 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
Jun 04, 2026In real-world applications, models are expected to perform reliably across diverse settings. Yet, many existing multimodal benchmarks expand task types without capturing the visual diversity needed to handle open-ended visual inputs. We present WorldBench, a challenging and visually diverse reasoning benchmark to evaluate Multimodal Large Language Models (MLLMs). We build a taxonomy of thousands of visual concepts across multiple domains (e.g., living things). Guided by this taxonomy, we curate a broad collection of images from search engines and existing datasets to comprehensively represent the visual world. Through structured trial-and-error, we manually design challenging questions that frontier MLLMs fail to answer. On quantitative and human evaluations, WorldBench achieves higher visual diversity than any existing diverse benchmark. Evaluating 15 MLLMs on WorldBench reveals weaknesses in visual understanding: even the strongest model reaches only 64.0% accuracy, while some models perform marginally above chance-level. We hope our work highlights the importance of visual diversity in building multimodal benchmarks.
VisionFoundry: Teaching VLMs Visual Perception with Synthetic Images
Apr 10, 2026Vision-language models (VLMs) still struggle with visual perception tasks such as spatial understanding and viewpoint recognition. One plausible contributing factor is that natural image datasets provide limited supervision for low-level visual skills. This motivates a practical question: can targeted synthetic supervision, generated from only a task keyword such as Depth Order, address these weaknesses? To investigate this question, we introduce VisionFoundry, a task-aware synthetic data generation pipeline that takes only the task name as input and uses large language models (LLMs) to generate questions, answers, and text-to-image (T2I) prompts, then synthesizes images with T2I models and verifies consistency with a proprietary VLM, requiring no reference images or human annotation. Using VisionFoundry, we construct VisionFoundry-10K, a synthetic visual question answering (VQA) dataset containing 10k image-question-answer triples spanning 10 tasks. Models trained on VisionFoundry-10K achieve substantial improvements on visual perception benchmarks: +7% on MMVP and +10% on CV-Bench-3D, while preserving broader capabilities and showing favorable scaling behavior as data size increases. Our results suggest that limited task-targeted supervision is an important contributor to this bottleneck and that synthetic supervision is a promising path toward more systematic training for VLMs.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
Asymmetric Idiosyncrasies in Multimodal Models
Feb 26, 2026In this work, we study idiosyncrasies in the caption models and their downstream impact on text-to-image models. We design a systematic analysis: given either a generated caption or the corresponding image, we train neural networks to predict the originating caption model. Our results show that text classification yields very high accuracy (99.70\%), indicating that captioning models embed distinctive stylistic signatures. In contrast, these signatures largely disappear in the generated images, with classification accuracy dropping to at most 50\% even for the state-of-the-art Flux model. To better understand this cross-modal discrepancy, we further analyze the data and find that the generated images fail to preserve key variations present in captions, such as differences in the level of detail, emphasis on color and texture, and the distribution of objects within a scene. Overall, our classification-based framework provides a novel methodology for quantifying both the stylistic idiosyncrasies of caption models and the prompt-following ability of text-to-image systems.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
Cambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
From Intention to Execution: Probing the Generalization Boundaries of Vision-Language-Action Models
Jun 11, 2025One promise that Vision-Language-Action (VLA) models hold over traditional imitation learning for robotics is to leverage the broad generalization capabilities of large Vision-Language Models (VLMs) to produce versatile, "generalist" robot policies. However, current evaluations of VLAs remain insufficient. Traditional imitation learning benchmarks are unsuitable due to the lack of language instructions. Emerging benchmarks for VLAs that incorporate language often come with limited evaluation tasks and do not intend to investigate how much VLM pretraining truly contributes to the generalization capabilities of the downstream robotic policy. Meanwhile, much research relies on real-world robot setups designed in isolation by different institutions, which creates a barrier for reproducibility and accessibility. To address this gap, we introduce a unified probing suite of 50 simulation-based tasks across 10 subcategories spanning language instruction, vision, and objects. We systematically evaluate several state-of-the-art VLA architectures on this suite to understand their generalization capability. Our results show that while VLM backbones endow VLAs with robust perceptual understanding and high level planning, which we refer to as good intentions, this does not reliably translate into precise motor execution: when faced with out-of-distribution observations, policies often exhibit coherent intentions, but falter in action execution. Moreover, finetuning on action data can erode the original VLM's generalist reasoning abilities. We release our task suite and evaluation code to serve as a standardized benchmark for future VLAs and to drive research on closing the perception-to-action gap. More information, including the source code, can be found at https://ai4ce.github.io/INT-ACT/
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025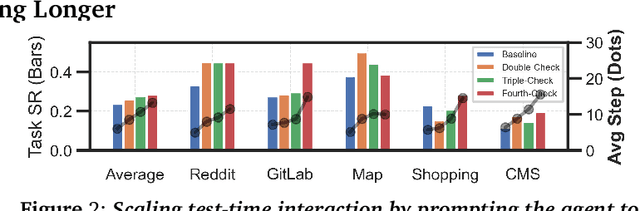
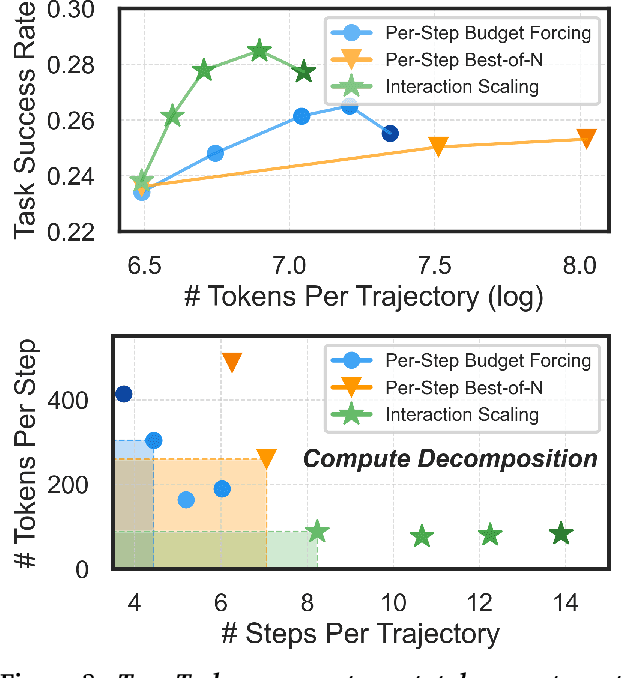
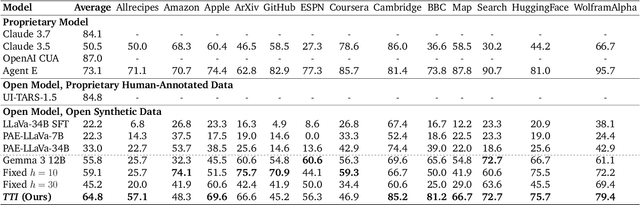
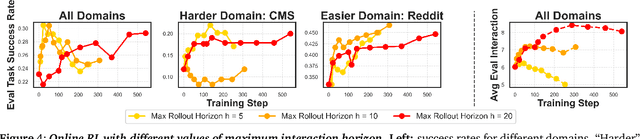
The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.