 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexHoldem: Playing Texas Hold'em with Dexterous Embodied System
May 18, 2026Evaluating embodied systems on real dexterous hardware requires more than isolated primitive skills: an agent must perceive a changing tabletop scene, choose a context-appropriate action, execute it with a dexterous hand, and leave the scene usable for later decisions. We introduce DexHoldem, a real-world system-level benchmark built around Texas Hold'em dexterous manipulation with a ShadowHand. DexHoldem provides 1,470 teleoperated demonstrations across 14 Texas Hold'em manipulation primitives, a standardized physical policy benchmark, and an agentic perception benchmark that tests whether agents can recover the structured game state needed for embodied decision making. On primitive execution, $π_{0.5}$ obtains the highest task completion rate ($61.2\%$), while $π_{0.5}$ and $π_0$ tie on scene-preserving success rate ($47.5\%$). On agentic perception, Opus 4.7 obtains the best strict problem-level accuracy ($34.3\%$), while GPT 5.5 obtains the best average field-wise accuracy ($66.8\%$), exposing a gap between isolated visual sub-capabilities and complete routing-relevant state recovery. Finally, we instantiate the full embodied-agent loop in three case studies, where waiting, recovery dispatches, human-help requests, and repeated primitive execution reveal how perception and policy errors accumulate during closed-loop deployment. DexHoldem therefore evaluates dexterous tabletop execution, agentic perception, and embodied decision routing in a shared physical setting. Project page: https://dexholdem.github.io/Dexholdem/.
Pointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection
Mar 04, 2026Constructing computer-aided design (CAD) models is labor-intensive but essential for engineering and manufacturing. Recent advances in Large Language Models (LLMs) have inspired the LLM-based CAD generation by representing CAD as command sequences. But these methods struggle in practical scenarios because command sequence representation does not support entity selection (e.g. faces or edges), limiting its ability to support complex editing operations such as chamfer or fillet. Further, the discretization of a continuous variable during sketch and extrude operations may result in topological errors. To address these limitations, we present Pointer-CAD, a novel LLM-based CAD generation framework that leverages a pointer-based command sequence representation to explicitly incorporate the geometric information of B-rep models into sequential modeling. In particular, Pointer-CAD decomposes CAD model generation into steps, conditioning the generation of each subsequent step on both the textual description and the B-rep generated from previous steps. Whenever an operation requires the selection of a specific geometric entity, the LLM predicts a Pointer that selects the most feature-consistent candidate from the available set. Such a selection operation also reduces the quantization error in the command sequence-based representation. To support the training of Pointer-CAD, we develop a data annotation pipeline that produces expert-level natural language descriptions and apply it to build a dataset of approximately 575K CAD models. Extensive experimental results demonstrate that Pointer-CAD effectively supports the generation of complex geometric structures and reduces segmentation error to an extremely low level, achieving a significant improvement over prior command sequence methods, thereby significantly mitigating the topological inaccuracies introduced by quantization error.
Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
Apr 21, 2025



Multi-view understanding, the ability to reconcile visual information across diverse viewpoints for effective navigation, manipulation, and 3D scene comprehension, is a fundamental challenge in Multi-Modal Large Language Models (MLLMs) to be used as embodied agents. While recent MLLMs have shown impressive advances in high-level reasoning and planning, they frequently fall short when confronted with multi-view geometric consistency and cross-view correspondence. To comprehensively evaluate the challenges of MLLMs in multi-view scene reasoning, we propose All-Angles Bench, a benchmark of over 2,100 human carefully annotated multi-view question-answer pairs across 90 diverse real-world scenes. Our six tasks (counting, attribute identification, relative distance, relative direction, object manipulation, and camera pose estimation) specifically test model's geometric correspondence and the capacity to align information consistently across views. Our extensive experiments, benchmark on 27 representative MLLMs including Gemini-2.0-Flash, Claude-3.7-Sonnet, and GPT-4o against human evaluators reveals a substantial performance gap, indicating that current MLLMs remain far from human-level proficiency. Through in-depth analysis, we show that MLLMs are particularly underperforming under two aspects: (1) cross-view correspondence for partially occluded views and (2) establishing the coarse camera poses. These findings highlight the necessity of domain-specific refinements or modules that embed stronger multi-view awareness. We believe that our All-Angles Bench offers valuable insights and contribute to bridging the gap between MLLMs and human-level multi-view understanding. The project and benchmark are publicly available at https://danielchyeh.github.io/All-Angles-Bench/.
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Jan 28, 2025



Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Nov 24, 2023



In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
Emergence of Segmentation with Minimalistic White-Box Transformers
Aug 30, 2023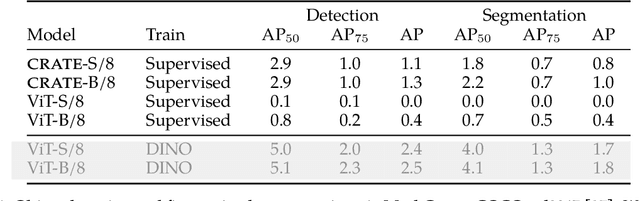
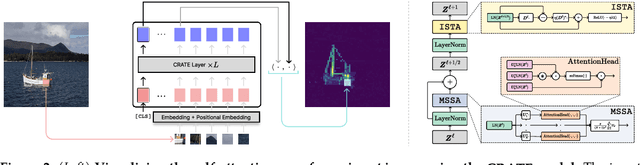
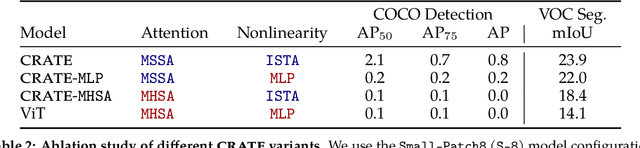

Transformer-like models for vision tasks have recently proven effective for a wide range of downstream applications such as segmentation and detection. Previous works have shown that segmentation properties emerge in vision transformers (ViTs) trained using self-supervised methods such as DINO, but not in those trained on supervised classification tasks. In this study, we probe whether segmentation emerges in transformer-based models solely as a result of intricate self-supervised learning mechanisms, or if the same emergence can be achieved under much broader conditions through proper design of the model architecture. Through extensive experimental results, we demonstrate that when employing a white-box transformer-like architecture known as CRATE, whose design explicitly models and pursues low-dimensional structures in the data distribution, segmentation properties, at both the whole and parts levels, already emerge with a minimalistic supervised training recipe. Layer-wise finer-grained analysis reveals that the emergent properties strongly corroborate the designed mathematical functions of the white-box network. Our results suggest a path to design white-box foundation models that are simultaneously highly performant and mathematically fully interpretable. Code is at \url{https://github.com/Ma-Lab-Berkeley/CRATE}.
Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models
Jun 09, 2023



The advent of large pre-trained models has brought about a paradigm shift in both visual representation learning and natural language processing. However, clustering unlabeled images, as a fundamental and classic machine learning problem, still lacks effective solution, particularly for large-scale datasets. In this paper, we propose a novel image clustering pipeline that leverages the powerful feature representation of large pre-trained models such as CLIP and cluster images effectively and efficiently at scale. We show that the pre-trained features are significantly more structured by further optimizing the rate reduction objective. The resulting features may significantly improve the clustering accuracy, e.g., from 57\% to 66\% on ImageNet-1k. Furthermore, by leveraging CLIP's image-text binding, we show how the new clustering method leads to a simple yet effective self-labeling algorithm that successfully works on unlabeled large datasets such as MS-COCO and LAION-Aesthetics. We will release the code in https://github.com/LeslieTrue/CPP.
White-Box Transformers via Sparse Rate Reduction
Jun 01, 2023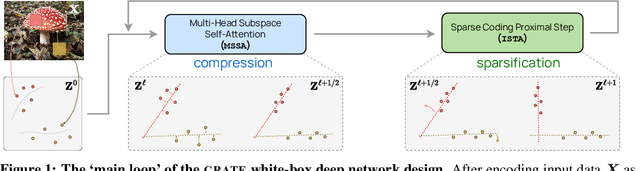
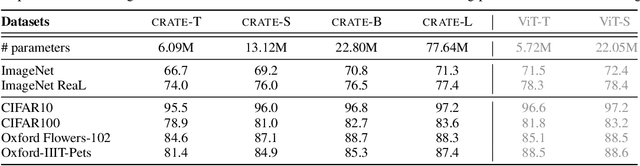
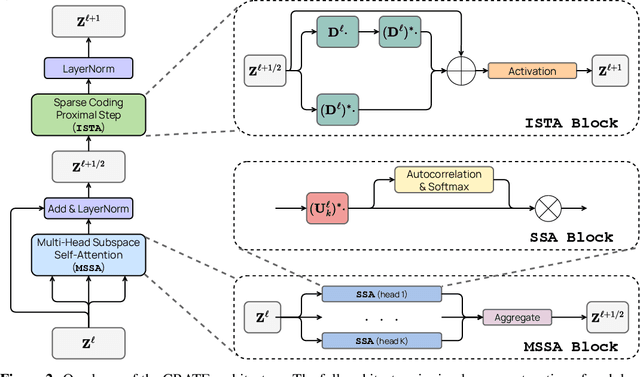
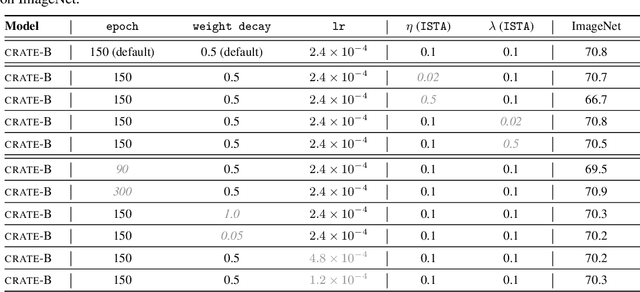
In this paper, we contend that the objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a mixture of low-dimensional Gaussian distributions supported on incoherent subspaces. The quality of the final representation can be measured by a unified objective function called sparse rate reduction. From this perspective, popular deep networks such as transformers can be naturally viewed as realizing iterative schemes to optimize this objective incrementally. Particularly, we show that the standard transformer block can be derived from alternating optimization on complementary parts of this objective: the multi-head self-attention operator can be viewed as a gradient descent step to compress the token sets by minimizing their lossy coding rate, and the subsequent multi-layer perceptron can be viewed as attempting to sparsify the representation of the tokens. This leads to a family of white-box transformer-like deep network architectures which are mathematically fully interpretable. Despite their simplicity, experiments show that these networks indeed learn to optimize the designed objective: they compress and sparsify representations of large-scale real-world vision datasets such as ImageNet, and achieve performance very close to thoroughly engineered transformers such as ViT. Code is at \url{https://github.com/Ma-Lab-Berkeley/CRATE}.