 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLCache: Computing 2% Vision Tokens and Reusing 98% for Vision-Language Inference
Dec 18, 2025This paper presents VLCache, a cache reuse framework that exploits both Key-Value (KV) cache and encoder cache from prior multimodal inputs to eliminate costly recomputation when the same multimodal inputs recur. Unlike previous heuristic approaches, we formally identify the cumulative reuse error effect and demonstrate how to minimize the non-prefix cache reuse error effectively. We further analyze the varying importance of model layers and propose a dynamic, layer-aware recomputation strategy to balance accuracy and efficiency. Experimental results show that VLCache achieves an accuracy on par with full recomputation, while requiring only 2-5% of the tokens to compute, yielding 1.2x-16x TTFT speedups. We develop an experimental implementation of the proposed VLCache pipeline based on SGLang, enabling significantly faster inference in practical deployments.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
Social Commonsense-Guided Search Query Generation for Open-Domain Knowledge-Powered Conversations
Oct 22, 2023



Open-domain dialog involves generating search queries that help obtain relevant knowledge for holding informative conversations. However, it can be challenging to determine what information to retrieve when the user is passive and does not express a clear need or request. To tackle this issue, we present a novel approach that focuses on generating internet search queries that are guided by social commonsense. Specifically, we leverage a commonsense dialog system to establish connections related to the conversation topic, which subsequently guides our query generation. Our proposed framework addresses passive user interactions by integrating topic tracking, commonsense response generation and instruction-driven query generation. Through extensive evaluations, we show that our approach overcomes limitations of existing query generation techniques that rely solely on explicit dialog information, and produces search queries that are more relevant, specific, and compelling, ultimately resulting in more engaging responses.
Unsupervised Multi-stream Highlight detection for the Game "Honor of Kings"
Oct 22, 2019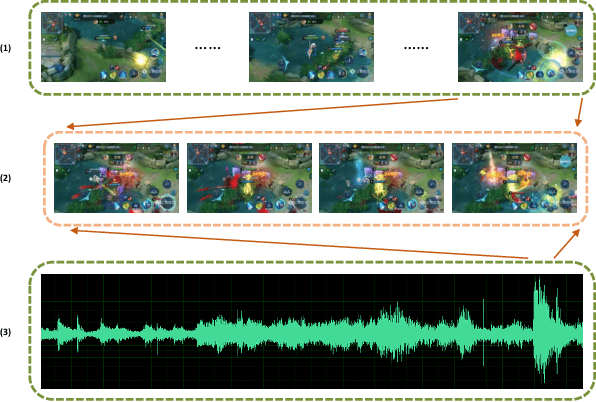


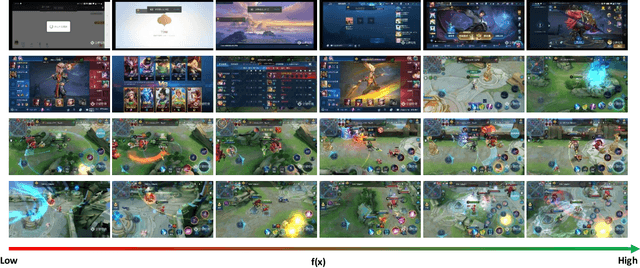
With the increasing popularity of E-sport live, Highlight Flashback has been a critical functionality of live platforms, which aggregates the overall exciting fighting scenes in a few seconds. In this paper, we introduce a novel training strategy without any additional annotation to automatically generate highlights for game video live. Considering that the existing manual edited clips contain more highlights than long game live videos, we perform pair-wise ranking constraints across clips from edited and long live videos. A multi-stream framework is also proposed to fuse spatial, temporal as well as audio features extracted from videos. To evaluate our method, we test on long game live videos with an average length of about 15 minutes. Extensive experimental results on videos demonstrate its satisfying performance on highlights generation and effectiveness by the fusion of three streams.
Understanding Video Content: Efficient Hero Detection and Recognition for the Game "Honor of Kings"
Jul 18, 2019


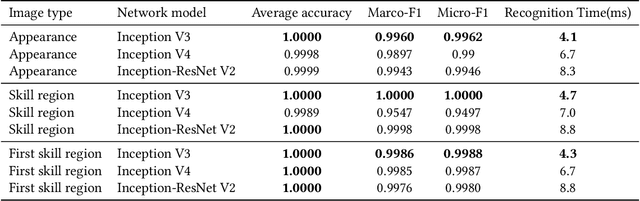
In order to understand content and automatically extract labels for videos of the game "Honor of Kings", it is necessary to detect and recognize characters (called "hero") together with their camps in the game video. In this paper, we propose an efficient two-stage algorithm to detect and recognize heros in game videos. First, we detect all heros in a video frame based on blood bar template-matching method, and classify them according to their camps (self/ friend/ enemy). Then we recognize the name of each hero using one or more deep convolution neural networks. Our method needs almost no work for labelling training and testing samples in the recognition stage. Experiments show its efficiency and accuracy in the task of hero detection and recognition in game videos.