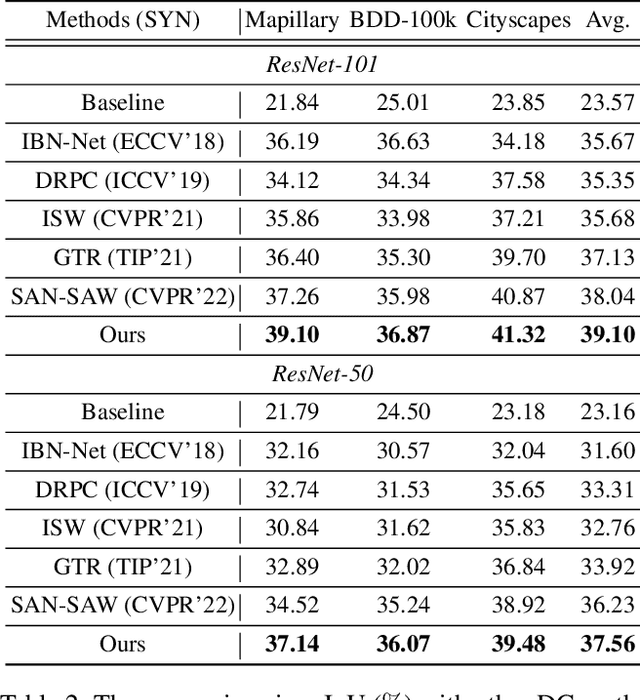
Domain generalization in semantic segmentation aims to alleviate the performance degradation on unseen domains through learning domain-invariant features. Existing methods diversify images in the source domain by adding complex or even abnormal textures to reduce the sensitivity to domain specific features. However, these approaches depend heavily on the richness of the texture bank, and training them can be time-consuming. In contrast to importing textures arbitrarily or augmenting styles randomly, we focus on the single source domain itself to achieve generalization. In this paper, we present a novel adaptive texture filtering mechanism to suppress the influence of texture without using augmentation, thus eliminating the interference of domain-specific features. Further, we design a hierarchical guidance generalization network equipped with structure-guided enhancement modules, which purpose is to learn the domain-invariant generalized knowledge. Extensive experiments together with ablation studies on widely-used datasets are conducted to verify the effectiveness of the proposed model, and reveal its superiority over other state-of-the-art alternatives.