 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyPhoto: Multi-Person Identity Preserving Image Generation with ID Adaptive Modulation on Location Canvas
Mar 16, 2026Multi-person identity-preserving generation requires binding multiple reference faces to specified locations under a text prompt. Strong identity/layout conditions often trigger copy-paste shortcuts and weaken prompt-driven controllability. We present AnyPhoto, a diffusion-transformer finetuning framework with (i) a RoPE-aligned location canvas plus location-aligned token pruning for spatial grounding, (ii) AdaLN-style identity-adaptive modulation from face-recognition embeddings for persistent identity injection, and (iii) identity-isolated attention to prevent cross-identity interference. Training combines conditional flow matching with an embedding-space face similarity loss, together with reference-face replacement and location-canvas degradations to discourage shortcuts. On MultiID-Bench, AnyPhoto improves identity similarity while reducing copy-paste tendency, with gains increasing as the number of identities grows. AnyPhoto also supports prompt-driven stylization with accurate placement, showing great potential application value.
Exploring Structured Semantic Priors Underlying Diffusion Score for Test-time Adaptation
Jan 01, 2025
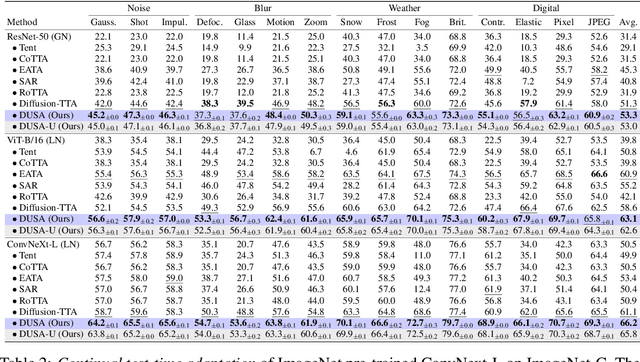


Capitalizing on the complementary advantages of generative and discriminative models has always been a compelling vision in machine learning, backed by a growing body of research. This work discloses the hidden semantic structure within score-based generative models, unveiling their potential as effective discriminative priors. Inspired by our theoretical findings, we propose DUSA to exploit the structured semantic priors underlying diffusion score to facilitate the test-time adaptation of image classifiers or dense predictors. Notably, DUSA extracts knowledge from a single timestep of denoising diffusion, lifting the curse of Monte Carlo-based likelihood estimation over timesteps. We demonstrate the efficacy of our DUSA in adapting a wide variety of competitive pre-trained discriminative models on diverse test-time scenarios. Additionally, a thorough ablation study is conducted to dissect the pivotal elements in DUSA. Code is publicly available at https://github.com/BIT-DA/DUSA.
Few Clicks Suffice: Active Test-Time Adaptation for Semantic Segmentation
Dec 04, 2023



Test-time adaptation (TTA) adapts the pre-trained models during inference using unlabeled test data and has received a lot of research attention due to its potential practical value. Unfortunately, without any label supervision, existing TTA methods rely heavily on heuristic or empirical studies. Where to update the model always falls into suboptimal or brings more computational resource consumption. Meanwhile, there is still a significant performance gap between the TTA approaches and their supervised counterparts. Motivated by active learning, in this work, we propose the active test-time adaptation for semantic segmentation setup. Specifically, we introduce the human-in-the-loop pattern during the testing phase, which queries very few labels to facilitate predictions and model updates in an online manner. To do so, we propose a simple but effective ATASeg framework, which consists of two parts, i.e., model adapter and label annotator. Extensive experiments demonstrate that ATASeg bridges the performance gap between TTA methods and their supervised counterparts with only extremely few annotations, even one click for labeling surpasses known SOTA TTA methods by 2.6% average mIoU on ACDC benchmark. Empirical results imply that progress in either the model adapter or the label annotator will bring improvements to the ATASeg framework, giving it large research and reality potential.
Generalized Robust Test-Time Adaptation in Continuous Dynamic Scenarios
Oct 07, 2023



Test-time adaptation (TTA) adapts the pre-trained models to test distributions during the inference phase exclusively employing unlabeled test data streams, which holds great value for the deployment of models in real-world applications. Numerous studies have achieved promising performance on simplistic test streams, characterized by independently and uniformly sampled test data originating from a fixed target data distribution. However, these methods frequently prove ineffective in practical scenarios, where both continual covariate shift and continual label shift occur simultaneously, i.e., data and label distributions change concurrently and continually over time. In this study, a more challenging Practical Test-Time Adaptation (PTTA) setup is introduced, which takes into account the concurrent presence of continual covariate shift and continual label shift, and we propose a Generalized Robust Test-Time Adaptation (GRoTTA) method to effectively address the difficult problem. We start by steadily adapting the model through Robust Parameter Adaptation to make balanced predictions for test samples. To be specific, firstly, the effects of continual label shift are eliminated by enforcing the model to learn from a uniform label distribution and introducing recalibration of batch normalization to ensure stability. Secondly, the continual covariate shift is alleviated by employing a source knowledge regularization with the teacher-student model to update parameters. Considering the potential information in the test stream, we further refine the balanced predictions by Bias-Guided Output Adaptation, which exploits latent structure in the feature space and is adaptive to the imbalanced label distribution. Extensive experiments demonstrate GRoTTA outperforms the existing competitors by a large margin under PTTA setting, rendering it highly conducive for adoption in real-world applications.
Robust Test-Time Adaptation in Dynamic Scenarios
Mar 24, 2023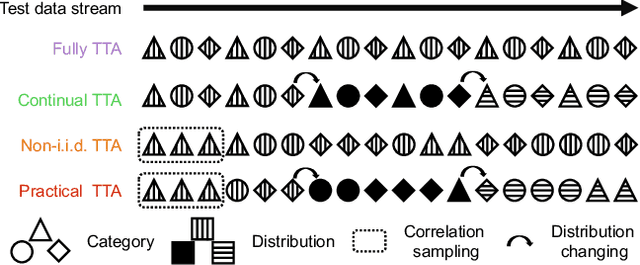

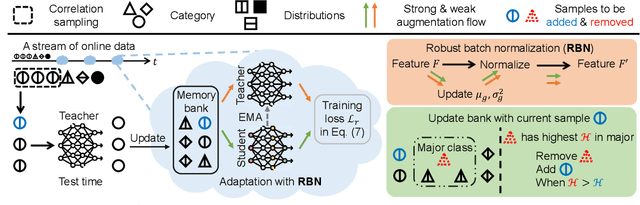
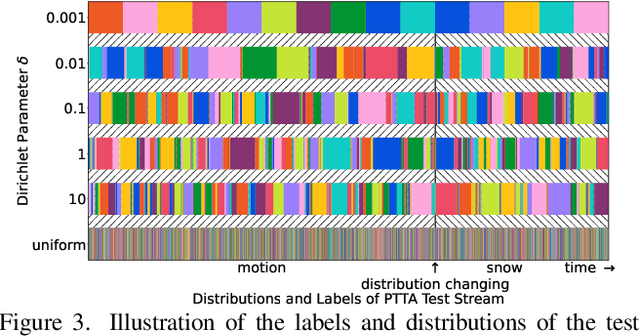
Test-time adaptation (TTA) intends to adapt the pretrained model to test distributions with only unlabeled test data streams. Most of the previous TTA methods have achieved great success on simple test data streams such as independently sampled data from single or multiple distributions. However, these attempts may fail in dynamic scenarios of real-world applications like autonomous driving, where the environments gradually change and the test data is sampled correlatively over time. In this work, we explore such practical test data streams to deploy the model on the fly, namely practical test-time adaptation (PTTA). To do so, we elaborate a Robust Test-Time Adaptation (RoTTA) method against the complex data stream in PTTA. More specifically, we present a robust batch normalization scheme to estimate the normalization statistics. Meanwhile, a memory bank is utilized to sample category-balanced data with consideration of timeliness and uncertainty. Further, to stabilize the training procedure, we develop a time-aware reweighting strategy with a teacher-student model. Extensive experiments prove that RoTTA enables continual testtime adaptation on the correlatively sampled data streams. Our method is easy to implement, making it a good choice for rapid deployment. The code is publicly available at https://github.com/BIT-DA/RoTTA
Active Learning for Domain Adaptation: An Energy-based Approach
Dec 08, 2021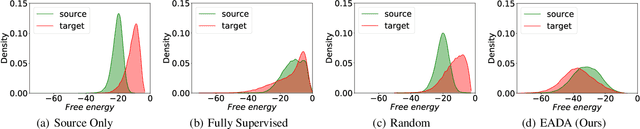
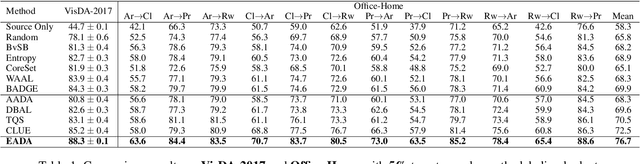
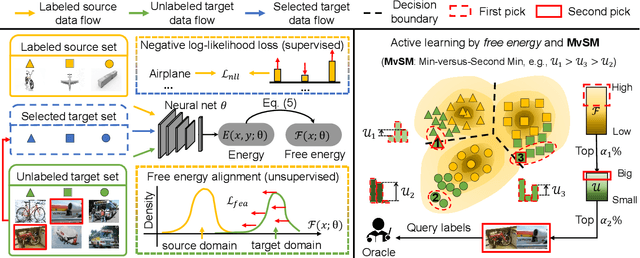
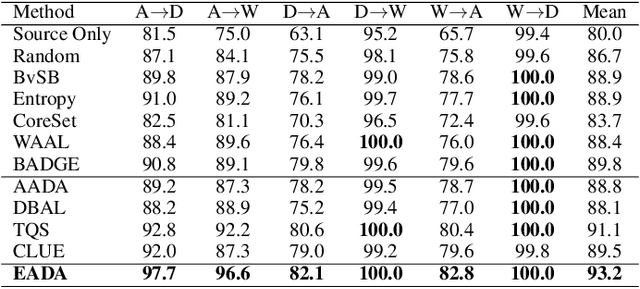
Unsupervised domain adaptation has recently emerged as an effective paradigm for generalizing deep neural networks to new target domains. However, there is still enormous potential to be tapped to reach the fully supervised performance. In this paper, we present a novel active learning strategy to assist knowledge transfer in the target domain, dubbed active domain adaptation. We start from an observation that energy-based models exhibit free energy biases when training (source) and test (target) data come from different distributions. Inspired by this inherent mechanism, we empirically reveal that a simple yet efficient energy-based sampling strategy sheds light on selecting the most valuable target samples than existing approaches requiring particular architectures or computation of the distances. Our algorithm, Energy-based Active Domain Adaptation (EADA), queries groups of targe data that incorporate both domain characteristic and instance uncertainty into every selection round. Meanwhile, by aligning the free energy of target data compact around the source domain via a regularization term, domain gap can be implicitly diminished. Through extensive experiments, we show that EADA surpasses state-of-the-art methods on well-known challenging benchmarks with substantial improvements, making it a useful option in the open world. Code is available at https://github.com/BIT-DA/EADA.
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
Nov 25, 2021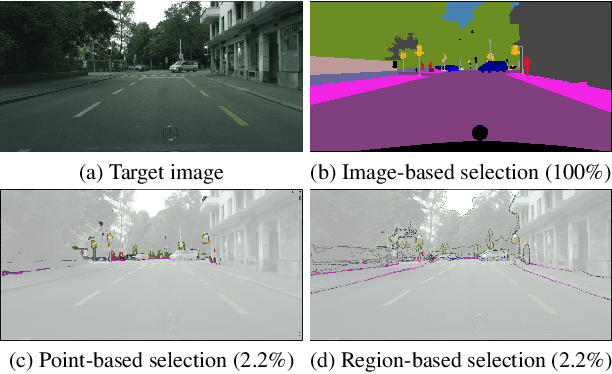
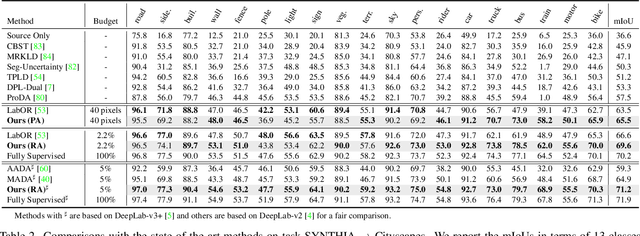
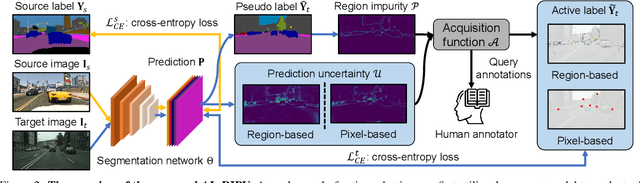
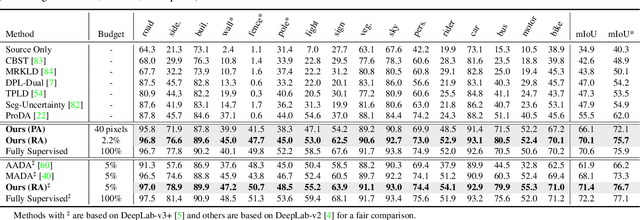
Self-training has greatly facilitated domain adaptive semantic segmentation, which iteratively generates pseudo labels on the target domain and retrains the network. However, since the realistic segmentation datasets are highly imbalanced, target pseudo labels are typically biased to the majority classes and basically noisy, leading to an error-prone and sub-optimal model. To address this issue, we propose a region-based active learning approach for semantic segmentation under a domain shift, aiming to automatically query a small partition of image regions to be labeled while maximizing segmentation performance. Our algorithm, Active Learning via Region Impurity and Prediction Uncertainty (AL-RIPU), introduces a novel acquisition strategy characterizing the spatial adjacency of image regions along with the prediction confidence. We show that the proposed region-based selection strategy makes more efficient use of a limited budget than image-based or point-based counterparts. Meanwhile, we enforce local prediction consistency between a pixel and its nearest neighbor on a source image. Further, we develop a negative learning loss to enhance the discriminative representation learning on the target domain. Extensive experiments demonstrate that our method only requires very few annotations to almost reach the supervised performance and substantially outperforms state-of-the-art methods.