 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrinciples and Practice of Deep Representation Learning: or a Mathematical Theory of Memory
Jun 04, 2026In the current era of deep learning and especially generative models, there is significant investment in training very large generative models. Thus far, such models have been "black boxes" that are difficult to understand in the sense that they have opaque internal mechanisms, leading to difficulties in interpretability, reliability, and control. Naturally, this lack of understanding has led to both hype and fear. This book is an attempt to "open the black box" and understand the mechanisms of large deep networks, through the perspective of representation learning, which is a major factor - arguably the single most important one - in the empirical power of deep learning models. A brief outline of this book is as follows. Chapter 1 will summarize the threads that underlie the whole text. Chapters 2, 3, 4, 5, and 6 will explain the design principles of modern neural network architectures through optimization and information theory, reducing the process of architecture development (long having been described as a sort of "alchemy") to undergraduate-level linear algebra and calculus exercises once the underlying principles are introduced. Chapters 7 and 8 will discuss applications of these principles to solve problems in more paradigmatic ways, obtaining new methods and models which are efficient, interpretable, and controllable by design, and yet no less - sometimes even more - powerful than the black-box models they resemble. Chapter 9 will discuss potential future directions for deep learning, the role of representation learning, as well as some open problems.
On the Edge of Memorization in Diffusion Models
Aug 25, 2025When do diffusion models reproduce their training data, and when are they able to generate samples beyond it? A practically relevant theoretical understanding of this interplay between memorization and generalization may significantly impact real-world deployments of diffusion models with respect to issues such as copyright infringement and data privacy. In this work, to disentangle the different factors that influence memorization and generalization in practical diffusion models, we introduce a scientific and mathematical "laboratory" for investigating these phenomena in diffusion models trained on fully synthetic or natural image-like structured data. Within this setting, we hypothesize that the memorization or generalization behavior of an underparameterized trained model is determined by the difference in training loss between an associated memorizing model and a generalizing model. To probe this hypothesis, we theoretically characterize a crossover point wherein the weighted training loss of a fully generalizing model becomes greater than that of an underparameterized memorizing model at a critical value of model (under)parameterization. We then demonstrate via carefully-designed experiments that the location of this crossover predicts a phase transition in diffusion models trained via gradient descent, validating our hypothesis. Ultimately, our theory enables us to analytically predict the model size at which memorization becomes predominant. Our work provides an analytically tractable and practically meaningful setting for future theoretical and empirical investigations. Code for our experiments is available at https://github.com/DruvPai/diffusion_mem_gen.
Attention-Only Transformers via Unrolled Subspace Denoising
Jun 04, 2025Despite the popularity of transformers in practice, their architectures are empirically designed and neither mathematically justified nor interpretable. Moreover, as indicated by many empirical studies, some components of transformer architectures may be redundant. To derive a fully interpretable transformer architecture with only necessary components, we contend that the goal of representation learning is to compress a set of noisy initial token representations towards a mixture of low-dimensional subspaces. To compress these noisy token representations, an associated denoising operation naturally takes the form of a multi-head (subspace) self-attention. By unrolling such iterative denoising operations into a deep network, we arrive at a highly compact architecture that consists of \textit{only} self-attention operators with skip connections at each layer. Moreover, we show that each layer performs highly efficient denoising: it improves the signal-to-noise ratio of token representations \textit{at a linear rate} with respect to the number of layers. Despite its simplicity, extensive experiments on vision and language tasks demonstrate that such a transformer achieves performance close to that of standard transformer architectures such as GPT-2 and CRATE.
Token Statistics Transformer: Linear-Time Attention via Variational Rate Reduction
Dec 23, 2024



The attention operator is arguably the key distinguishing factor of transformer architectures, which have demonstrated state-of-the-art performance on a variety of tasks. However, transformer attention operators often impose a significant computational burden, with the computational complexity scaling quadratically with the number of tokens. In this work, we propose a novel transformer attention operator whose computational complexity scales linearly with the number of tokens. We derive our network architecture by extending prior work which has shown that a transformer style architecture naturally arises by "white-box" architecture design, where each layer of the network is designed to implement an incremental optimization step of a maximal coding rate reduction objective (MCR$^2$). Specifically, we derive a novel variational form of the MCR$^2$ objective and show that the architecture that results from unrolled gradient descent of this variational objective leads to a new attention module called Token Statistics Self-Attention (TSSA). TSSA has linear computational and memory complexity and radically departs from the typical attention architecture that computes pairwise similarities between tokens. Experiments on vision, language, and long sequence tasks show that simply swapping TSSA for standard self-attention, which we refer to as the Token Statistics Transformer (ToST), achieves competitive performance with conventional transformers while being significantly more computationally efficient and interpretable. Our results also somewhat call into question the conventional wisdom that pairwise similarity style attention mechanisms are critical to the success of transformer architectures. Code will be available at https://github.com/RobinWu218/ToST.
Active-Dormant Attention Heads: Mechanistically Demystifying Extreme-Token Phenomena in LLMs
Oct 17, 2024



Practitioners have consistently observed three puzzling phenomena in transformer-based large language models (LLMs): attention sinks, value-state drains, and residual-state peaks, collectively referred to as extreme-token phenomena. These phenomena are characterized by certain so-called "sink tokens" receiving disproportionately high attention weights, exhibiting significantly smaller value states, and having much larger residual-state norms than those of other tokens. These extreme tokens give rise to various challenges in LLM inference, quantization, and interpretability. We elucidate the mechanisms behind extreme-token phenomena. First, we show that these phenomena arise in very simple architectures -- transformers with one to three layers -- trained on a toy model, the Bigram-Backcopy (BB) task. In this setting, we identify an active-dormant mechanism, where attention heads become sinks for specific input domains while remaining non-sinks for others. Our theoretical analysis of the training dynamics reveals that these phenomena are driven by a mutual reinforcement mechanism. Building on these insights, we propose strategies to mitigate extreme-token phenomena during pretraining, including replacing softmax with ReLU and Adam with SGD. Next, we extend our analysis to pretrained LLMs, including Llama and OLMo, showing that many attention heads exhibit a similar active-dormant mechanism as in the BB task, and that the mutual reinforcement mechanism also governs the emergence of extreme-token phenomena during LLM pretraining. Our results reveal that many of the static and dynamic properties of extreme-token phenomena predicted by the BB task align with observations in pretrained LLMs.
A Global Geometric Analysis of Maximal Coding Rate Reduction
Jun 04, 2024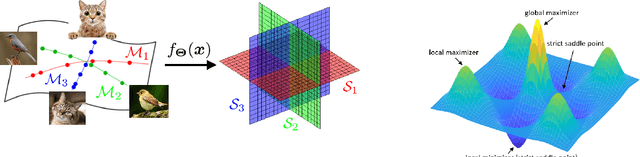
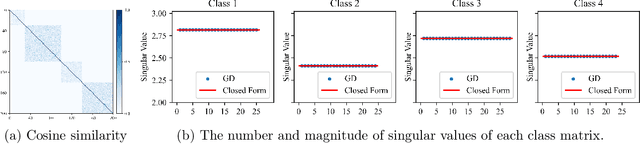
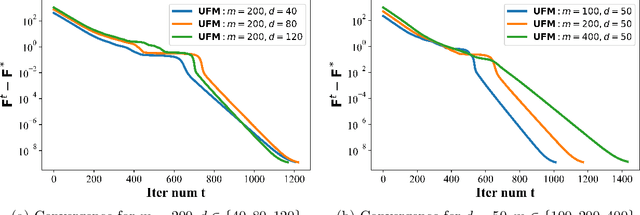
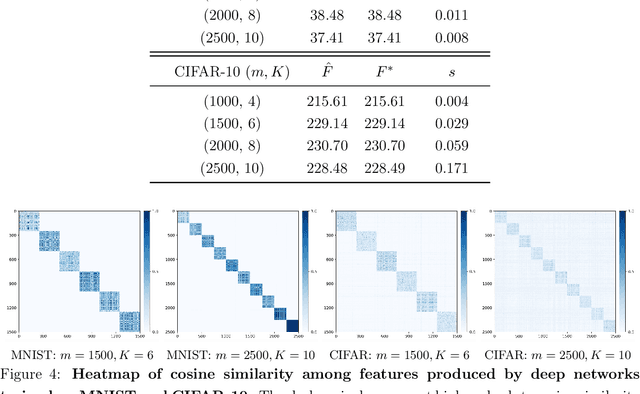
The maximal coding rate reduction (MCR$^2$) objective for learning structured and compact deep representations is drawing increasing attention, especially after its recent usage in the derivation of fully explainable and highly effective deep network architectures. However, it lacks a complete theoretical justification: only the properties of its global optima are known, and its global landscape has not been studied. In this work, we give a complete characterization of the properties of all its local and global optima, as well as other types of critical points. Specifically, we show that each (local or global) maximizer of the MCR$^2$ problem corresponds to a low-dimensional, discriminative, and diverse representation, and furthermore, each critical point of the objective is either a local maximizer or a strict saddle point. Such a favorable landscape makes MCR$^2$ a natural choice of objective for learning diverse and discriminative representations via first-order optimization methods. To validate our theoretical findings, we conduct extensive experiments on both synthetic and real data sets.
Scaling White-Box Transformers for Vision
Jun 03, 2024



CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$\alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$\alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$\alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$\alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$\alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
Masked Completion via Structured Diffusion with White-Box Transformers
Apr 03, 2024Modern learning frameworks often train deep neural networks with massive amounts of unlabeled data to learn representations by solving simple pretext tasks, then use the representations as foundations for downstream tasks. These networks are empirically designed; as such, they are usually not interpretable, their representations are not structured, and their designs are potentially redundant. White-box deep networks, in which each layer explicitly identifies and transforms structures in the data, present a promising alternative. However, existing white-box architectures have only been shown to work at scale in supervised settings with labeled data, such as classification. In this work, we provide the first instantiation of the white-box design paradigm that can be applied to large-scale unsupervised representation learning. We do this by exploiting a fundamental connection between diffusion, compression, and (masked) completion, deriving a deep transformer-like masked autoencoder architecture, called CRATE-MAE, in which the role of each layer is mathematically fully interpretable: they transform the data distribution to and from a structured representation. Extensive empirical evaluations confirm our analytical insights. CRATE-MAE demonstrates highly promising performance on large-scale imagery datasets while using only ~30% of the parameters compared to the standard masked autoencoder with the same model configuration. The representations learned by CRATE-MAE have explicit structure and also contain semantic meaning. Code is available at https://github.com/Ma-Lab-Berkeley/CRATE .
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Nov 24, 2023



In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
Emergence of Segmentation with Minimalistic White-Box Transformers
Aug 30, 2023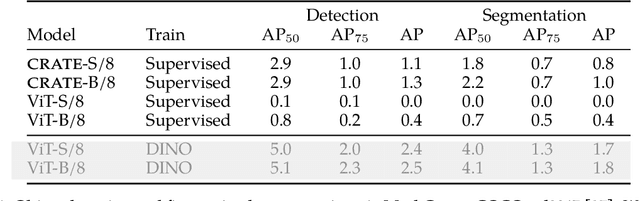
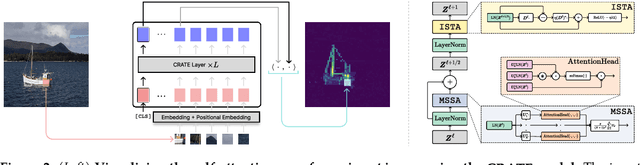
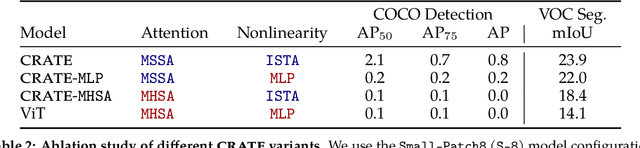

Transformer-like models for vision tasks have recently proven effective for a wide range of downstream applications such as segmentation and detection. Previous works have shown that segmentation properties emerge in vision transformers (ViTs) trained using self-supervised methods such as DINO, but not in those trained on supervised classification tasks. In this study, we probe whether segmentation emerges in transformer-based models solely as a result of intricate self-supervised learning mechanisms, or if the same emergence can be achieved under much broader conditions through proper design of the model architecture. Through extensive experimental results, we demonstrate that when employing a white-box transformer-like architecture known as CRATE, whose design explicitly models and pursues low-dimensional structures in the data distribution, segmentation properties, at both the whole and parts levels, already emerge with a minimalistic supervised training recipe. Layer-wise finer-grained analysis reveals that the emergent properties strongly corroborate the designed mathematical functions of the white-box network. Our results suggest a path to design white-box foundation models that are simultaneously highly performant and mathematically fully interpretable. Code is at \url{https://github.com/Ma-Lab-Berkeley/CRATE}.