 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Emotion Prediction Using Recurrent Neural Networks
May 10, 2024



This study explores the application of recurrent neural networks to recognize emotions conveyed in music, aiming to enhance music recommendation systems and support therapeutic interventions by tailoring music to fit listeners' emotional states. We utilize Russell's Emotion Quadrant to categorize music into four distinct emotional regions and develop models capable of accurately predicting these categories. Our approach involves extracting a comprehensive set of audio features using Librosa and applying various recurrent neural network architectures, including standard RNNs, Bidirectional RNNs, and Long Short-Term Memory (LSTM) networks. Initial experiments are conducted using a dataset of 900 audio clips, labeled according to the emotional quadrants. We compare the performance of our neural network models against a set of baseline classifiers and analyze their effectiveness in capturing the temporal dynamics inherent in musical expression. The results indicate that simpler RNN architectures may perform comparably or even superiorly to more complex models, particularly in smaller datasets. We've also applied the following experiments on larger datasets: one is augmented based on our original dataset, and the other is from other sources. This research not only enhances our understanding of the emotional impact of music but also demonstrates the potential of neural networks in creating more personalized and emotionally resonant music recommendation and therapy systems.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021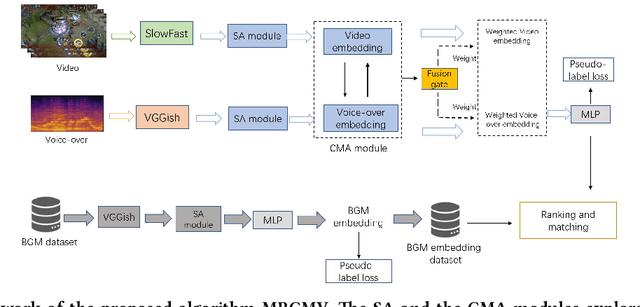
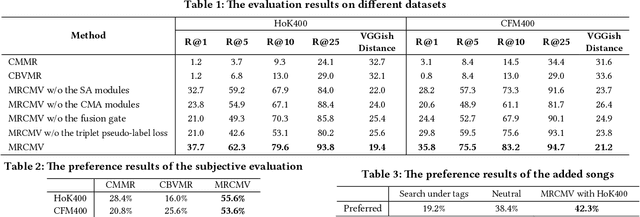
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.