 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Details to Global Context: Advancing Vision-Language Models with Attention-Based Selection
May 19, 2025Pretrained vision-language models (VLMs), e.g., CLIP, demonstrate impressive zero-shot capabilities on downstream tasks. Prior research highlights the crucial role of visual augmentation techniques, like random cropping, in alignment with fine-grained class descriptions generated by large language models (LLMs), significantly enhancing zero-shot performance by incorporating multi-view information. However, the inherent randomness of these augmentations can inevitably introduce background artifacts and cause models to overly focus on local details, compromising global semantic understanding. To address these issues, we propose an \textbf{A}ttention-\textbf{B}ased \textbf{S}election (\textbf{ABS}) method from local details to global context, which applies attention-guided cropping in both raw images and feature space, supplement global semantic information through strategic feature selection. Additionally, we introduce a soft matching technique to effectively filter LLM descriptions for better alignment. \textbf{ABS} achieves state-of-the-art performance on out-of-distribution generalization and zero-shot classification tasks. Notably, \textbf{ABS} is training-free and even rivals few-shot and test-time adaptation methods. Our code is available at \href{https://github.com/BIT-DA/ABS}{\textcolor{darkgreen}{https://github.com/BIT-DA/ABS}}.
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Jun 13, 2024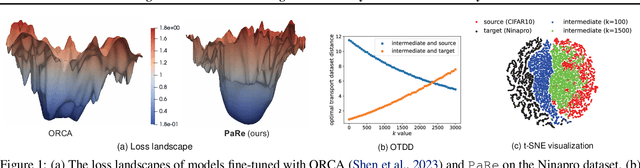
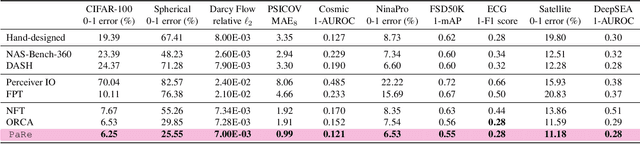
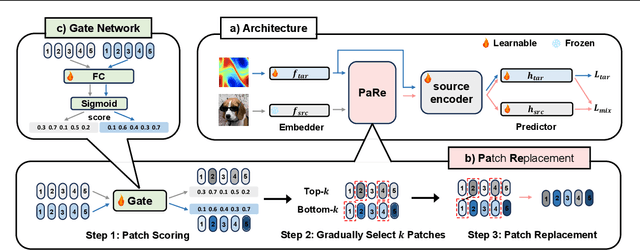

Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Few Clicks Suffice: Active Test-Time Adaptation for Semantic Segmentation
Dec 04, 2023



Test-time adaptation (TTA) adapts the pre-trained models during inference using unlabeled test data and has received a lot of research attention due to its potential practical value. Unfortunately, without any label supervision, existing TTA methods rely heavily on heuristic or empirical studies. Where to update the model always falls into suboptimal or brings more computational resource consumption. Meanwhile, there is still a significant performance gap between the TTA approaches and their supervised counterparts. Motivated by active learning, in this work, we propose the active test-time adaptation for semantic segmentation setup. Specifically, we introduce the human-in-the-loop pattern during the testing phase, which queries very few labels to facilitate predictions and model updates in an online manner. To do so, we propose a simple but effective ATASeg framework, which consists of two parts, i.e., model adapter and label annotator. Extensive experiments demonstrate that ATASeg bridges the performance gap between TTA methods and their supervised counterparts with only extremely few annotations, even one click for labeling surpasses known SOTA TTA methods by 2.6% average mIoU on ACDC benchmark. Empirical results imply that progress in either the model adapter or the label annotator will bring improvements to the ATASeg framework, giving it large research and reality potential.
Annotator: A Generic Active Learning Baseline for LiDAR Semantic Segmentation
Oct 31, 2023



Active learning, a label-efficient paradigm, empowers models to interactively query an oracle for labeling new data. In the realm of LiDAR semantic segmentation, the challenges stem from the sheer volume of point clouds, rendering annotation labor-intensive and cost-prohibitive. This paper presents Annotator, a general and efficient active learning baseline, in which a voxel-centric online selection strategy is tailored to efficiently probe and annotate the salient and exemplar voxel girds within each LiDAR scan, even under distribution shift. Concretely, we first execute an in-depth analysis of several common selection strategies such as Random, Entropy, Margin, and then develop voxel confusion degree (VCD) to exploit the local topology relations and structures of point clouds. Annotator excels in diverse settings, with a particular focus on active learning (AL), active source-free domain adaptation (ASFDA), and active domain adaptation (ADA). It consistently delivers exceptional performance across LiDAR semantic segmentation benchmarks, spanning both simulation-to-real and real-to-real scenarios. Surprisingly, Annotator exhibits remarkable efficiency, requiring significantly fewer annotations, e.g., just labeling five voxels per scan in the SynLiDAR-to-SemanticKITTI task. This results in impressive performance, achieving 87.8% fully-supervised performance under AL, 88.5% under ASFDA, and 94.4% under ADA. We envision that Annotator will offer a simple, general, and efficient solution for label-efficient 3D applications. Project page: https://binhuixie.github.io/annotator-web
Generalized Robust Test-Time Adaptation in Continuous Dynamic Scenarios
Oct 07, 2023



Test-time adaptation (TTA) adapts the pre-trained models to test distributions during the inference phase exclusively employing unlabeled test data streams, which holds great value for the deployment of models in real-world applications. Numerous studies have achieved promising performance on simplistic test streams, characterized by independently and uniformly sampled test data originating from a fixed target data distribution. However, these methods frequently prove ineffective in practical scenarios, where both continual covariate shift and continual label shift occur simultaneously, i.e., data and label distributions change concurrently and continually over time. In this study, a more challenging Practical Test-Time Adaptation (PTTA) setup is introduced, which takes into account the concurrent presence of continual covariate shift and continual label shift, and we propose a Generalized Robust Test-Time Adaptation (GRoTTA) method to effectively address the difficult problem. We start by steadily adapting the model through Robust Parameter Adaptation to make balanced predictions for test samples. To be specific, firstly, the effects of continual label shift are eliminated by enforcing the model to learn from a uniform label distribution and introducing recalibration of batch normalization to ensure stability. Secondly, the continual covariate shift is alleviated by employing a source knowledge regularization with the teacher-student model to update parameters. Considering the potential information in the test stream, we further refine the balanced predictions by Bias-Guided Output Adaptation, which exploits latent structure in the feature space and is adaptive to the imbalanced label distribution. Extensive experiments demonstrate GRoTTA outperforms the existing competitors by a large margin under PTTA setting, rendering it highly conducive for adoption in real-world applications.
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023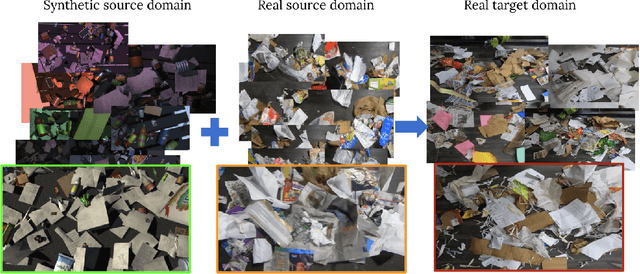
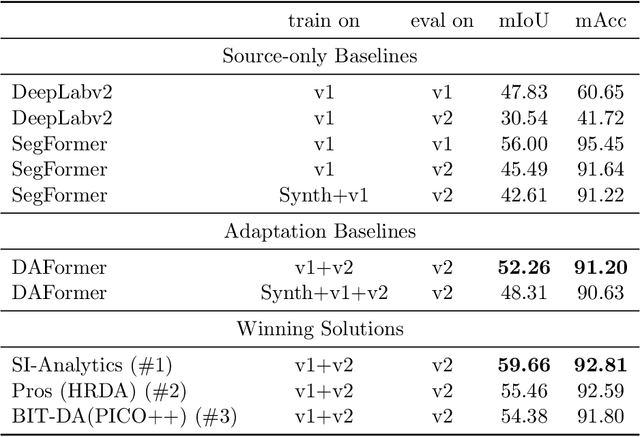

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
Robust Test-Time Adaptation in Dynamic Scenarios
Mar 24, 2023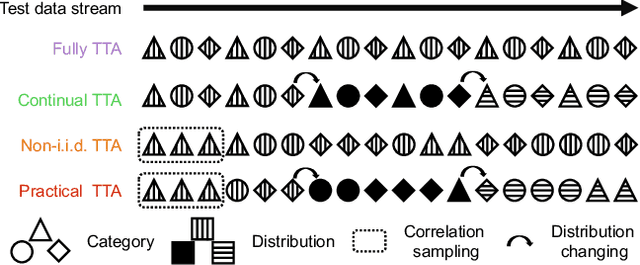

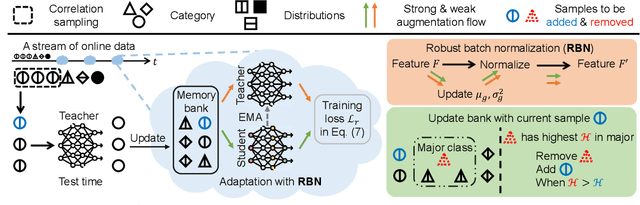
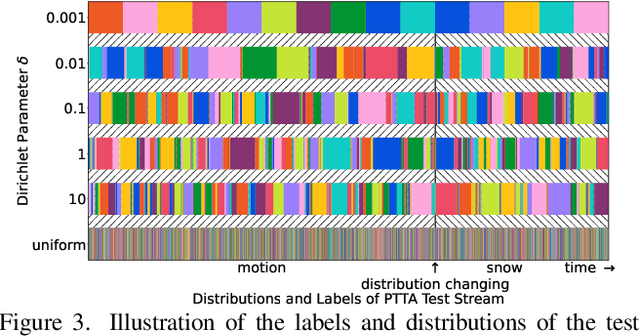
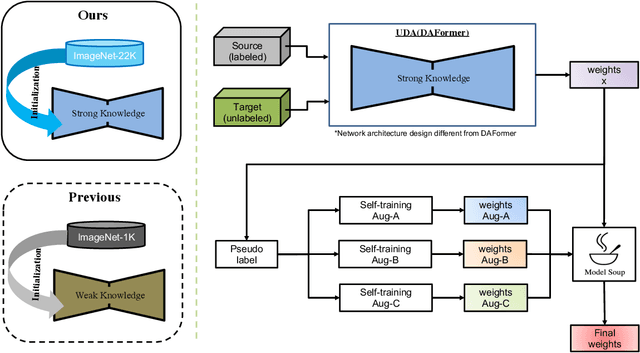
Test-time adaptation (TTA) intends to adapt the pretrained model to test distributions with only unlabeled test data streams. Most of the previous TTA methods have achieved great success on simple test data streams such as independently sampled data from single or multiple distributions. However, these attempts may fail in dynamic scenarios of real-world applications like autonomous driving, where the environments gradually change and the test data is sampled correlatively over time. In this work, we explore such practical test data streams to deploy the model on the fly, namely practical test-time adaptation (PTTA). To do so, we elaborate a Robust Test-Time Adaptation (RoTTA) method against the complex data stream in PTTA. More specifically, we present a robust batch normalization scheme to estimate the normalization statistics. Meanwhile, a memory bank is utilized to sample category-balanced data with consideration of timeliness and uncertainty. Further, to stabilize the training procedure, we develop a time-aware reweighting strategy with a teacher-student model. Extensive experiments prove that RoTTA enables continual testtime adaptation on the correlatively sampled data streams. Our method is easy to implement, making it a good choice for rapid deployment. The code is publicly available at https://github.com/BIT-DA/RoTTA
VBLC: Visibility Boosting and Logit-Constraint Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Nov 22, 2022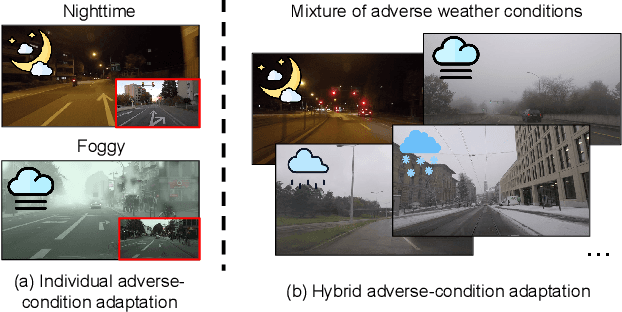
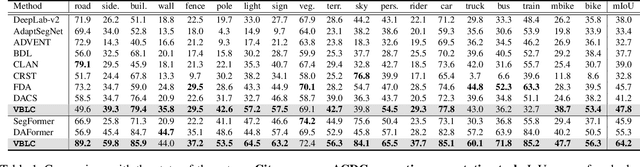
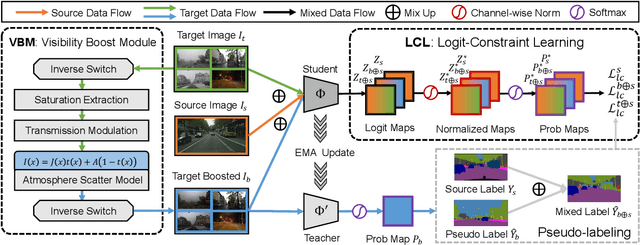

Generalizing models trained on normal visual conditions to target domains under adverse conditions is demanding in the practical systems. One prevalent solution is to bridge the domain gap between clear- and adverse-condition images to make satisfactory prediction on the target. However, previous methods often reckon on additional reference images of the same scenes taken from normal conditions, which are quite tough to collect in reality. Furthermore, most of them mainly focus on individual adverse condition such as nighttime or foggy, weakening the model versatility when encountering other adverse weathers. To overcome the above limitations, we propose a novel framework, Visibility Boosting and Logit-Constraint learning (VBLC), tailored for superior normal-to-adverse adaptation. VBLC explores the potential of getting rid of reference images and resolving the mixture of adverse conditions simultaneously. In detail, we first propose the visibility boost module to dynamically improve target images via certain priors in the image level. Then, we figure out the overconfident drawback in the conventional cross-entropy loss for self-training method and devise the logit-constraint learning, which enforces a constraint on logit outputs during training to mitigate this pain point. To the best of our knowledge, this is a new perspective for tackling such a challenging task. Extensive experiments on two normal-to-adverse domain adaptation benchmarks, i.e., Cityscapes -> ACDC and Cityscapes -> FoggyCityscapes + RainCityscapes, verify the effectiveness of VBLC, where it establishes the new state of the art. Code is available at https://github.com/BIT-DA/VBLC.
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
Nov 14, 2022



We launch EVA, a vision-centric foundation model to explore the limits of visual representation at scale using only publicly accessible data. EVA is a vanilla ViT pre-trained to reconstruct the masked out image-text aligned vision features conditioned on visible image patches. Via this pretext task, we can efficiently scale up EVA to one billion parameters, and sets new records on a broad range of representative vision downstream tasks, such as image recognition, video action recognition, object detection, instance segmentation and semantic segmentation without heavy supervised training. Moreover, we observe quantitative changes in scaling EVA result in qualitative changes in transfer learning performance that are not present in other models. For instance, EVA takes a great leap in the challenging large vocabulary instance segmentation task: our model achieves almost the same state-of-the-art performance on LVISv1.0 dataset with over a thousand categories and COCO dataset with only eighty categories. Beyond a pure vision encoder, EVA can also serve as a vision-centric, multi-modal pivot to connect images and text. We find initializing the vision tower of a giant CLIP from EVA can greatly stabilize the training and outperform the training from scratch counterpart with much fewer samples and less compute, providing a new direction for scaling up and accelerating the costly training of multi-modal foundation models. To facilitate future research, we will release all the code and models at \url{https://github.com/baaivision/EVA}.
Joint Semantic Transfer Network for IoT Intrusion Detection
Oct 28, 2022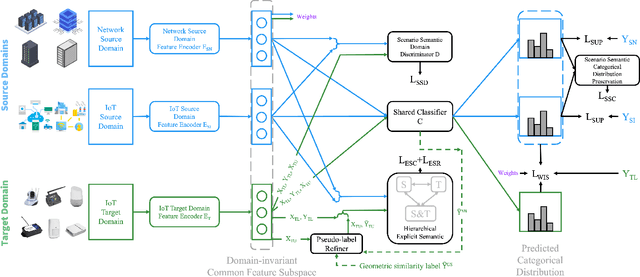

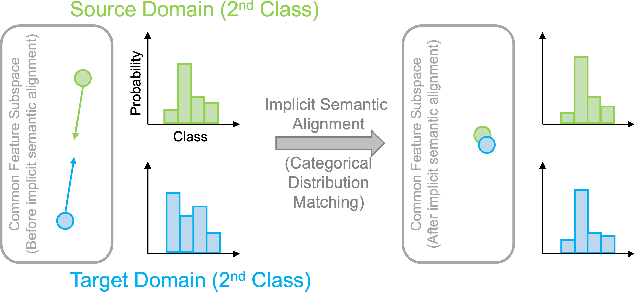
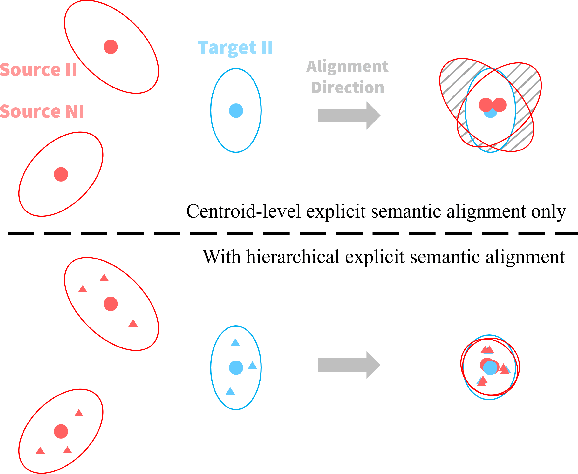
In this paper, we propose a Joint Semantic Transfer Network (JSTN) towards effective intrusion detection for large-scale scarcely labelled IoT domain. As a multi-source heterogeneous domain adaptation (MS-HDA) method, the JSTN integrates a knowledge rich network intrusion (NI) domain and another small-scale IoT intrusion (II) domain as source domains, and preserves intrinsic semantic properties to assist target II domain intrusion detection. The JSTN jointly transfers the following three semantics to learn a domain-invariant and discriminative feature representation. The scenario semantic endows source NI and II domain with characteristics from each other to ease the knowledge transfer process via a confused domain discriminator and categorical distribution knowledge preservation. It also reduces the source-target discrepancy to make the shared feature space domain-invariant. Meanwhile, the weighted implicit semantic transfer boosts discriminability via a fine-grained knowledge preservation, which transfers the source categorical distribution to the target domain. The source-target divergence guides the importance weighting during knowledge preservation to reflect the degree of knowledge learning. Additionally, the hierarchical explicit semantic alignment performs centroid-level and representative-level alignment with the help of a geometric similarity-aware pseudo-label refiner, which exploits the value of unlabelled target II domain and explicitly aligns feature representations from a global and local perspective in a concentrated manner. Comprehensive experiments on various tasks verify the superiority of the JSTN against state-of-the-art comparing methods, on average a 10.3% of accuracy boost is achieved. The statistical soundness of each constituting component and the computational efficiency are also verified.