 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Jun 13, 2024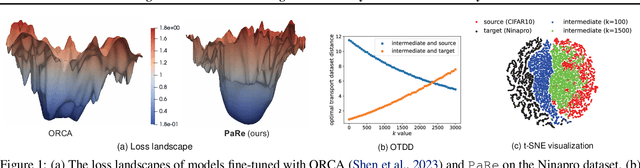
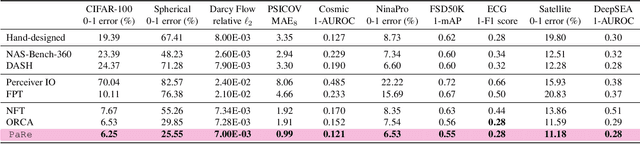
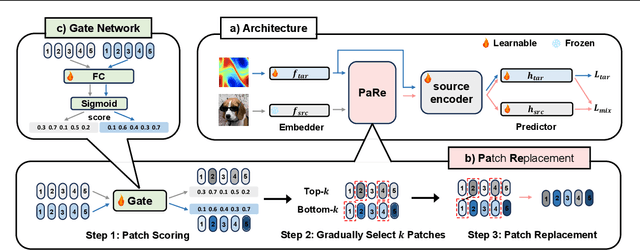

Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Unsupervised Multi-stream Highlight detection for the Game "Honor of Kings"
Oct 22, 2019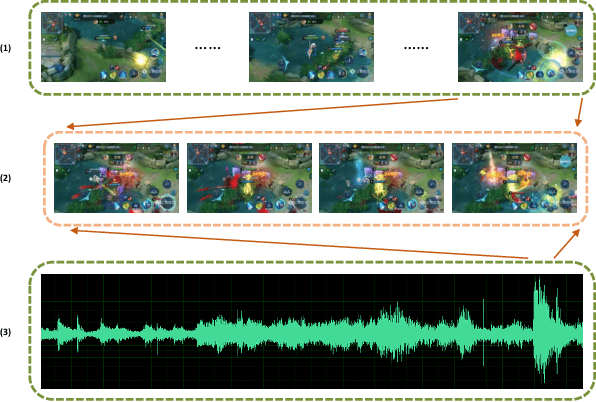


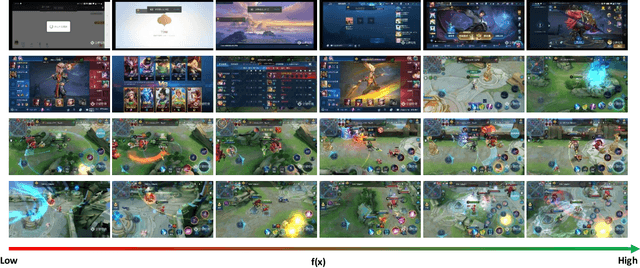
With the increasing popularity of E-sport live, Highlight Flashback has been a critical functionality of live platforms, which aggregates the overall exciting fighting scenes in a few seconds. In this paper, we introduce a novel training strategy without any additional annotation to automatically generate highlights for game video live. Considering that the existing manual edited clips contain more highlights than long game live videos, we perform pair-wise ranking constraints across clips from edited and long live videos. A multi-stream framework is also proposed to fuse spatial, temporal as well as audio features extracted from videos. To evaluate our method, we test on long game live videos with an average length of about 15 minutes. Extensive experimental results on videos demonstrate its satisfying performance on highlights generation and effectiveness by the fusion of three streams.
News Cover Assessment via Multi-task Learning
Jul 18, 2019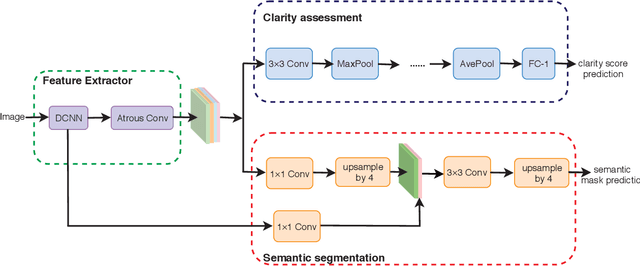



Online personalized news product needs a suitable cover for the article. The news cover demands to be with high image quality, and draw readers' attention at same time, which is extraordinary challenging due to the subjectivity of the task. In this paper, we assess the news cover from image clarity and object salience perspective. We propose an end-to-end multi-task learning network for image clarity assessment and semantic segmentation simultaneously, the results of which can be guided for news cover assessment. The proposed network is based on a modified DeepLabv3+ model. The network backbone is used for multiple scale spatial features exaction, followed by two branches for image clarity assessment and semantic segmentation, respectively. The experiment results show that the proposed model is able to capture important content in images and performs better than single-task learning baselines on our proposed game content based CIA dataset.