 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALM: Contrastive Cross-modal Speaking Style Modeling for Expressive Text-to-Speech Synthesis
Aug 30, 2023



To further improve the speaking styles of synthesized speeches, current text-to-speech (TTS) synthesis systems commonly employ reference speeches to stylize their outputs instead of just the input texts. These reference speeches are obtained by manual selection which is resource-consuming, or selected by semantic features. However, semantic features contain not only style-related information, but also style irrelevant information. The information irrelevant to speaking style in the text could interfere the reference audio selection and result in improper speaking styles. To improve the reference selection, we propose Contrastive Acoustic-Linguistic Module (CALM) to extract the Style-related Text Feature (STF) from the text. CALM optimizes the correlation between the speaking style embedding and the extracted STF with contrastive learning. Thus, a certain number of the most appropriate reference speeches for the input text are selected by retrieving the speeches with the top STF similarities. Then the style embeddings are weighted summarized according to their STF similarities and used to stylize the synthesized speech of TTS. Experiment results demonstrate the effectiveness of our proposed approach, with both objective evaluations and subjective evaluations on the speaking styles of the synthesized speeches outperform a baseline approach with semantic-feature-based reference selection.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021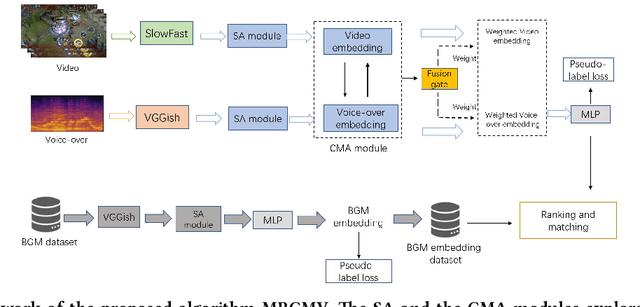
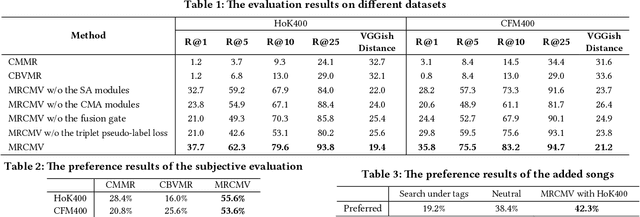
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.
Unsupervised Multi-stream Highlight detection for the Game "Honor of Kings"
Oct 22, 2019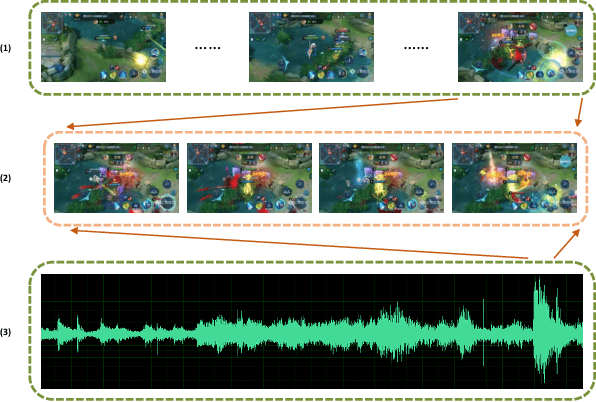


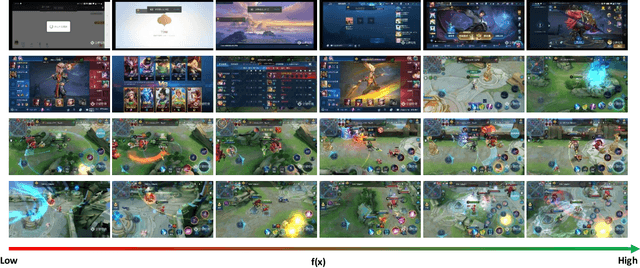
With the increasing popularity of E-sport live, Highlight Flashback has been a critical functionality of live platforms, which aggregates the overall exciting fighting scenes in a few seconds. In this paper, we introduce a novel training strategy without any additional annotation to automatically generate highlights for game video live. Considering that the existing manual edited clips contain more highlights than long game live videos, we perform pair-wise ranking constraints across clips from edited and long live videos. A multi-stream framework is also proposed to fuse spatial, temporal as well as audio features extracted from videos. To evaluate our method, we test on long game live videos with an average length of about 15 minutes. Extensive experimental results on videos demonstrate its satisfying performance on highlights generation and effectiveness by the fusion of three streams.