 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrVideo: Document Retrieval Based Long Video Understanding
Jun 18, 2024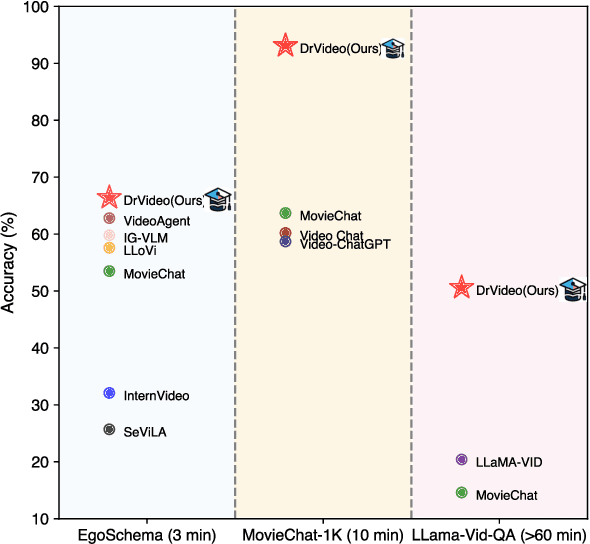
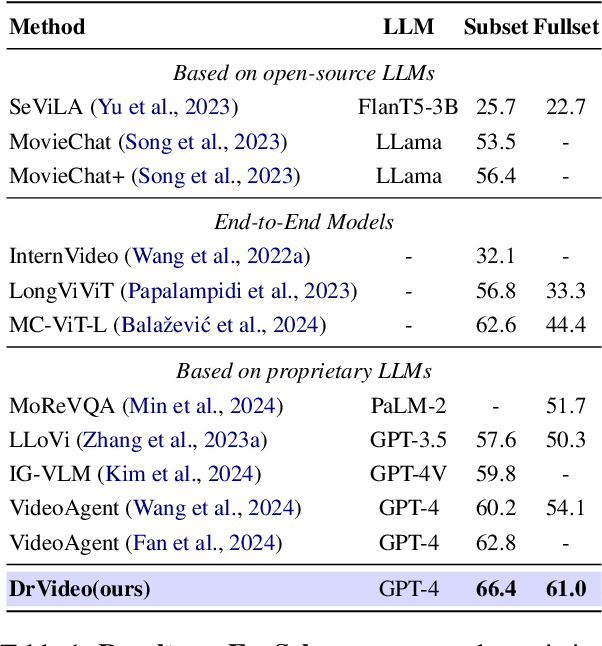
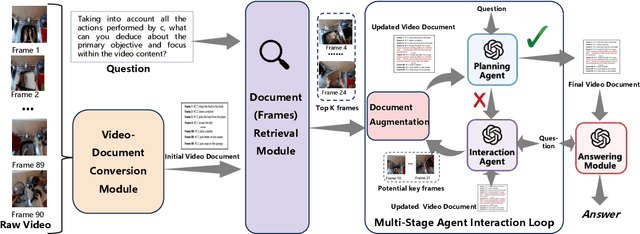
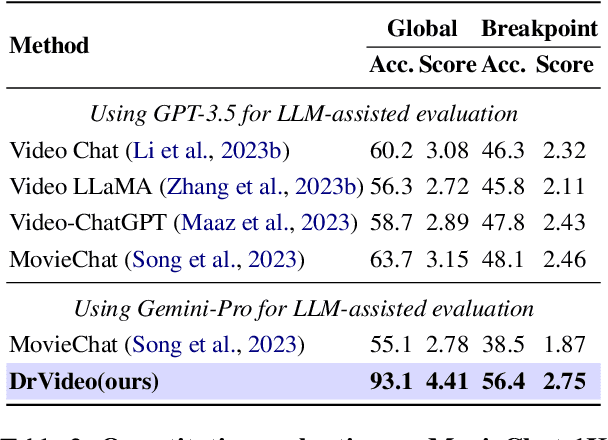
Existing methods for long video understanding primarily focus on videos only lasting tens of seconds, with limited exploration of techniques for handling longer videos. The increased number of frames in longer videos presents two main challenges: difficulty in locating key information and performing long-range reasoning. Thus, we propose DrVideo, a document-retrieval-based system designed for long video understanding. Our key idea is to convert the long-video understanding problem into a long-document understanding task so as to effectively leverage the power of large language models. Specifically, DrVideo transforms a long video into a text-based long document to initially retrieve key frames and augment the information of these frames, which is used this as the system's starting point. It then employs an agent-based iterative loop to continuously search for missing information, augment relevant data, and provide final predictions in a chain-of-thought manner once sufficient question-related information is gathered. Extensive experiments on long video benchmarks confirm the effectiveness of our method. DrVideo outperforms existing state-of-the-art methods with +3.8 accuracy on EgoSchema benchmark (3 minutes), +17.9 in MovieChat-1K break mode, +38.0 in MovieChat-1K global mode (10 minutes), and +30.2 on the LLama-Vid QA dataset (over 60 minutes).
DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
Apr 06, 2024Diffusion models have recently gained prominence as powerful deep generative models, demonstrating unmatched performance across various domains. However, their potential in multi-sensor fusion remains largely unexplored. In this work, we introduce DifFUSER, a novel approach that leverages diffusion models for multi-modal fusion in 3D object detection and BEV map segmentation. Benefiting from the inherent denoising property of diffusion, DifFUSER is able to refine or even synthesize sensor features in case of sensor malfunction, thereby improving the quality of the fused output. In terms of architecture, our DifFUSER blocks are chained together in a hierarchical BiFPN fashion, termed cMini-BiFPN, offering an alternative architecture for latent diffusion. We further introduce a Gated Self-conditioned Modulated (GSM) latent diffusion module together with a Progressive Sensor Dropout Training (PSDT) paradigm, designed to add stronger conditioning to the diffusion process and robustness to sensor failures. Our extensive evaluations on the Nuscenes dataset reveal that DifFUSER not only achieves state-of-the-art performance with a 69.1% mIOU in BEV map segmentation tasks but also competes effectively with leading transformer-based fusion techniques in 3D object detection.
JRDB-PanoTrack: An Open-world Panoptic Segmentation and Tracking Robotic Dataset in Crowded Human Environments
Apr 02, 2024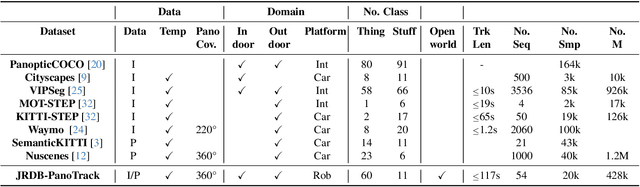
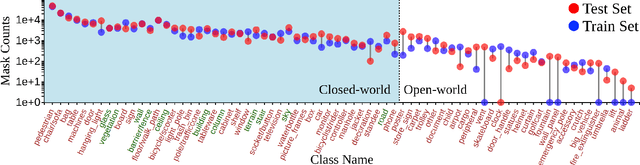
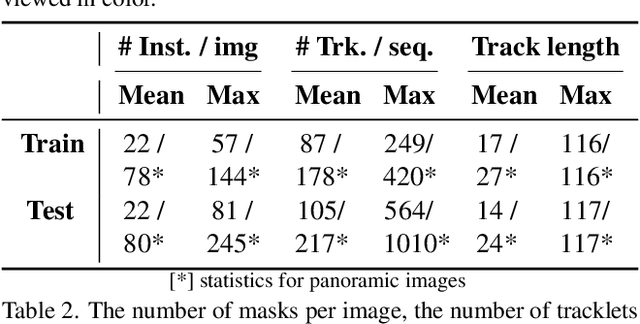

Autonomous robot systems have attracted increasing research attention in recent years, where environment understanding is a crucial step for robot navigation, human-robot interaction, and decision. Real-world robot systems usually collect visual data from multiple sensors and are required to recognize numerous objects and their movements in complex human-crowded settings. Traditional benchmarks, with their reliance on single sensors and limited object classes and scenarios, fail to provide the comprehensive environmental understanding robots need for accurate navigation, interaction, and decision-making. As an extension of JRDB dataset, we unveil JRDB-PanoTrack, a novel open-world panoptic segmentation and tracking benchmark, towards more comprehensive environmental perception. JRDB-PanoTrack includes (1) various data involving indoor and outdoor crowded scenes, as well as comprehensive 2D and 3D synchronized data modalities; (2) high-quality 2D spatial panoptic segmentation and temporal tracking annotations, with additional 3D label projections for further spatial understanding; (3) diverse object classes for closed- and open-world recognition benchmarks, with OSPA-based metrics for evaluation. Extensive evaluation of leading methods shows significant challenges posed by our dataset.
Open-Vocabulary Scene Text Recognition via Pseudo-Image Labeling and Margin Loss
Mar 12, 2024Scene text recognition is an important and challenging task in computer vision. However, most prior works focus on recognizing pre-defined words, while there are various out-of-vocabulary (OOV) words in real-world applications. In this paper, we propose a novel open-vocabulary text recognition framework, Pseudo-OCR, to recognize OOV words. The key challenge in this task is the lack of OOV training data. To solve this problem, we first propose a pseudo label generation module that leverages character detection and image inpainting to produce substantial pseudo OOV training data from real-world images. Unlike previous synthetic data, our pseudo OOV data contains real characters and backgrounds to simulate real-world applications. Secondly, to reduce noises in pseudo data, we present a semantic checking mechanism to filter semantically meaningful data. Thirdly, we introduce a quality-aware margin loss to boost the training with pseudo data. Our loss includes a margin-based part to enhance the classification ability, and a quality-aware part to penalize low-quality samples in both real and pseudo data. Extensive experiments demonstrate that our approach outperforms the state-of-the-art on eight datasets and achieves the first rank in the ICDAR2022 challenge.
Unified Open-Vocabulary Dense Visual Prediction
Jul 17, 2023



In recent years, open-vocabulary (OV) dense visual prediction (such as OV object detection, semantic, instance and panoptic segmentations) has attracted increasing research attention. However, most of existing approaches are task-specific and individually tackle each task. In this paper, we propose a Unified Open-Vocabulary Network (UOVN) to jointly address four common dense prediction tasks. Compared with separate models, a unified network is more desirable for diverse industrial applications. Moreover, OV dense prediction training data is relatively less. Separate networks can only leverage task-relevant training data, while a unified approach can integrate diverse training data to boost individual tasks. We address two major challenges in unified OV prediction. Firstly, unlike unified methods for fixed-set predictions, OV networks are usually trained with multi-modal data. Therefore, we propose a multi-modal, multi-scale and multi-task (MMM) decoding mechanism to better leverage multi-modal data. Secondly, because UOVN uses data from different tasks for training, there are significant domain and task gaps. We present a UOVN training mechanism to reduce such gaps. Experiments on four datasets demonstrate the effectiveness of our UOVN.
CoactSeg: Learning from Heterogeneous Data for New Multiple Sclerosis Lesion Segmentation
Jul 10, 2023

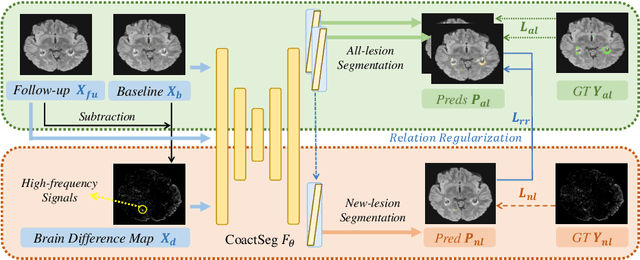
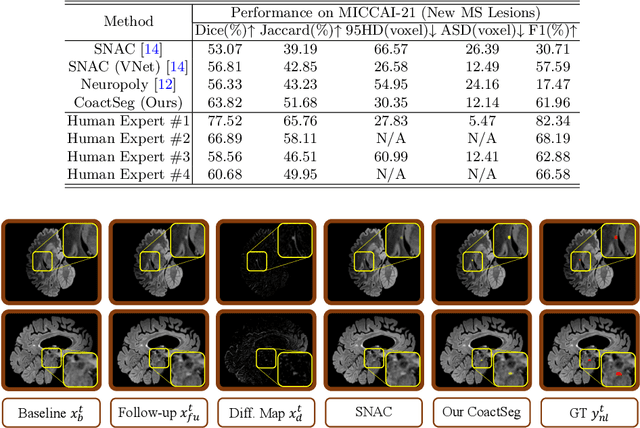
New lesion segmentation is essential to estimate the disease progression and therapeutic effects during multiple sclerosis (MS) clinical treatments. However, the expensive data acquisition and expert annotation restrict the feasibility of applying large-scale deep learning models. Since single-time-point samples with all-lesion labels are relatively easy to collect, exploiting them to train deep models is highly desirable to improve new lesion segmentation. Therefore, we proposed a coaction segmentation (CoactSeg) framework to exploit the heterogeneous data (i.e., new-lesion annotated two-time-point data and all-lesion annotated single-time-point data) for new MS lesion segmentation. The CoactSeg model is designed as a unified model, with the same three inputs (the baseline, follow-up, and their longitudinal brain differences) and the same three outputs (the corresponding all-lesion and new-lesion predictions), no matter which type of heterogeneous data is being used. Moreover, a simple and effective relation regularization is proposed to ensure the longitudinal relations among the three outputs to improve the model learning. Extensive experiments demonstrate that utilizing the heterogeneous data and the proposed longitudinal relation constraint can significantly improve the performance for both new-lesion and all-lesion segmentation tasks. Meanwhile, we also introduce an in-house MS-23v1 dataset, including 38 Oceania single-time-point samples with all-lesion labels. Codes and the dataset are released at https://github.com/ycwu1997/CoactSeg.
Open-Vocabulary Object Detection via Scene Graph Discovery
Jul 07, 2023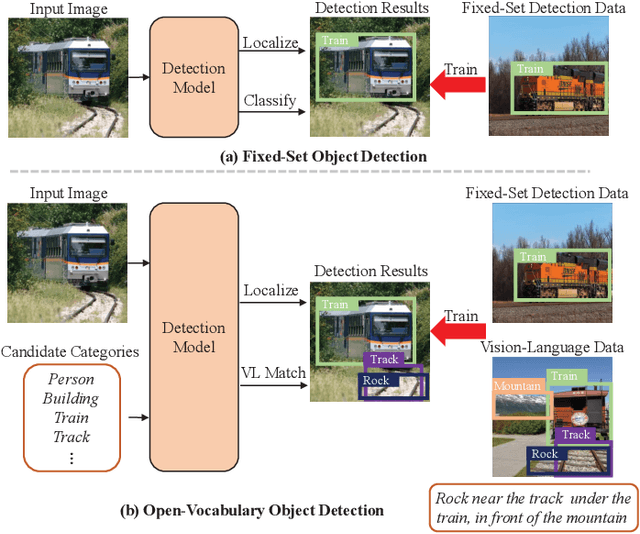
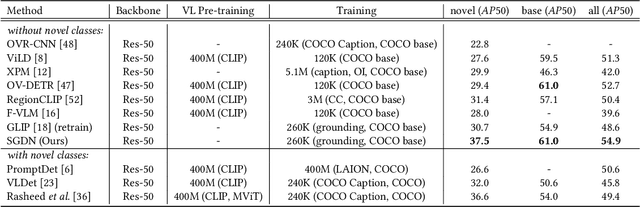
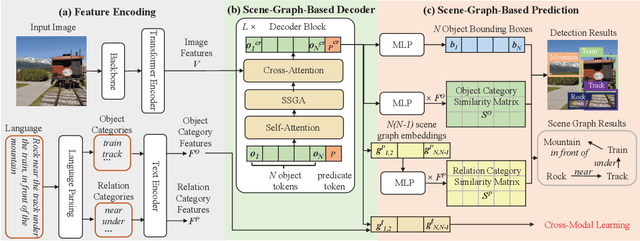
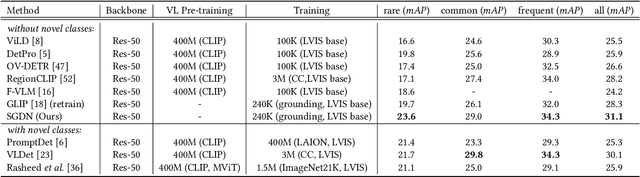
In recent years, open-vocabulary (OV) object detection has attracted increasing research attention. Unlike traditional detection, which only recognizes fixed-category objects, OV detection aims to detect objects in an open category set. Previous works often leverage vision-language (VL) training data (e.g., referring grounding data) to recognize OV objects. However, they only use pairs of nouns and individual objects in VL data, while these data usually contain much more information, such as scene graphs, which are also crucial for OV detection. In this paper, we propose a novel Scene-Graph-Based Discovery Network (SGDN) that exploits scene graph cues for OV detection. Firstly, a scene-graph-based decoder (SGDecoder) including sparse scene-graph-guided attention (SSGA) is presented. It captures scene graphs and leverages them to discover OV objects. Secondly, we propose scene-graph-based prediction (SGPred), where we build a scene-graph-based offset regression (SGOR) mechanism to enable mutual enhancement between scene graph extraction and object localization. Thirdly, we design a cross-modal learning mechanism in SGPred. It takes scene graphs as bridges to improve the consistency between cross-modal embeddings for OV object classification. Experiments on COCO and LVIS demonstrate the effectiveness of our approach. Moreover, we show the ability of our model for OV scene graph detection, while previous OV scene graph generation methods cannot tackle this task.
Class Enhancement Losses with Pseudo Labels for Zero-shot Semantic Segmentation
Jan 18, 2023



Recent mask proposal models have significantly improved the performance of zero-shot semantic segmentation. However, the use of a `background' embedding during training in these methods is problematic as the resulting model tends to over-learn and assign all unseen classes as the background class instead of their correct labels. Furthermore, they ignore the semantic relationship of text embeddings, which arguably can be highly informative for zero-shot prediction as seen classes may have close relationship with unseen classes. To this end, this paper proposes novel class enhancement losses to bypass the use of the background embbedding during training, and simultaneously exploit the semantic relationship between text embeddings and mask proposals by ranking the similarity scores. To further capture the relationship between seen and unseen classes, we propose an effective pseudo label generation pipeline using pretrained vision-language model. Extensive experiments on several benchmark datasets show that our method achieves overall the best performance for zero-shot semantic segmentation. Our method is flexible, and can also be applied to the challenging open-vocabulary semantic segmentation problem.
Transformer Scale Gate for Semantic Segmentation
May 14, 2022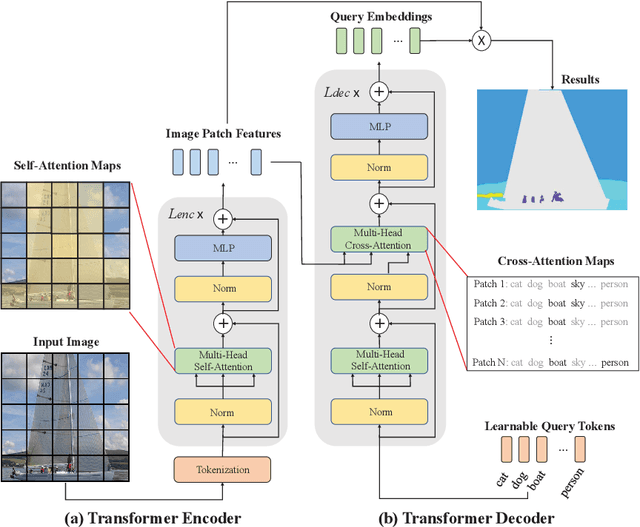
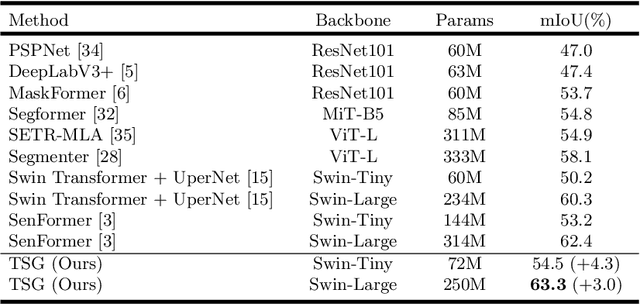

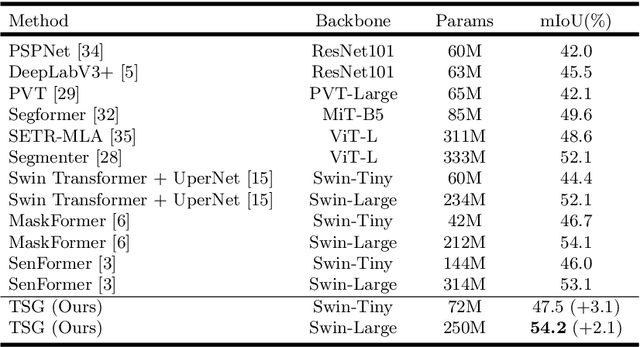
Effectively encoding multi-scale contextual information is crucial for accurate semantic segmentation. Existing transformer-based segmentation models combine features across scales without any selection, where features on sub-optimal scales may degrade segmentation outcomes. Leveraging from the inherent properties of Vision Transformers, we propose a simple yet effective module, Transformer Scale Gate (TSG), to optimally combine multi-scale features.TSG exploits cues in self and cross attentions in Vision Transformers for the scale selection. TSG is a highly flexible plug-and-play module, and can easily be incorporated with any encoder-decoder-based hierarchical vision Transformer architecture. Extensive experiments on the Pascal Context and ADE20K datasets demonstrate that our feature selection strategy achieves consistent gains.
ProposalCLIP: Unsupervised Open-Category Object Proposal Generation via Exploiting CLIP Cues
Jan 18, 2022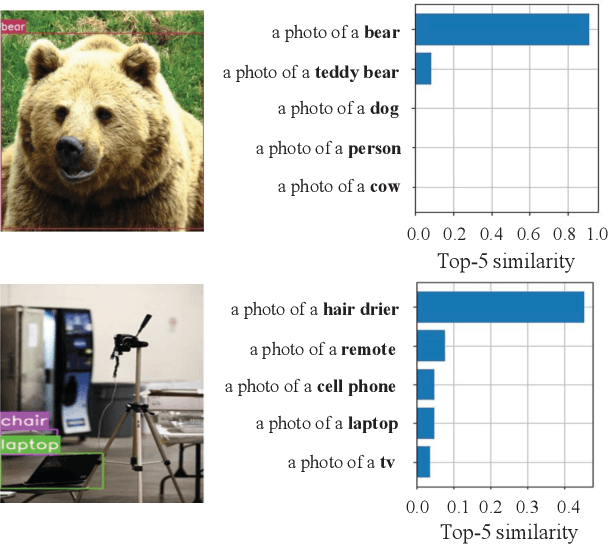
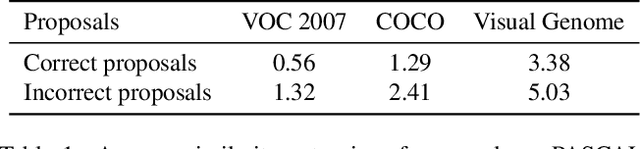

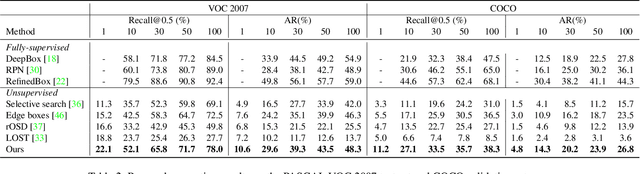
Object proposal generation is an important and fundamental task in computer vision. In this paper, we propose ProposalCLIP, a method towards unsupervised open-category object proposal generation. Unlike previous works which require a large number of bounding box annotations and/or can only generate proposals for limited object categories, our ProposalCLIP is able to predict proposals for a large variety of object categories without annotations, by exploiting CLIP (contrastive language-image pre-training) cues. Firstly, we analyze CLIP for unsupervised open-category proposal generation and design an objectness score based on our empirical analysis on proposal selection. Secondly, a graph-based merging module is proposed to solve the limitations of CLIP cues and merge fragmented proposals. Finally, we present a proposal regression module that extracts pseudo labels based on CLIP cues and trains a lightweight network to further refine proposals. Extensive experiments on PASCAL VOC, COCO and Visual Genome datasets show that our ProposalCLIP can better generate proposals than previous state-of-the-art methods. Our ProposalCLIP also shows benefits for downstream tasks, such as unsupervised object detection.