 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-Net: Precipitation-Adaptive Mixture-of-Experts for Long-Tail Rainfall Nowcasting
Mar 14, 2026Precipitation nowcasting is vital for flood warning, agricultural management, and emergency response, yet two bottlenecks persist: the prohibitive cost of modeling million-scale spatiotemporal tokens from multi-variate atmospheric fields, and the extreme long-tailed rainfall distribution where heavy-to-torrential events -- those of greatest societal impact -- constitute fewer than 0.1% of all samples. We propose the Precipitation-Adaptive Network (PA-Net), a Transformer framework whose computational budget is explicitly governed by rainfall intensity. Its core component, Precipitation-Adaptive MoE (PA-MoE), dynamically scales the number of activated experts per token according to local precipitation magnitude, channeling richer representational capacity toward the rare yet critical heavy-rainfall tail. A Dual-Axis Compressed Latent Attention mechanism factorizes spatiotemporal attention with convolutional reduction to manage massive context lengths, while an intensity-aware training protocol progressively amplifies learning signals from extreme-rainfall samples. Experiment on ERA5 demonstrate consistent improvements over state-of-the-art baselines, with particularly significant gains in heavy-rain and rainstorm regimes.
MeTok: An Efficient Meteorological Tokenization with Hyper-Aligned Group Learning for Precipitation Nowcasting
Mar 14, 2026Recently, Transformer-based architectures have advanced meteorological prediction. However, this position-centric tokenizer conflicts with the core principle of meteorological systems, where the weather phenomena undoubtedly involve synergistic interactions among multiple elements while positional information constitutes merely a component of the boundary conditions. This paper focuses primarily on the task of precipitation nowcasting and develops an efficient distribution-centric Meteorological Tokenization (MeTok) scheme, which spatially sequences to group similar meteorological features. Based on the rearrangement, realigned group learning enhances robustness across precipitation patterns, especially extreme ones. Specifically, we introduce the Hyper-Aligned Grouping Transformer (HyAGTransformer) with two key improvements: 1) The Grouping Attention (GA) mechanism uses MeTok to enable self-aligned learning of features from different precipitation patterns; 2) The Neighborhood Feed-Forward Network (N-FFN) integrates adjacent group features, aggregating contextual information to boost patch embedding discriminability. Experiments on the ERA5 dataset for 6-hour forecasts show our method improves the IoU metric by at least 8.2% in extreme precipitation prediction compared to other methods. Additionally, it gains performance with more training data and increased parameters, demonstrating scalability, stability, and superiority over traditional methods.
UniVid: Pyramid Diffusion Model for High Quality Video Generation
Mar 14, 2026Diffusion-based text-to-video generation (T2V) or image-to-video (I2V) generation have emerged as a prominent research focus. However, there exists a challenge in integrating the two generative paradigms into a unified model. In this paper, we present a unified video generation model (UniVid) with hybrid conditions of the text prompt and reference image. Given these two available controls, our model can extract objects' appearance and their motion descriptions from textual prompts, while obtaining texture details and structural information from image clues to guide the video generation process. Specifically, we scale up the pre-trained text-to-image diffusion model for generating temporally coherent frames via introducing our temporal-pyramid cross-frame spatial-temporal attention modules and convolutions. To support bimodal control, we introduce a dual-stream cross-attention mechanism, whose attention scores can be freely re-weighted for interpolation of between single and two modalities controls during inference. Extensive experiments showcase that our UniVid achieves superior temporal coherence on T2V, I2V and (T+I)2V tasks.
Fast-Slow Efficient Training for Multimodal Large Language Models via Visual Token Pruning
Feb 03, 2026Multimodal Large Language Models (MLLMs) suffer from severe training inefficiency issue, which is associated with their massive model sizes and visual token numbers. Existing efforts in efficient training focus on reducing model sizes or trainable parameters. Inspired by the success of Visual Token Pruning (VTP) in improving inference efficiency, we are exploring another substantial research direction for efficient training by reducing visual tokens. However, applying VTP at the training stage results in a training-inference mismatch: pruning-trained models perform poorly when inferring on non-pruned full visual token sequences. To close this gap, we propose DualSpeed, a fast-slow framework for efficient training of MLLMs. The fast-mode is the primary mode, which incorporates existing VTP methods as plugins to reduce visual tokens, along with a mode isolator to isolate the model's behaviors. The slow-mode is the auxiliary mode, where the model is trained on full visual sequences to retain training-inference consistency. To boost its training, it further leverages self-distillation to learn from the sufficiently trained fast-mode. Together, DualSpeed can achieve both training efficiency and non-degraded performance. Experiments show DualSpeed accelerates the training of LLaVA-1.5 by 2.1$\times$ and LLaVA-NeXT by 4.0$\times$, retaining over 99% performance. Code: https://github.com/dingkun-zhang/DualSpeed
PruneRAG: Confidence-Guided Query Decomposition Trees for Efficient Retrieval-Augmented Generation
Jan 16, 2026Retrieval-augmented generation (RAG) has become a powerful framework for enhancing large language models in knowledge-intensive and reasoning tasks. However, as reasoning chains deepen or search trees expand, RAG systems often face two persistent failures: evidence forgetting, where retrieved knowledge is not effectively used, and inefficiency, caused by uncontrolled query expansions and redundant retrieval. These issues reveal a critical gap between retrieval and evidence utilization in current RAG architectures. We propose PruneRAG, a confidence-guided query decomposition framework that builds a structured query decomposition tree to perform stable and efficient reasoning. PruneRAG introduces three key mechanisms: adaptive node expansion that regulates tree width and depth, confidence-guided decisions that accept reliable answers and prune uncertain branches, and fine-grained retrieval that extracts entity-level anchors to improve retrieval precision. Together, these components preserve salient evidence throughout multi-hop reasoning while significantly reducing retrieval overhead. To better analyze evidence misuse, we define the Evidence Forgetting Rate as a metric to quantify cases where golden evidence is retrieved but not correctly used. Extensive experiments across various multi-hop QA benchmarks show that PruneRAG achieves superior accuracy and efficiency over state-of-the-art baselines.
RayFusion: Ray Fusion Enhanced Collaborative Visual Perception
Oct 09, 2025



Collaborative visual perception methods have gained widespread attention in the autonomous driving community in recent years due to their ability to address sensor limitation problems. However, the absence of explicit depth information often makes it difficult for camera-based perception systems, e.g., 3D object detection, to generate accurate predictions. To alleviate the ambiguity in depth estimation, we propose RayFusion, a ray-based fusion method for collaborative visual perception. Using ray occupancy information from collaborators, RayFusion reduces redundancy and false positive predictions along camera rays, enhancing the detection performance of purely camera-based collaborative perception systems. Comprehensive experiments show that our method consistently outperforms existing state-of-the-art models, substantially advancing the performance of collaborative visual perception. The code is available at https://github.com/wangsh0111/RayFusion.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025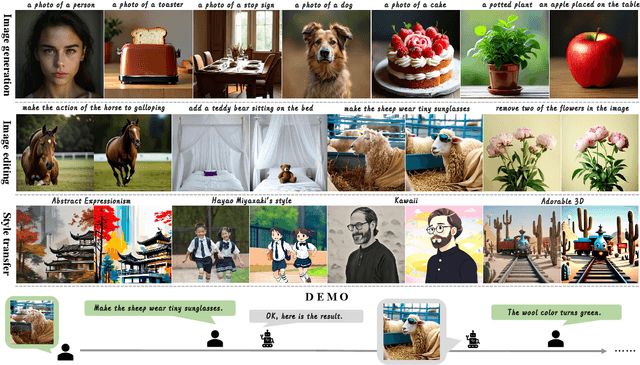

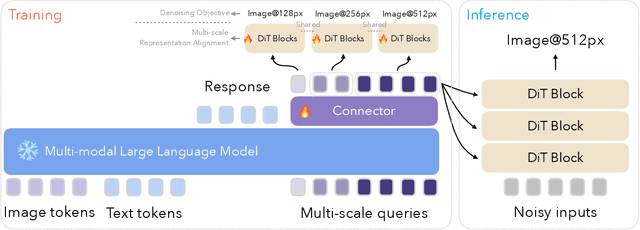
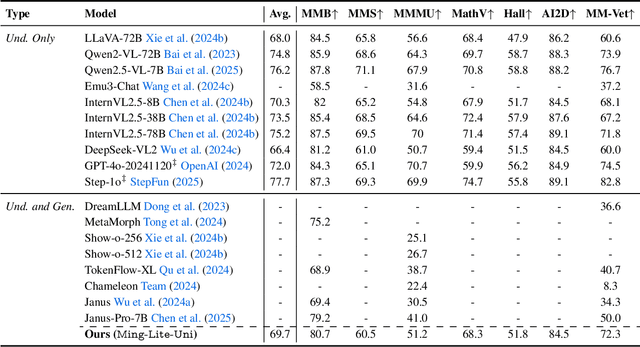
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Merge then Realign: Simple and Effective Modality-Incremental Continual Learning for Multimodal LLMs
Mar 08, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enhanced their versatility as they integrate a growing number of modalities. Considering the heavy cost of training MLLMs, it is necessary to reuse the existing ones and further extend them to more modalities through Modality-incremental Continual Learning (MCL). However, this often comes with a performance degradation in the previously learned modalities. In this work, we revisit the MCL and investigate a more severe issue it faces in contrast to traditional continual learning, that its degradation comes not only from catastrophic forgetting but also from the misalignment between the modality-agnostic and modality-specific components. To address this problem, we propose an elegantly simple MCL paradigm called "MErge then ReAlign" (MERA). Our method avoids introducing heavy training overhead or modifying the model architecture, hence is easy to deploy and highly reusable in the MLLM community. Extensive experiments demonstrate that, despite the simplicity of MERA, it shows impressive performance, holding up to a 99.84% Backward Relative Gain when extending to four modalities, achieving a nearly lossless MCL performance.
IFTR: An Instance-Level Fusion Transformer for Visual Collaborative Perception
Jul 13, 2024



Multi-agent collaborative perception has emerged as a widely recognized technology in the field of autonomous driving in recent years. However, current collaborative perception predominantly relies on LiDAR point clouds, with significantly less attention given to methods using camera images. This severely impedes the development of budget-constrained collaborative systems and the exploitation of the advantages offered by the camera modality. This work proposes an instance-level fusion transformer for visual collaborative perception (IFTR), which enhances the detection performance of camera-only collaborative perception systems through the communication and sharing of visual features. To capture the visual information from multiple agents, we design an instance feature aggregation that interacts with the visual features of individual agents using predefined grid-shaped bird eye view (BEV) queries, generating more comprehensive and accurate BEV features. Additionally, we devise a cross-domain query adaptation as a heuristic to fuse 2D priors, implicitly encoding the candidate positions of targets. Furthermore, IFTR optimizes communication efficiency by sending instance-level features, achieving an optimal performance-bandwidth trade-off. We evaluate the proposed IFTR on a real dataset, DAIR-V2X, and two simulated datasets, OPV2V and V2XSet, achieving performance improvements of 57.96%, 9.23% and 12.99% in AP@70 metrics compared to the previous SOTAs, respectively. Extensive experiments demonstrate the superiority of IFTR and the effectiveness of its key components. The code is available at https://github.com/wangsh0111/IFTR.