 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN-VLA: Modeling Abstraction of Intention and eNvironment for Vision-Language-Action Models
Feb 02, 2026Despite significant progress in Visual-Language-Action (VLA), in highly complex and dynamic environments that involve real-time unpredictable interactions (such as 3D open worlds and large-scale PvP games), existing approaches remain inefficient at extracting action-critical signals from redundant sensor streams. To tackle this, we introduce MAIN-VLA, a framework that explicitly Models the Abstraction of Intention and eNvironment to ground decision-making in deep semantic alignment rather than superficial pattern matching. Specifically, our Intention Abstraction (IA) extracts verbose linguistic instructions and their associated reasoning into compact, explicit semantic primitives, while the Environment Semantics Abstraction (ESA) projects overwhelming visual streams into a structured, topological affordance representation. Furthermore, aligning these two abstract modalities induces an emergent attention-concentration effect, enabling a parameter-free token-pruning strategy that filters out perceptual redundancy without degrading performance. Extensive experiments in open-world Minecraft and large-scale PvP environments (Game for Peace and Valorant) demonstrate that MAIN-VLA sets a new state-of-the-art, which achieves superior decision quality, stronger generalization, and cutting-edge inference efficiency.
Stable Heterogeneous Treatment Effect Estimation across Out-of-Distribution Populations
Jul 03, 2024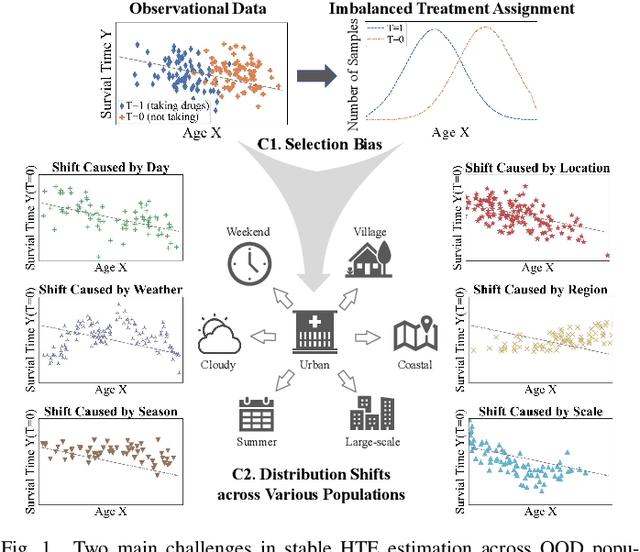



Heterogeneous treatment effect (HTE) estimation is vital for understanding the change of treatment effect across individuals or subgroups. Most existing HTE estimation methods focus on addressing selection bias induced by imbalanced distributions of confounders between treated and control units, but ignore distribution shifts across populations. Thereby, their applicability has been limited to the in-distribution (ID) population, which shares a similar distribution with the training dataset. In real-world applications, where population distributions are subject to continuous changes, there is an urgent need for stable HTE estimation across out-of-distribution (OOD) populations, which, however, remains an open problem. As pioneers in resolving this problem, we propose a novel Stable Balanced Representation Learning with Hierarchical-Attention Paradigm (SBRL-HAP) framework, which consists of 1) Balancing Regularizer for eliminating selection bias, 2) Independence Regularizer for addressing the distribution shift issue, 3) Hierarchical-Attention Paradigm for coordination between balance and independence. In this way, SBRL-HAP regresses counterfactual outcomes using ID data, while ensuring the resulting HTE estimation can be successfully generalized to out-of-distribution scenarios, thereby enhancing the model's applicability in real-world settings. Extensive experiments conducted on synthetic and real-world datasets demonstrate the effectiveness of our SBRL-HAP in achieving stable HTE estimation across OOD populations, with an average 10% reduction in the error metric PEHE and 11% decrease in the ATE bias, compared to the SOTA methods.
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Jun 13, 2024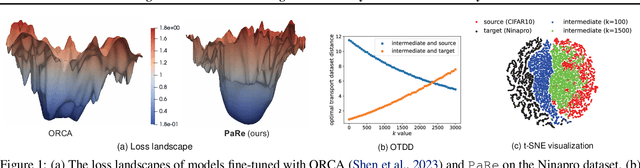
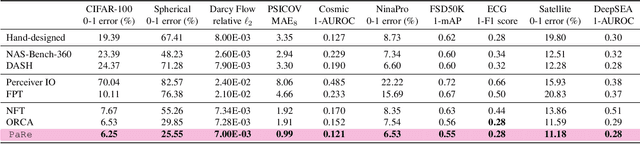
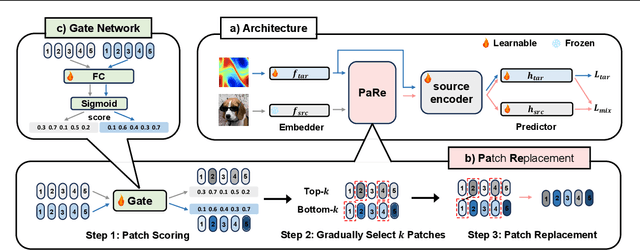

Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Unsupervised Modality-Transferable Video Highlight Detection with Representation Activation Sequence Learning
Mar 18, 2024Identifying highlight moments of raw video materials is crucial for improving the efficiency of editing videos that are pervasive on internet platforms. However, the extensive work of manually labeling footage has created obstacles to applying supervised methods to videos of unseen categories. The absence of an audio modality that contains valuable cues for highlight detection in many videos also makes it difficult to use multimodal strategies. In this paper, we propose a novel model with cross-modal perception for unsupervised highlight detection. The proposed model learns representations with visual-audio level semantics from image-audio pair data via a self-reconstruction task. To achieve unsupervised highlight detection, we investigate the latent representations of the network and propose the representation activation sequence learning (RASL) module with k-point contrastive learning to learn significant representation activations. To connect the visual modality with the audio modality, we use the symmetric contrastive learning (SCL) module to learn the paired visual and audio representations. Furthermore, an auxiliary task of masked feature vector sequence (FVS) reconstruction is simultaneously conducted during pretraining for representation enhancement. During inference, the cross-modal pretrained model can generate representations with paired visual-audio semantics given only the visual modality. The RASL module is used to output the highlight scores. The experimental results show that the proposed framework achieves superior performance compared to other state-of-the-art approaches.
REFORM: Removing False Correlation in Multi-level Interaction for CTR Prediction
Sep 26, 2023Click-through rate (CTR) prediction is a critical task in online advertising and recommendation systems, as accurate predictions are essential for user targeting and personalized recommendations. Most recent cutting-edge methods primarily focus on investigating complex implicit and explicit feature interactions. However, these methods neglect the issue of false correlations caused by confounding factors or selection bias. This problem is further magnified by the complexity and redundancy of these interactions. We propose a CTR prediction framework that removes false correlation in multi-level feature interaction, termed REFORM. The proposed REFORM framework exploits a wide range of multi-level high-order feature representations via a two-stream stacked recurrent structure while eliminating false correlations. The framework has two key components: I. The multi-level stacked recurrent (MSR) structure enables the model to efficiently capture diverse nonlinear interactions from feature spaces of different levels, and the richer representations lead to enhanced CTR prediction accuracy. II. The false correlation elimination (FCE) module further leverages Laplacian kernel mapping and sample reweighting methods to eliminate false correlations concealed within the multi-level features, allowing the model to focus on the true causal effects. Extensive experiments based on four challenging CTR datasets and our production dataset demonstrate that the proposed REFORM model achieves state-of-the-art performance. Codes, models and our dataset will be released at https://github.com/yansuoyuli/REFORM.
CALM: Contrastive Cross-modal Speaking Style Modeling for Expressive Text-to-Speech Synthesis
Aug 30, 2023



To further improve the speaking styles of synthesized speeches, current text-to-speech (TTS) synthesis systems commonly employ reference speeches to stylize their outputs instead of just the input texts. These reference speeches are obtained by manual selection which is resource-consuming, or selected by semantic features. However, semantic features contain not only style-related information, but also style irrelevant information. The information irrelevant to speaking style in the text could interfere the reference audio selection and result in improper speaking styles. To improve the reference selection, we propose Contrastive Acoustic-Linguistic Module (CALM) to extract the Style-related Text Feature (STF) from the text. CALM optimizes the correlation between the speaking style embedding and the extracted STF with contrastive learning. Thus, a certain number of the most appropriate reference speeches for the input text are selected by retrieving the speeches with the top STF similarities. Then the style embeddings are weighted summarized according to their STF similarities and used to stylize the synthesized speech of TTS. Experiment results demonstrate the effectiveness of our proposed approach, with both objective evaluations and subjective evaluations on the speaking styles of the synthesized speeches outperform a baseline approach with semantic-feature-based reference selection.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021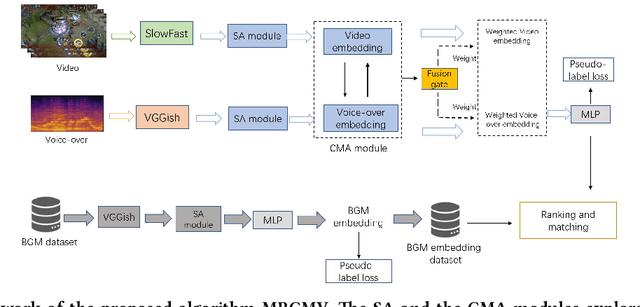
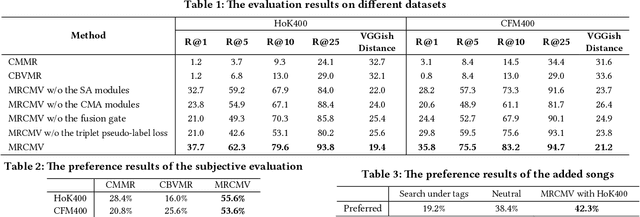
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.
Group-Skeleton-Based Human Action Recognition in Complex Events
Nov 26, 2020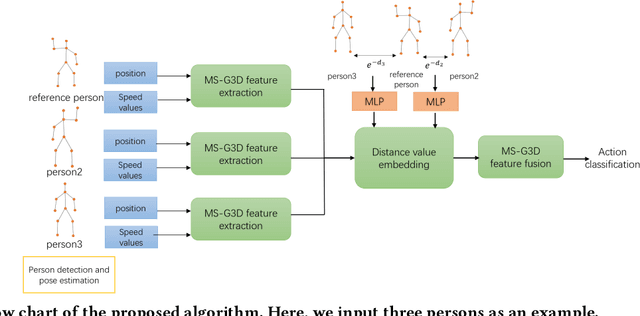


Human action recognition as an important application of computer vision has been studied for decades. Among various approaches, skeleton-based methods recently attract increasing attention due to their robust and superior performance. However, existing skeleton-based methods ignore the potential action relationships between different persons, while the action of a person is highly likely to be impacted by another person especially in complex events. In this paper, we propose a novel group-skeleton-based human action recognition method in complex events. This method first utilizes multi-scale spatial-temporal graph convolutional networks (MS-G3Ds) to extract skeleton features from multiple persons. In addition to the traditional key point coordinates, we also input the key point speed values to the networks for better performance. Then we use multilayer perceptrons (MLPs) to embed the distance values between the reference person and other persons into the extracted features. Lastly, all the features are fed into another MS-G3D for feature fusion and classification. For avoiding class imbalance problems, the networks are trained with a focal loss. The proposed algorithm is also our solution for the Large-scale Human-centric Video Analysis in Complex Events Challenge. Results on the HiEve dataset show that our method can give superior performance compared to other state-of-the-art methods.
Unsupervised Multi-stream Highlight detection for the Game "Honor of Kings"
Oct 22, 2019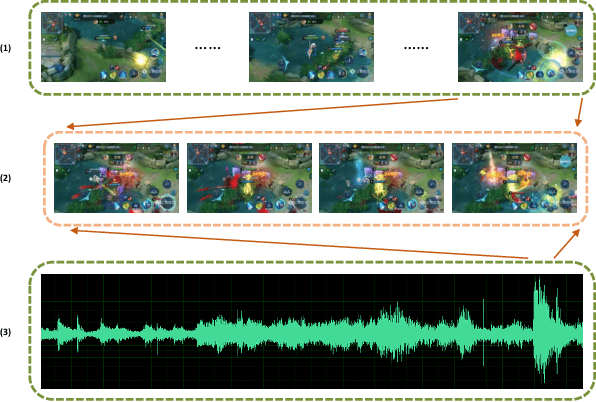


With the increasing popularity of E-sport live, Highlight Flashback has been a critical functionality of live platforms, which aggregates the overall exciting fighting scenes in a few seconds. In this paper, we introduce a novel training strategy without any additional annotation to automatically generate highlights for game video live. Considering that the existing manual edited clips contain more highlights than long game live videos, we perform pair-wise ranking constraints across clips from edited and long live videos. A multi-stream framework is also proposed to fuse spatial, temporal as well as audio features extracted from videos. To evaluate our method, we test on long game live videos with an average length of about 15 minutes. Extensive experimental results on videos demonstrate its satisfying performance on highlights generation and effectiveness by the fusion of three streams.
Understanding Video Content: Efficient Hero Detection and Recognition for the Game "Honor of Kings"
Jul 18, 2019


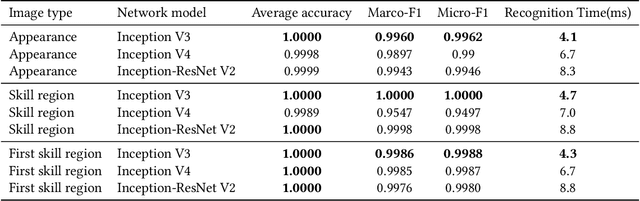
In order to understand content and automatically extract labels for videos of the game "Honor of Kings", it is necessary to detect and recognize characters (called "hero") together with their camps in the game video. In this paper, we propose an efficient two-stage algorithm to detect and recognize heros in game videos. First, we detect all heros in a video frame based on blood bar template-matching method, and classify them according to their camps (self/ friend/ enemy). Then we recognize the name of each hero using one or more deep convolution neural networks. Our method needs almost no work for labelling training and testing samples in the recognition stage. Experiments show its efficiency and accuracy in the task of hero detection and recognition in game videos.