 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025
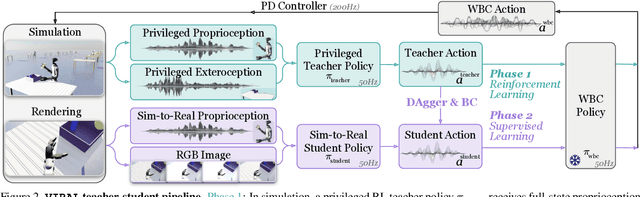
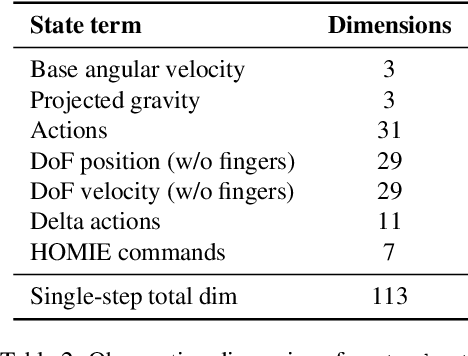

A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
Evader-Agnostic Team-Based Pursuit Strategies in Partially-Observable Environments
Nov 08, 2025We consider a scenario where a team of two unmanned aerial vehicles (UAVs) pursue an evader UAV within an urban environment. Each agent has a limited view of their environment where buildings can occlude their field-of-view. Additionally, the pursuer team is agnostic about the evader in terms of its initial and final location, and the behavior of the evader. Consequently, the team needs to gather information by searching the environment and then track it to eventually intercept. To solve this multi-player, partially-observable, pursuit-evasion game, we develop a two-phase neuro-symbolic algorithm centered around the principle of bounded rationality. First, we devise an offline approach using deep reinforcement learning to progressively train adversarial policies for the pursuer team against fictitious evaders. This creates $k$-levels of rationality for each agent in preparation for the online phase. Then, we employ an online classification algorithm to determine a "best guess" of our current opponent from the set of iteratively-trained strategic agents and apply the best player response. Using this schema, we improved average performance when facing a random evader in our environment.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
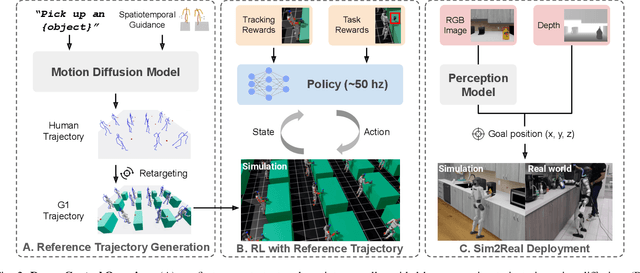

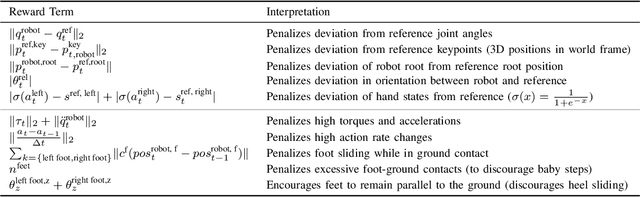
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025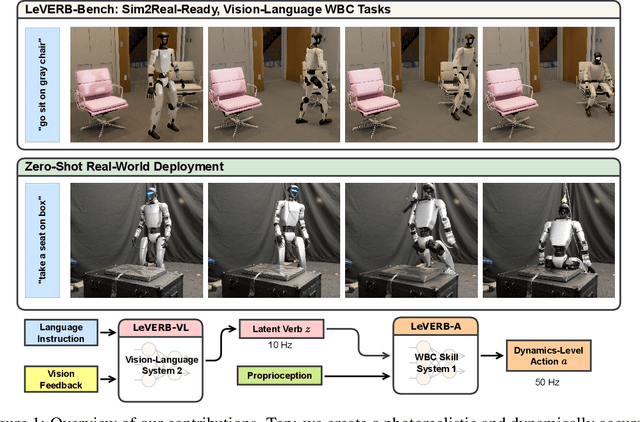
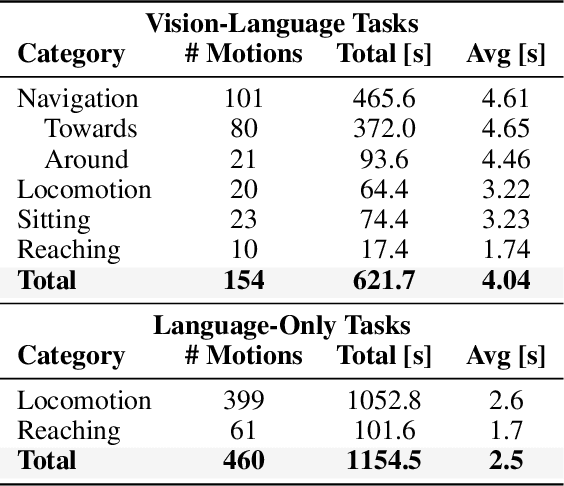
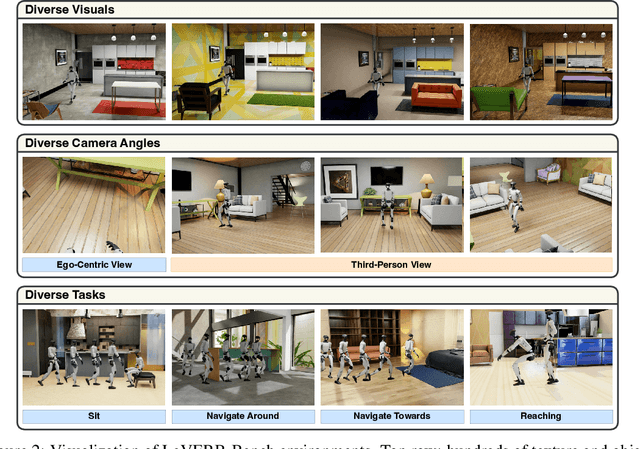
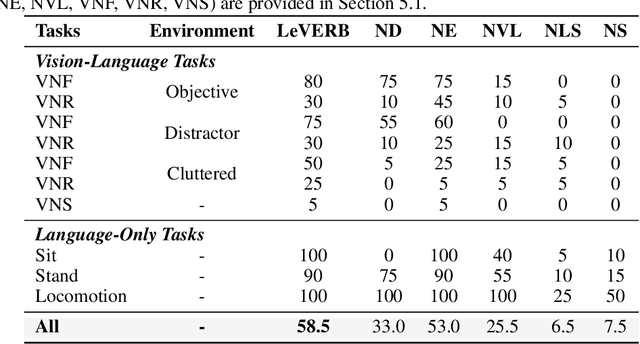
Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
LATTE-MV: Learning to Anticipate Table Tennis Hits from Monocular Videos
Mar 26, 2025Physical agility is a necessary skill in competitive table tennis, but by no means sufficient. Champions excel in this fast-paced and highly dynamic environment by anticipating their opponent's intent - buying themselves the necessary time to react. In this work, we take one step towards designing such an anticipatory agent. Previous works have developed systems capable of real-time table tennis gameplay, though they often do not leverage anticipation. Among the works that forecast opponent actions, their approaches are limited by dataset size and variety. Our paper contributes (1) a scalable system for reconstructing monocular video of table tennis matches in 3D and (2) an uncertainty-aware controller that anticipates opponent actions. We demonstrate in simulation that our policy improves the ball return rate against high-speed hits from 49.9% to 59.0% as compared to a baseline non-anticipatory policy.
Real-Time Algorithms for Game-Theoretic Motion Planning and Control in Autonomous Racing using Near-Potential Function
Dec 12, 2024Autonomous racing extends beyond the challenge of controlling a racecar at its physical limits. Professional racers employ strategic maneuvers to outwit other competing opponents to secure victory. While modern control algorithms can achieve human-level performance by computing offline racing lines for single-car scenarios, research on real-time algorithms for multi-car autonomous racing is limited. To bridge this gap, we develop game-theoretic modeling framework that incorporates the competitive aspect of autonomous racing like overtaking and blocking through a novel policy parametrization, while operating the car at its limit. Furthermore, we propose an algorithmic approach to compute the (approximate) Nash equilibrium strategy, which represents the optimal approach in the presence of competing agents. Specifically, we introduce an algorithm inspired by recently introduced framework of dynamic near-potential function, enabling real-time computation of the Nash equilibrium. Our approach comprises two phases: offline and online. During the offline phase, we use simulated racing data to learn a near-potential function that approximates utility changes for agents. This function facilitates the online computation of approximate Nash equilibria by maximizing its value. We evaluate our method in a head-to-head 3-car racing scenario, demonstrating superior performance compared to several existing baselines.
Decentralized Learning in General-sum Markov Games
Sep 06, 2024The Markov game framework is widely used to model interactions among agents with heterogeneous utilities in dynamic and uncertain societal-scale systems. In these systems, agents typically operate in a decentralized manner due to privacy and scalability concerns, often acting without any information about other agents. The design and analysis of decentralized learning algorithms that provably converge to rational outcomes remain elusive, especially beyond Markov zero-sum games and Markov potential games, which do not adequately capture the nature of many real-world interactions that is neither fully competitive nor fully cooperative. This paper investigates the design of decentralized learning algorithms for general-sum Markov games, aiming to provide provable guarantees of convergence to approximate Nash equilibria in the long run. Our approach builds on constructing a Markov Near-Potential Function (MNPF) to address the intractability of designing algorithms that converge to exact Nash equilibria. We demonstrate that MNPFs play a central role in ensuring the convergence of an actor-critic-based decentralized learning algorithm to approximate Nash equilibria. By leveraging a two-timescale approach, where Q-function estimates are updated faster than policy updates, we show that the system converges to a level set of the MNPF over the set of approximate Nash equilibria. This convergence result is further strengthened if the set of Nash equilibria is assumed to be finite. Our findings provide a new perspective on the analysis and design of decentralized learning algorithms in multi-agent systems.
Hacking Predictors Means Hacking Cars: Using Sensitivity Analysis to Identify Trajectory Prediction Vulnerabilities for Autonomous Driving Security
Jan 18, 2024Adversarial attacks on learning-based trajectory predictors have already been demonstrated. However, there are still open questions about the effects of perturbations on trajectory predictor inputs other than state histories, and how these attacks impact downstream planning and control. In this paper, we conduct a sensitivity analysis on two trajectory prediction models, Trajectron++ and AgentFormer. We observe that between all inputs, almost all of the perturbation sensitivities for Trajectron++ lie only within the most recent state history time point, while perturbation sensitivities for AgentFormer are spread across state histories over time. We additionally demonstrate that, despite dominant sensitivity on state history perturbations, an undetectable image map perturbation made with the Fast Gradient Sign Method can induce large prediction error increases in both models. Even though image maps may contribute slightly to the prediction output of both models, this result reveals that rather than being robust to adversarial image perturbations, trajectory predictors are susceptible to image attacks. Using an optimization-based planner and example perturbations crafted from sensitivity results, we show how this vulnerability can cause a vehicle to come to a sudden stop from moderate driving speeds.
Markov $α$-Potential Games: Equilibrium Approximation and Regret Analysis
May 24, 2023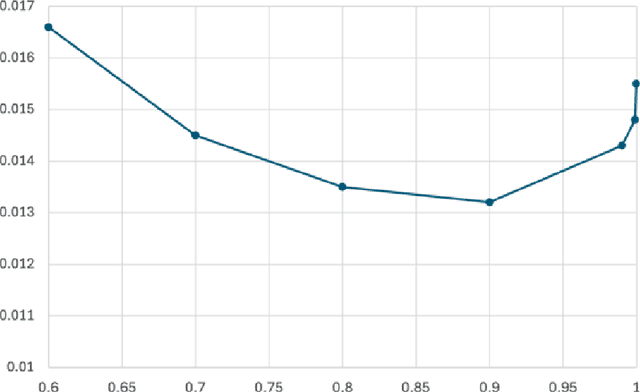
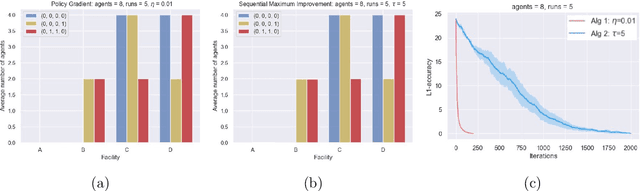
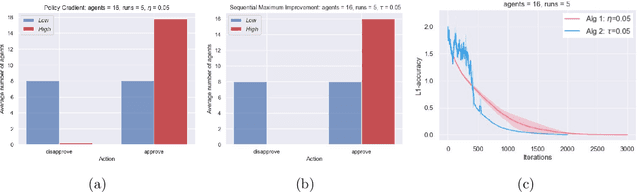
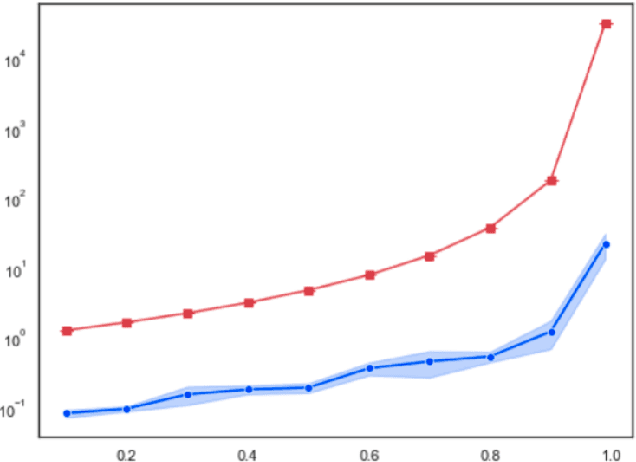
This paper proposes a new framework to study multi-agent interaction in Markov games: Markov $\alpha$-potential games. Markov potential games are special cases of Markov $\alpha$-potential games, so are two important and practically significant classes of games: Markov congestion games and perturbed Markov team games. In this paper, {$\alpha$-potential} functions for both games are provided and the gap $\alpha$ is characterized with respect to game parameters. Two algorithms -- the projected gradient-ascent algorithm and the sequential maximum improvement smoothed best response dynamics -- are introduced for approximating the stationary Nash equilibrium in Markov $\alpha$-potential games. The Nash-regret for each algorithm is shown to scale sub-linearly in time horizon. Our analysis and numerical experiments demonstrates that simple algorithms are capable of finding approximate equilibrium in Markov $\alpha$-potential games.
Representation Learning via Manifold Flattening and Reconstruction
May 12, 2023
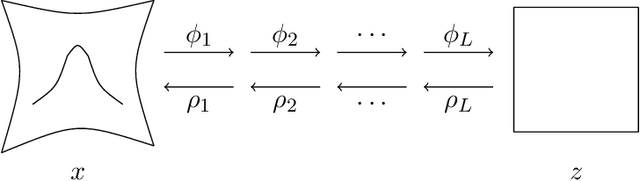


This work proposes an algorithm for explicitly constructing a pair of neural networks that linearize and reconstruct an embedded submanifold, from finite samples of this manifold. Our such-generated neural networks, called Flattening Networks (FlatNet), are theoretically interpretable, computationally feasible at scale, and generalize well to test data, a balance not typically found in manifold-based learning methods. We present empirical results and comparisons to other models on synthetic high-dimensional manifold data and 2D image data. Our code is publicly available.