 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncWebRL: Efficient Multi-Step RL for Visual Web Agents
Jun 04, 2026Training vision-language web agents with multi-step RL is compute-intensive, with two dominant forms of inefficiency: idle GPUs in synchronous RL, and trajectories that use more steps and tokens than necessary. We present AsyncWebRL, which addresses both. On the system side, an asynchronous design overlaps rollout, gradient update, and policy refresh across iterations, paired with two web-agent-specific adaptations, namely an everlasting rollout pool and lightweight screenshot handling, that together deliver up to a $2.9\times$ end-to-end training-throughput speedup over the previously fastest open synchronous pipeline (WebGym). On the algorithmic side, we identify the per-trajectory normalizer $1/|τ_i|$ in multi-step GRPO as the root cause of trajectory-level and token-level inefficiency: because failures are systematically longer than successes, it down-weights the negative gradient on failed tokens, so the policy keeps producing verbose memory schemas. Replacing $1/|τ_i|$ with a constant $1/k$ breaks this coupling, contracting trajectories while preserving aggregate success. Together, these contributions set a new open-source state of the art on the WebGym out-of-distribution test split (+5.8% relative over the 42.9% prior best), with the largest gains on the harder slices (+42% relative on Medium, +48% relative on Hard).
OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
Jun 01, 2026Building capable visual web agents requires long-horizon reasoning, precise grounding, and robust interaction with dynamic real-world websites. Despite rapid progress, the strongest systems remain largely proprietary, while open agents still depend heavily on supervised post-training over large collections of curated web trajectories. This dependence creates a major scalability bottleneck: high-quality demonstrations are expensive to collect, and static datasets offer limited coverage of the diverse, ever-changing open web. Although online RL has shown promise for text-based agents, its potential for training visual web agents directly on live websites remains largely underexplored. In this paper, we introduce OpenWebRL, an open framework for training visual web agents with online multi-turn RL on real websites. OpenWebRL covers the full training pipeline, including scalable live-browser infrastructure, supervised initialization, multimodal context management, trajectory-level success judging, and efficient multi-turn policy optimization. Using this framework, we train OpenWebRL-4B, which establishes a new open-source state of the art on challenging live-web benchmarks. With only 0.4K initialization trajectories and 2.2K open-ended RL training tasks, OpenWebRL-4B achieves 67.0% success on Online-Mind2Web and 64.0% on DeepShop, outperforming prior open agents of similar or larger scale and remaining competitive with proprietary systems including OpenAI CUA and Gemini CUA. Beyond strong benchmark performance, we systematically study the key design choices that make online RL effective for visual web agents, and analyze how RL improves agentic reasoning. Overall, our work offers a practical path toward building more capable, reproducible, and cost-efficient open web agents. We will release our training data, models, and code to support future research.
PRO-CUA: Process-Reward Optimization for Computer Use Agents
May 27, 2026Computer use agents (CUAs) have shown strong potential for automating complex digital workflows, yet their training remains constrained by costly live environment interaction and limited high-quality supervision. Existing filtered behavior cloning pipelines suffer from imitation bottlenecks, including distribution shift from the expert demonstration and the absence of negative learning signals. Meanwhile, standard trajectory-level reinforcement learning struggles with sparse rewards, ambiguous credit assignment, and high infrastructure costs for long-horizon GUI interaction. In this work, we propose PRO-CUA, a process-reward optimization framework for training CUAs with iterative step-level reinforcement learning. PRO-CUA decouples on-policy environment interaction from policy optimization: the current policy collects states through live rollouts, generates diverse candidate actions for each state, receives step-level feedback from a process reward model (PRM), and is optimized with group-relative advantages. This design enables dense and flexible credit assignment without relying on golden answers or offline expert trajectories, while reducing distribution shift by training on the agent's own execution states. Experiments on live web benchmarks demonstrate the effectiveness of PRO-CUA and the reliability of PRM-guided step-level training.
InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
Jan 20, 2026Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
Jan 07, 2026We present WebGym, the largest-to-date open-source environment for training realistic visual web agents. Real websites are non-stationary and diverse, making artificial or small-scale task sets insufficient for robust policy learning. WebGym contains nearly 300,000 tasks with rubric-based evaluations across diverse, real-world websites and difficulty levels. We train agents with a simple reinforcement learning (RL) recipe, which trains on the agent's own interaction traces (rollouts), using task rewards as feedback to guide learning. To enable scaling RL, we speed up sampling of trajectories in WebGym by developing a high-throughput asynchronous rollout system, designed specifically for web agents. Our system achieves a 4-5x rollout speedup compared to naive implementations. Second, we scale the task set breadth, depth, and size, which results in continued performance improvement. Fine-tuning a strong base vision-language model, Qwen-3-VL-8B-Instruct, on WebGym results in an improvement in success rate on an out-of-distribution test set from 26.2% to 42.9%, significantly outperforming agents based on proprietary models such as GPT-4o and GPT-5-Thinking that achieve 27.1% and 29.8%, respectively. This improvement is substantial because our test set consists only of tasks on websites never seen during training, unlike many other prior works on training visual web agents.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025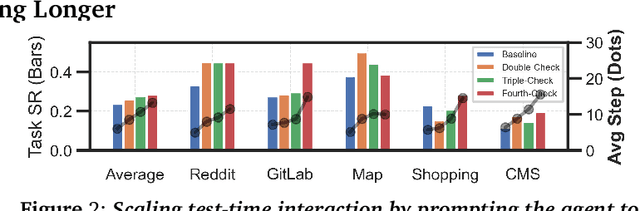
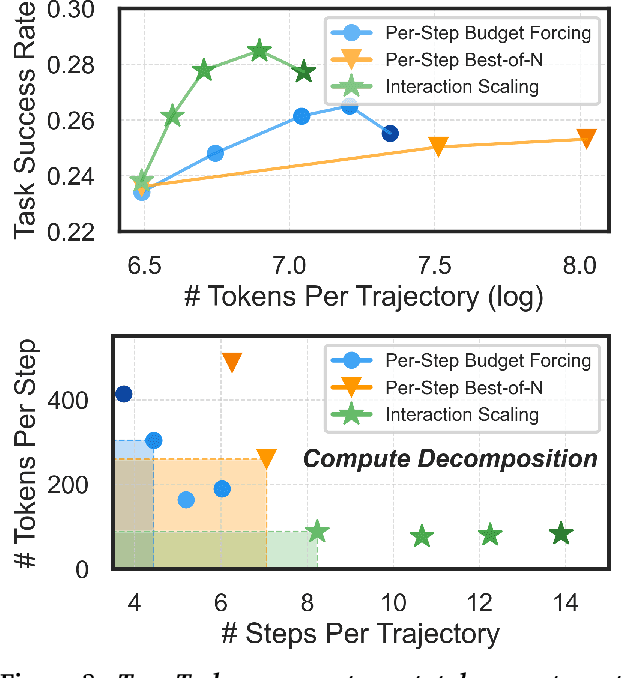
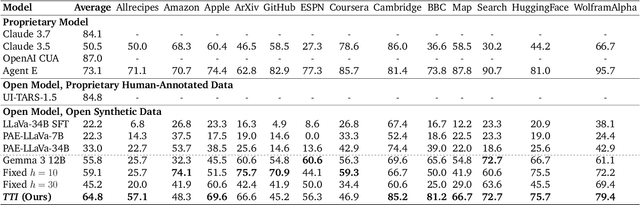
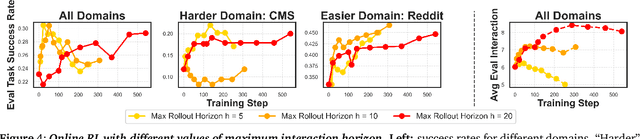
The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
Improving Neuron-level Interpretability with White-box Language Models
Oct 21, 2024Neurons in auto-regressive language models like GPT-2 can be interpreted by analyzing their activation patterns. Recent studies have shown that techniques such as dictionary learning, a form of post-hoc sparse coding, enhance this neuron-level interpretability. In our research, we are driven by the goal to fundamentally improve neural network interpretability by embedding sparse coding directly within the model architecture, rather than applying it as an afterthought. In our study, we introduce a white-box transformer-like architecture named Coding RAte TransformEr (CRATE), explicitly engineered to capture sparse, low-dimensional structures within data distributions. Our comprehensive experiments showcase significant improvements (up to 103% relative improvement) in neuron-level interpretability across a variety of evaluation metrics. Detailed investigations confirm that this enhanced interpretability is steady across different layers irrespective of the model size, underlining CRATE's robust performance in enhancing neural network interpretability. Further analysis shows that CRATE's increased interpretability comes from its enhanced ability to consistently and distinctively activate on relevant tokens. These findings point towards a promising direction for creating white-box foundation models that excel in neuron-level interpretation.
NODER: Image Sequence Regression Based on Neural Ordinary Differential Equations
Jul 18, 2024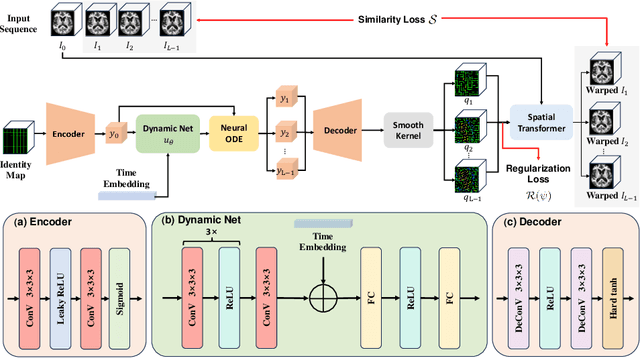



Regression on medical image sequences can capture temporal image pattern changes and predict images at missing or future time points. However, existing geodesic regression methods limit their regression performance by a strong underlying assumption of linear dynamics, while diffusion-based methods have high computational costs and lack constraints to preserve image topology. In this paper, we propose an optimization-based new framework called NODER, which leverages neural ordinary differential equations to capture complex underlying dynamics and reduces its high computational cost of handling high-dimensional image volumes by introducing the latent space. We compare our NODER with two recent regression methods, and the experimental results on ADNI and ACDC datasets demonstrate that our method achieves the state-of-the-art performance in 3D image regression. Our model needs only a couple of images in a sequence for prediction, which is practical, especially for clinical situations where extremely limited image time series are available for analysis. Our source code is available at https://github.com/ZedKing12138/NODER-pytorch.
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning
Jun 14, 2024Training corpuses for vision language models (VLMs) typically lack sufficient amounts of decision-centric data. This renders off-the-shelf VLMs sub-optimal for decision-making tasks such as in-the-wild device control through graphical user interfaces (GUIs). While training with static demonstrations has shown some promise, we show that such methods fall short for controlling real GUIs due to their failure to deal with real-world stochasticity and non-stationarity not captured in static observational data. This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline RL to initialize the model, followed by offline-to-online RL. To do this, we build a scalable and parallelizable Android learning environment equipped with a VLM-based evaluator and develop a simple yet effective RL approach for learning in this domain. Our approach runs advantage-weighted RL with advantage estimators enhanced to account for stochasticity along with an automatic curriculum for deriving maximal learning signal. We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.3B VLM trained with RL achieves a 49.5% absolute improvement -- from 17.7 to 67.2% success rate -- over supervised fine-tuning with static human demonstration data. These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3% success rate) and the 17B CogAgent trained with AitW data (38.5%), but also the prior best autonomous RL approach based on filtered behavior cloning (57.8%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.