 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Modality-Transferable Video Highlight Detection with Representation Activation Sequence Learning
Mar 18, 2024Identifying highlight moments of raw video materials is crucial for improving the efficiency of editing videos that are pervasive on internet platforms. However, the extensive work of manually labeling footage has created obstacles to applying supervised methods to videos of unseen categories. The absence of an audio modality that contains valuable cues for highlight detection in many videos also makes it difficult to use multimodal strategies. In this paper, we propose a novel model with cross-modal perception for unsupervised highlight detection. The proposed model learns representations with visual-audio level semantics from image-audio pair data via a self-reconstruction task. To achieve unsupervised highlight detection, we investigate the latent representations of the network and propose the representation activation sequence learning (RASL) module with k-point contrastive learning to learn significant representation activations. To connect the visual modality with the audio modality, we use the symmetric contrastive learning (SCL) module to learn the paired visual and audio representations. Furthermore, an auxiliary task of masked feature vector sequence (FVS) reconstruction is simultaneously conducted during pretraining for representation enhancement. During inference, the cross-modal pretrained model can generate representations with paired visual-audio semantics given only the visual modality. The RASL module is used to output the highlight scores. The experimental results show that the proposed framework achieves superior performance compared to other state-of-the-art approaches.
CALM: Contrastive Cross-modal Speaking Style Modeling for Expressive Text-to-Speech Synthesis
Aug 30, 2023



To further improve the speaking styles of synthesized speeches, current text-to-speech (TTS) synthesis systems commonly employ reference speeches to stylize their outputs instead of just the input texts. These reference speeches are obtained by manual selection which is resource-consuming, or selected by semantic features. However, semantic features contain not only style-related information, but also style irrelevant information. The information irrelevant to speaking style in the text could interfere the reference audio selection and result in improper speaking styles. To improve the reference selection, we propose Contrastive Acoustic-Linguistic Module (CALM) to extract the Style-related Text Feature (STF) from the text. CALM optimizes the correlation between the speaking style embedding and the extracted STF with contrastive learning. Thus, a certain number of the most appropriate reference speeches for the input text are selected by retrieving the speeches with the top STF similarities. Then the style embeddings are weighted summarized according to their STF similarities and used to stylize the synthesized speech of TTS. Experiment results demonstrate the effectiveness of our proposed approach, with both objective evaluations and subjective evaluations on the speaking styles of the synthesized speeches outperform a baseline approach with semantic-feature-based reference selection.
Improved Multiple-Image-Based Reflection Removal Algorithm Using Deep Neural Networks
Aug 10, 2022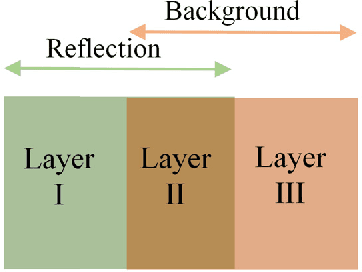

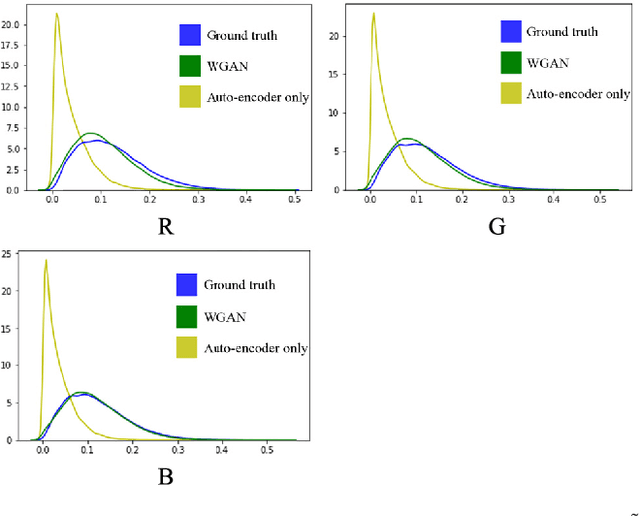

When imaging through a semi-reflective medium such as glass, the reflection of another scene can often be found in the captured images. It degrades the quality of the images and affects their subsequent analyses. In this paper, a novel deep neural network approach for solving the reflection problem in imaging is presented. Traditional reflection removal methods not only require long computation time for solving different optimization functions, their performance is also not guaranteed. As array cameras are readily available in nowadays imaging devices, we first suggest in this paper a multiple-image based depth estimation method using a convolutional neural network (CNN). The proposed network avoids the depth ambiguity problem due to the reflection in the image, and directly estimates the depths along the image edges. They are then used to classify the edges as belonging to the background or reflection. Since edges having similar depth values are error prone in the classification, they are removed from the reflection removal process. We suggest a generative adversarial network (GAN) to regenerate the removed background edges. Finally, the estimated background edge map is fed to another auto-encoder network to assist the extraction of the background from the original image. Experimental results show that the proposed reflection removal algorithm achieves superior performance both quantitatively and qualitatively as compared to the state-of-the-art methods. The proposed algorithm also shows much faster speed compared to the existing approaches using the traditional optimization methods.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021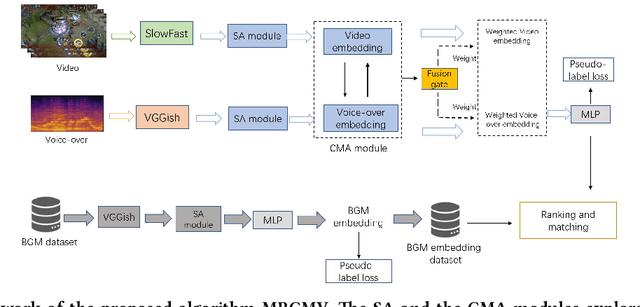
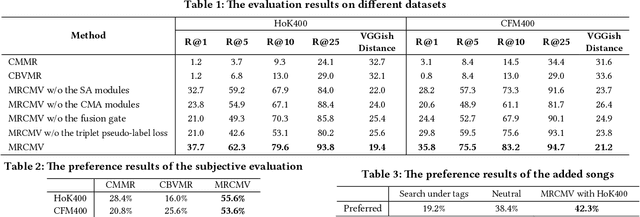
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.
Group-Skeleton-Based Human Action Recognition in Complex Events
Nov 26, 2020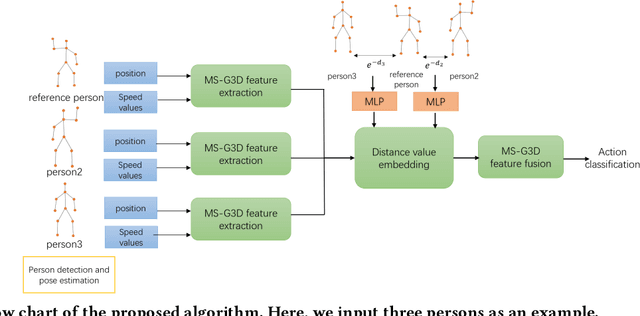


Human action recognition as an important application of computer vision has been studied for decades. Among various approaches, skeleton-based methods recently attract increasing attention due to their robust and superior performance. However, existing skeleton-based methods ignore the potential action relationships between different persons, while the action of a person is highly likely to be impacted by another person especially in complex events. In this paper, we propose a novel group-skeleton-based human action recognition method in complex events. This method first utilizes multi-scale spatial-temporal graph convolutional networks (MS-G3Ds) to extract skeleton features from multiple persons. In addition to the traditional key point coordinates, we also input the key point speed values to the networks for better performance. Then we use multilayer perceptrons (MLPs) to embed the distance values between the reference person and other persons into the extracted features. Lastly, all the features are fed into another MS-G3D for feature fusion and classification. For avoiding class imbalance problems, the networks are trained with a focal loss. The proposed algorithm is also our solution for the Large-scale Human-centric Video Analysis in Complex Events Challenge. Results on the HiEve dataset show that our method can give superior performance compared to other state-of-the-art methods.