 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Structure and Element Aware Learning to Improve Long Structured Document Retrieval
Aug 28, 2025In long structured document retrieval, existing methods typically fine-tune pre-trained language models (PLMs) using contrastive learning on datasets lacking explicit structural information. This practice suffers from two critical issues: 1) current methods fail to leverage structural features and element-level semantics effectively, and 2) the lack of datasets containing structural metadata. To bridge these gaps, we propose \our, a novel contrastive learning framework. It leverages structure-aware learning to preserve semantic hierarchies and masked element alignment for fine-grained semantic discrimination. Furthermore, we release \dataset, a long structured document retrieval dataset with rich structural annotations. Extensive experiments on both released and industrial datasets across various modern PLMs, along with online A/B testing, demonstrate consistent performance improvements, boosting NDCG@10 from 73.96\% to 77.84\% on BGE-M3. The resources are available at https://github.com/xinhaoH/SEAL.
Resolving Multi-Condition Confusion for Finetuning-Free Personalized Image Generation
Sep 26, 2024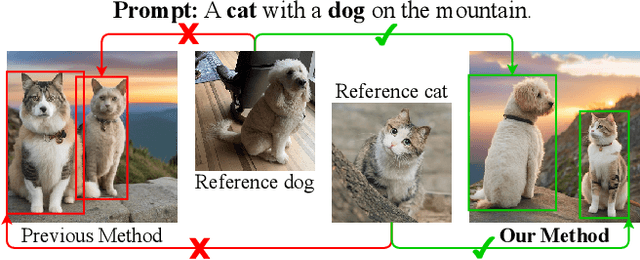

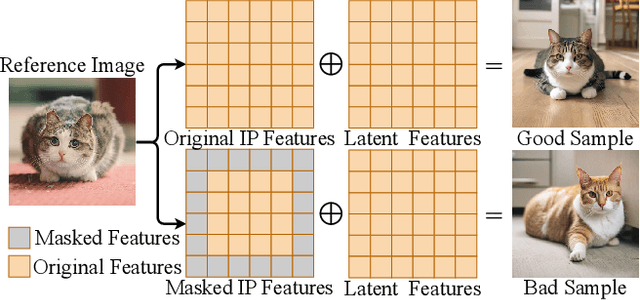
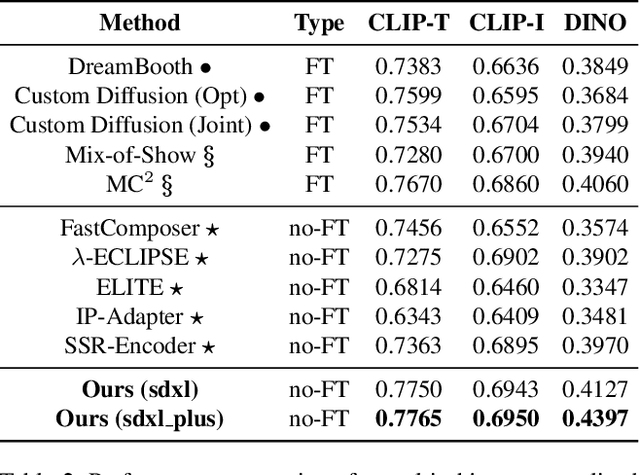
Personalized text-to-image generation methods can generate customized images based on the reference images, which have garnered wide research interest. Recent methods propose a finetuning-free approach with a decoupled cross-attention mechanism to generate personalized images requiring no test-time finetuning. However, when multiple reference images are provided, the current decoupled cross-attention mechanism encounters the object confusion problem and fails to map each reference image to its corresponding object, thereby seriously limiting its scope of application. To address the object confusion problem, in this work we investigate the relevance of different positions of the latent image features to the target object in diffusion model, and accordingly propose a weighted-merge method to merge multiple reference image features into the corresponding objects. Next, we integrate this weighted-merge method into existing pre-trained models and continue to train the model on a multi-object dataset constructed from the open-sourced SA-1B dataset. To mitigate object confusion and reduce training costs, we propose an object quality score to estimate the image quality for the selection of high-quality training samples. Furthermore, our weighted-merge training framework can be employed on single-object generation when a single object has multiple reference images. The experiments verify that our method achieves superior performance to the state-of-the-arts on the Concept101 dataset and DreamBooth dataset of multi-object personalized image generation, and remarkably improves the performance on single-object personalized image generation. Our code is available at https://github.com/hqhQAQ/MIP-Adapter.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021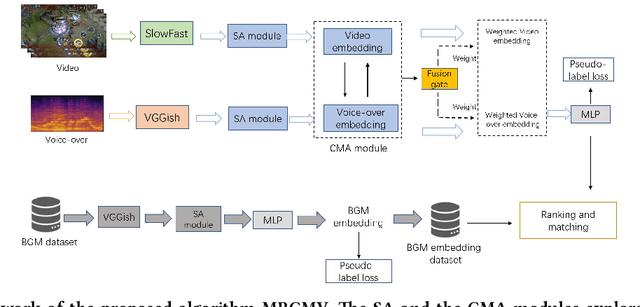
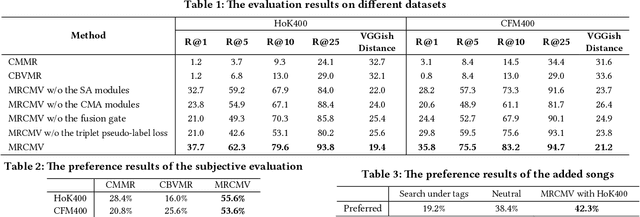
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.
Learning High-order Structural and Attribute information by Knowledge Graph Attention Networks for Enhancing Knowledge Graph Embedding
Oct 10, 2019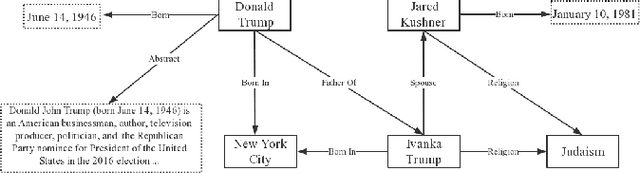



The goal of representation learning of knowledge graph is to encode both entities and relations into a low-dimensional embedding spaces. Many recent works have demonstrated the benefits of knowledge graph embedding on knowledge graph completion task, such as relation extraction. However, we observe that: 1) existing method just take direct relations between entities into consideration and fails to express high-order structural relationship between entities; 2) these methods just leverage relation triples of KGs while ignoring a large number of attribute triples that encoding rich semantic information. To overcome these limitations, this paper propose a novel knowledge graph embedding method, named KANE, which is inspired by the recent developments of graph convolutional networks (GCN). KANE can capture both high-order structural and attribute information of KGs in an efficient, explicit and unified manner under the graph convolutional networks framework. Empirical results on three datasets show that KANE significantly outperforms seven state-of-arts methods. Further analysis verify the efficiency of our method and the benefits brought by the attention mechanism.